本次要爬取的网站是:
先上代码:
import requests
from bs4 import BeautifulSoup
import os
import re
def getHtmlurl(url):
try:
r = requests.get(url)
r.raise_for_status()
# 有效的判断网络连接的状态。如果网连接出现错误,那么它就会用try-except来获取一个异常。
r.encoding = r.apparent_encoding
# 设置编码格式为 从内容中分析出的相应内容编码方式
return r.text
except:
return "出现异常"
def getimgurl(img):
href = img['href']
url = "http://www.netbian.com" + href
htm = getHtmlurl(url)
soup = BeautifulSoup(htm, 'html.parser')
# htm 表示被解析的html格式的内容
# html.parser表示解析用的解析器
return soup
def getpic(html):
soup = BeautifulSoup(html, 'html.parser')
all_img = soup.find('div', class_='list').find('ul').find_all("a", attrs={'href': re.compile('^((?!http).)*$'),
'target': '_blank'})
for img in all_img:
title = img['title']
if title.find(u"女") != -1:
# 你可以自定义规则来筛选你想要的壁纸
print("不符合要求,跳过")
continue
soup1 = getimgurl(img)
im1 = soup1.find('div', id='main').find('div', class_='endpage').find('p').find('img')
img_url = im1['src']
print(img_url)
root = 'D:/pictest2/'
# 这是你要保存图片的位置
t = title.split()
# 将图片title按空格分开,取第一个空格前的字符作为图片名,这个你可以自己调整
path = root + t[0] + '.jpg'
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(img_url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已存在')
except Exception as e:
print(str(e))
print('爬取失败')
def getNextpage(html):
soup = BeautifulSoup(html, 'html.parser')
