在普通队列中,元素出队的顺序是由元素入队时间决定的,也就是谁先入队,谁先出队。但是有时候我们希望有这样的一个队列:谁先入队不重要,重要的是谁的“优先级高”,优先级越高越先出队。这样的数据结构我们称之为优先队列(priority queue),其常用于一些特殊应用,比如操作系统控制进程的调度程序。
那么,优先队列该如何实现呢?我们可以很快给出三种解决方案。
1.使用链表,插入操作选择直接插入到表头,时间复杂度为O(1),出队操作则遍历整个表,找到优先级最高者,返回并删除该结点,时间复杂度为O(N)。
2.使用链表,链表中元素按优先级排序,插入操作需为插入结点找到准确位置,时间复杂度为O(N),出队操作则直接返回并删除表头,时间复杂度为O(1)。
3.使用二叉查找树,插入操作时间复杂度为O(logN),出队操作则返回树中最大(或最小,取决于优先级定义)结点并删除,时间复杂度亦为O(logN)。
如果决定使用链表,那么就必须根据插入操作和出队操作的比例,决定用方法1还是方法2。
如果决定使用二叉查找树,实际上有点“杀鸡用牛刀”,因为它支持的操作远不止插入和出队(即删除最大结点或最小结点)。而且一个有N个结点的二叉树有2N个指针域,但只会用掉N-1个(除了根结点,每个结点必有且只有一个指向自身的指针),也就是说必然有N+1个指针域是NULL,即“浪费”掉了。当然,它的时间复杂度比较均衡。
不过今天我们将使用一种新的数据结构来实现优先队列,其同样可以以O(logN)实现插入与出队,而且不需要用到指针,这种数据结构就叫——二叉堆。
在讨论二叉堆之前,我们先决定一下我们对优先级的设定,我们假定元素的优先级为正整数,并且值越小的越优先(这对于我们之后实现二叉堆可以带来一丝方便)。
二叉堆在逻辑结构上就是一棵完全二叉树,而完全二叉树即符合下述条件的二叉树:
1.除去最底层(即深度最大)的结点后,是一棵满二叉树
2.最底层的结点必须在逻辑上“从左至右”逐一填入,不得有空
下图即为一棵完全二叉树
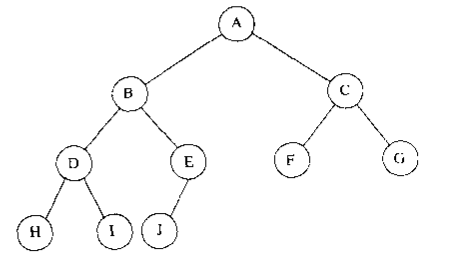
完全二叉树在编程上最大的特点就是它可以使用数组来存储(而且不是靠游标数组),其原理很简单:令根结点存储在下标1处,则其他任一结点的父亲结点均为自身下标i/2(若i为奇数,则商直接取整数部分,这在代码上很简单),任一结点的左孩子下标均为自身下标i*2,右孩子则是i*2+1。
至此,我们确定了两件事:
一,二叉堆就是一棵完全二叉树。
二,完全二叉树可以用数组存储,即二叉堆可以用数组存储。
我们现在已经实现了说好的“不用指针”,接下来的问题就是如何满足优先队列的需求,并且令插入与删除操作均满足O(logN)。在那之前,我们先假定好结点结构并给出二叉堆的存储结构,初始化程序:
//二叉堆结构定义 struct BinaryHeap { unsigned int capacity; //capacity表示二叉堆的最大容量 unsigned int size; //size表示当前二叉堆的大小,即元素个数 unsigned int *heap; //heap即“数组”,根据初始化时给定的大小初始化 }; typedef struct BinaryHeap *PriorityQueue; //PriorityQueue即优先队列