nextpage = soup.find('div', class_='list').find('ul').find('li', class_='nextpage').find('a')
href = nextpage['href']
url = "http://www.netbian.com" + href
return url
def main():
url = 'http://www.netbian.com/weimei/index.htm'
for i in range(1, 10):
html = getHtmlurl(url)
print(str(i) + " : ")
getpic(html)
url = getNextpage(html)
if __name__ == '__main__':
main()
☞现在我们来分析一下爬取壁纸的步骤:
从做事步骤来看
-
查看网页的源代码,挖掘其特征,找出自己要爬取的部分,对于我们的壁纸爬取,找到的就是图片的网址
-
下载该网址的图片到本地文件中
从编写代码来看
-
得到网页全部源代码
-
从源代码中找到自己要的部分,并想法将它提取出来
-
将图片下载到本地
☞知道我们的目的和思路后,我们来编写代码
-
我们要先得到网页的全部源代码,这里需要用到我们的requests库
def getHtmlurl(url):
try:
r = requests.get(url)
r.raise_for_status()
# 有效的判断网络连接的状态。如果网连接出现错误,那么它就会用try-except来获取一个异常。
r.encoding = r.apparent_encoding
# 设置编码格式为 从内容中分析出的相应内容编码方式
return r.text
except:
return "出现异常"
其中requests.get(url)得到的就是网页代码的全部内容,如下截图:

-
在代码中我们所要的就是图片的网址
我们观察这些代码,发现图片都在这里面
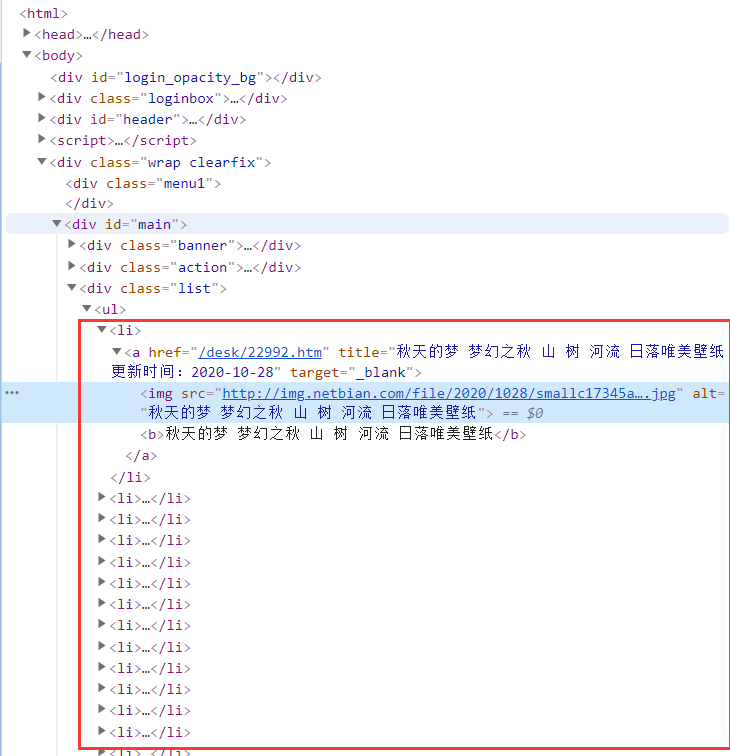
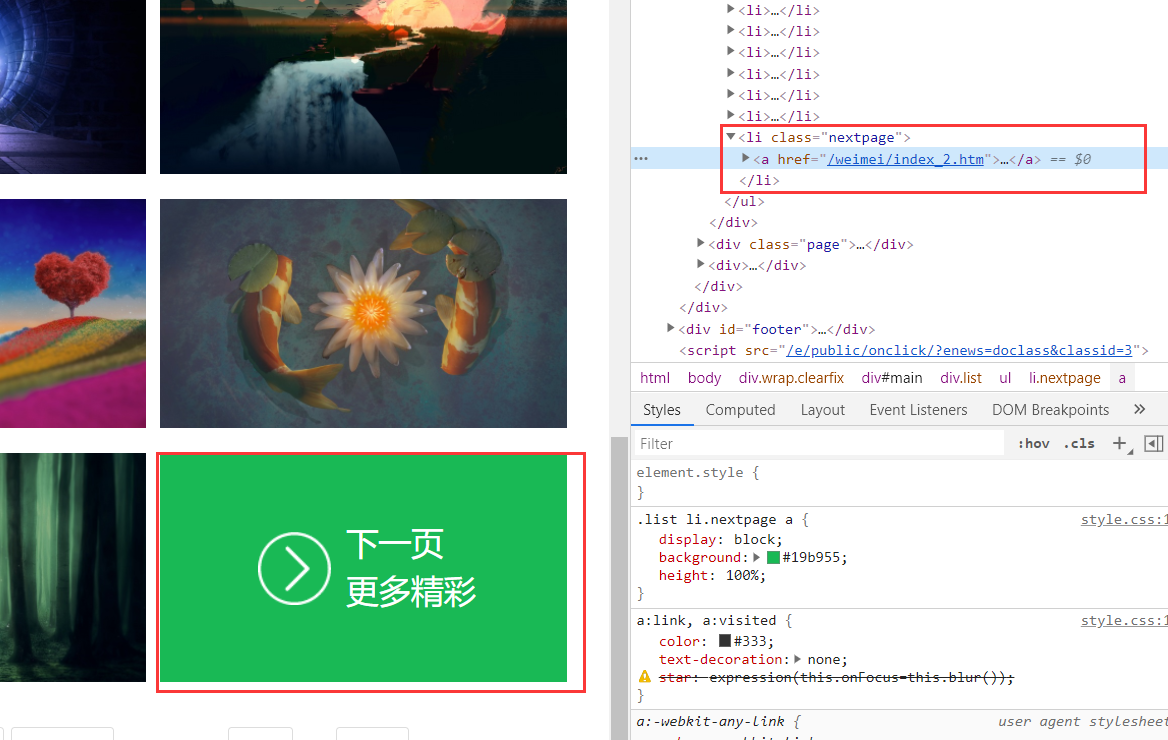
不过要注意,网站下拉最后一个不是图片,而是下一页的网址
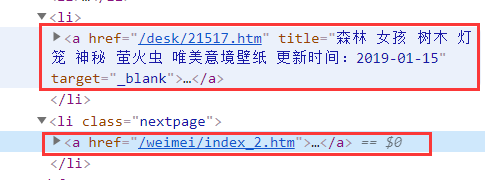
所以我们在提取的时候要把这最后一个给过滤出去,观察它们<a>标签的不同,可以看出它们有一个显著的区别,就是一个有target标签,一个没有
所以我们可以这样过滤:
all_img = soup.find('div', class_='list').find('ul').find_all("a", attrs={'target': '_blank'})
这里还有一个要过滤的,如下所示,他点开展示的是另外一组图片

比较它们的区别,可以看到它们的href一个里面包括http,一个不包括,所以我们可以这样过滤
soup = BeautifulSoup(html, 'html.parser')