PriorityQueue Initialize(unsigned int capacity) { PriorityQueue pPQueue = (PriorityQueue)malloc(sizeof(struct BinaryHeap)); pPQueue->heap = (unsigned int *)malloc(sizeof(int)*capacity); pPQueue->capacity = capacity; pPQueue->size = 0; pPQueue->heap[0] = 0; //令heap[0]为0可以避免插入时新元素上滤过头,习至插入时就明白 return pPQueue; }
那么,二叉堆是如何满足优先队列需求的呢?这就得从二叉堆对结点的要求说起,在二叉堆中结点有且只有一个要求:任一结点优先级高于其孩子。
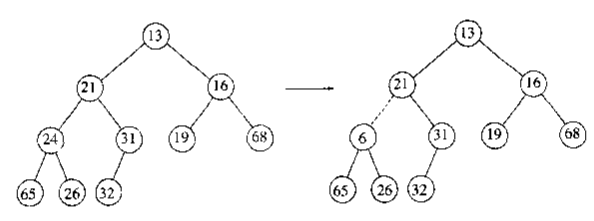
下图中,只有左侧的完全二叉树符合二叉堆要求,右侧结点6不符合二叉堆要求
接下来带着这两个要求,我们看看该如何实现对二叉堆的插入。现在,假设我们已经有了如下二叉堆及一个新结点14。
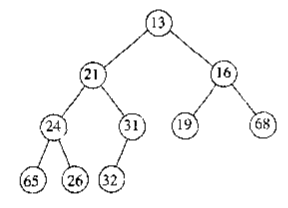
数组存储如下

首先,我们要确保新结点插入后二叉堆依然是完全二叉树,保证这一点的方法很简单,就是让新结点暂时先插入到完全二叉树的最后一层最右元素的右边,直接的说,就是插入到当前数组最后元素的后一个位置。
然后,我们要让新结点去往它应在的位置,或者准确点说是应在的层次,这一点的实现非常简单:令新结点不断与父结点比较,若新结点优先级更大,则其与父结点交换位置,直到新结点优先级不高于父结点为止。这种策略我们称之为“上滤”(下图中空结点即新结点14)
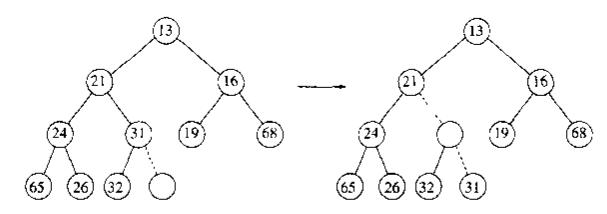
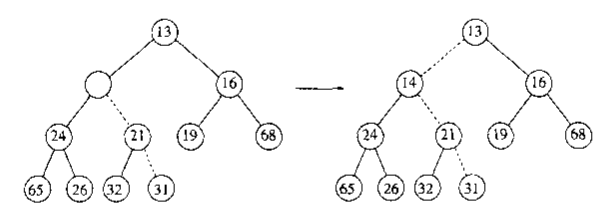
插入过程数组的示意如下:
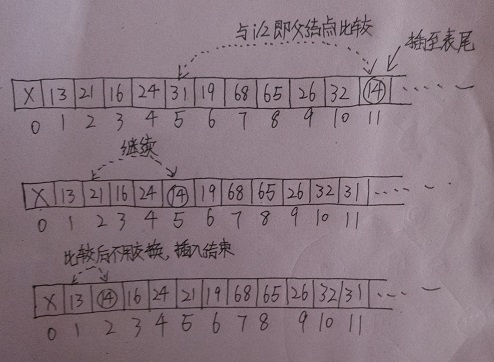
知道了插入的思路后,插入的代码也就不难写出了:
bool Insert(PriorityQueue pPQueue, unsigned int x) { //由于二叉堆的heap[0]是放弃不用的,所以size最大为capacity-1 if (pPQueue->size == pPQueue->capacity - 1 || x == 0) return false; //CurPos即当前位置,初始化为插入后的二叉堆size,即表尾 unsigned int CurPos = ++pPQueue->size; //不断地令CurPos对应的父结点与x比较,若大于x则令父结点下滤,等价于令x上滤 //若小于x则退出循环,此时CurPos即x应处的位置 for (;pPQueue->heap[CurPos / 2] > x;CurPos /= 2) { pPQueue->heap[CurPos] = pPQueue->heap[CurPos / 2]; } pPQueue->heap[CurPos] = x; return true; }
注意到若CurPos为1,即根,则heap[0]将与x比较,为了避免x上滤过头至heap[0],我们在前面要求了x必须为正整数,而heap[0]则在初始化时设为0,这样一来heap[0]必小于任一插入元素
稍加分析就可以看出,插入时的最坏情况也只是新结点上滤到根,此时新结点上滤的路径就跟向二叉树中插入了一个叶子结点是类似的,时间复杂度为O(logN)
现在我们来看看二叉堆是如何实现出队操作的。在二叉堆中要找优先级最高的结点非常简单,根结点即是。但是取走了根结点后,该处就成了一个“空结点”,这个“空结点”又该如何处理?简单的想法是不断地令“空结点”的孩子中优先级更高者与“空结点”交换,直至“空结点”到最底层。但这个想法容易出错,如下图,空结点最后导致了完全二叉树属性的破坏
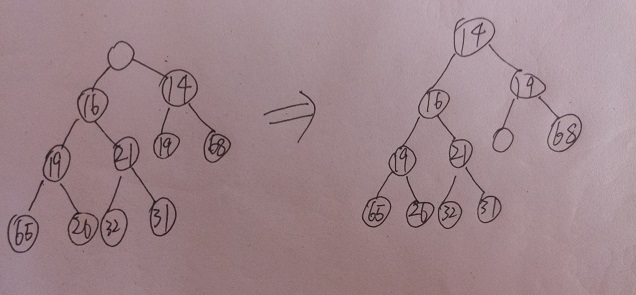
那么该如何保证二叉堆的完全二叉树属性呢?解决方法就是对上述想法稍加改进:根结点删除后,令二叉堆最后一个结点顶替其位置,而后逐层“下滤”至其优先级大于其所有孩子为止。这样一来,二叉堆的完全二叉树属性就可以保住。因为这么做的话,即使“新根结点”下滤到了最底层也不会导致“空结点”的出现从而破坏完全二叉树属性。(下图中空结点即原表尾结点31)
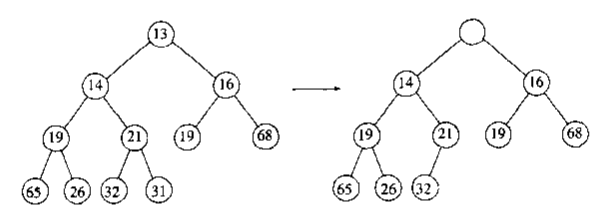


(出队操作的数组变化略)
知道了出队的思路后,出队的代码也就不难写出了:
unsigned int Dequeue(PriorityQueue pPQueue) { //若堆已空则返回0,0必不为表中元素 if (pPQueue->size == 0) return 0; unsigned int root = pPQueue->heap[1]; //root保存了原堆根,即需要返回的值 unsigned int LastElement = pPQueue->heap[pPQueue->size--]; //LastElement即表尾元素 //令LastElement从根开始下滤,所以CurPos初始化为1,child用于指出CurPos两个孩子中优先级更高的那个 unsigned int CurPos = 1; unsigned int child = CurPos * 2; while (child <= pPQueue->size) { //若child不是最后一个元素,且其兄弟(CurPos的右孩子)优先级更高,则令child指向CurPos右孩子 if (child != pPQueue->size&&pPQueue->heap[child] > pPQueue->heap[child + 1]) child += 1; //比较LastElement与CurPos最优先的孩子,若LastElement更优先,则循环结束 //否则令CurPos最优先孩子上滤,等价于令LastElement下滤 if (pPQueue->heap[child] < LastElement) { pPQueue->heap[CurPos] = pPQueue->heap[child]; CurPos = child; child = CurPos * 2; } else break; } //跳出循环后的CurPos即LastElement该处的位置 pPQueue->heap[CurPos] = LastElement; return root; }
出队的时间复杂度与入队(插入)相同,为O(logN)。
有了上述代码,二叉堆就算是基本实现了(Destroy的代码没有给出,但实现并不难)。那么二叉堆,或者说优先队列(即堆,但不只是二叉堆,还有别的实现方式,均称为堆或优先队列)还有什么别的用处吗?
试想一下如果我们将一组需要排序的数据插入到二叉堆去,然后再不断Dequeue并将得到的元素(即二叉堆的根)插入到普通队列中,我们是否会得到一个有序的队列?也就是说,二叉堆可以用来完成排序工作!那么二叉堆完成排序需要的时间是多少呢?大致是插入时间+出队时间,即O(N*logN+N*logN),O(N*logN)。这个时间比我们大多数人知晓的冒泡排序、选择排序要好得多。我们将在之后的博文中完善堆排序的实现方法。
下面的地址有着二叉堆的简单实现与试验,同时展示了二叉堆的排序效果
https://github.com/nchuXieWei/ForBlog-----BinaryHeap