all_img = soup.find('div', class_='list').find('ul').find_all("a", attrs={'href': re.compile('^((?!http).)*$'),'target': '_blank'})
这样我们就得到了我们想要的部分,不过事情没有那么简单,如果我们点开img标签里的网址,我们得到的并不是一个高清大图,于是我们继续深入内里
进入<a>标签中的网址,或者直接点击图片,然后我们研究一下跳转后的页面的源代码
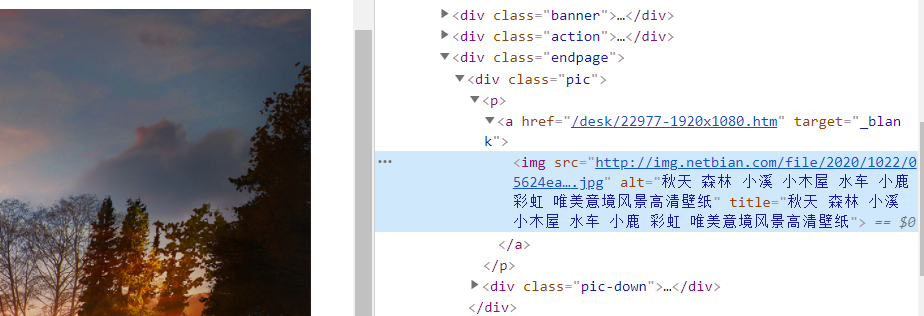
现在我们要得到这个img标签里的网址,还是用我们的BeautifulSoup:
soup1 = 通过前一个网页的a标签里的地址得到这个跳转后网页的全部代码
im1 = soup1.find('div', id='main').find('div', class_='endpage').find('p').find('img')
从上面这代码中,我们看出,我们需要通过上一个网页中的a标签来得到这个跳转后的页面的网址,从而通过BeautifulSoup得到这个页面的全部内容,这里我定义了一个方法,传入参数为上一个页面<a>标签里的内容
def getimgurl(img):
href = img['href']
# 这里我们需要拼一下串,因为a标签里的网址不是完整的
url = "http://www.netbian.com" + href
htm = getHtmlurl(url)
soup = BeautifulSoup(htm, 'html.parser')
# htm 表示被解析的html格式的内容
# html.parser表示解析用的解析器
return soup
-
现在,我们已经离成功不远了,我们得到了图片的网址,现在只要下载下来保存到本地即可
title = img['title']
root = 'D:/pictest/'
# 这是你要保存图片的位置
t = title.split()
# 将图片title按空格分开,取第一个空格前的字符作为图片名,这个你可以自己调整
path = root + t[0] + '.jpg'
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(img_url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已存在')
except Exception as e:
print(str(e))
print('爬取失败')
这样我们的入门级爬虫就完成啦,根据个人爱好,你还可以进行壁纸的筛选,譬如我不要美女的壁纸,那我可以这样做
if title.find(u"女") != -1:
# 你可以自定义规则来筛选你想要的壁纸
print("不符合要求,跳过")
continue
听完解释后,再去看一遍源码吧,相信你就有自己打出来的能力了!!!(其中的getNextpage方法的作用是得到下一页的网址,相信你们自己已经可以看懂啦)
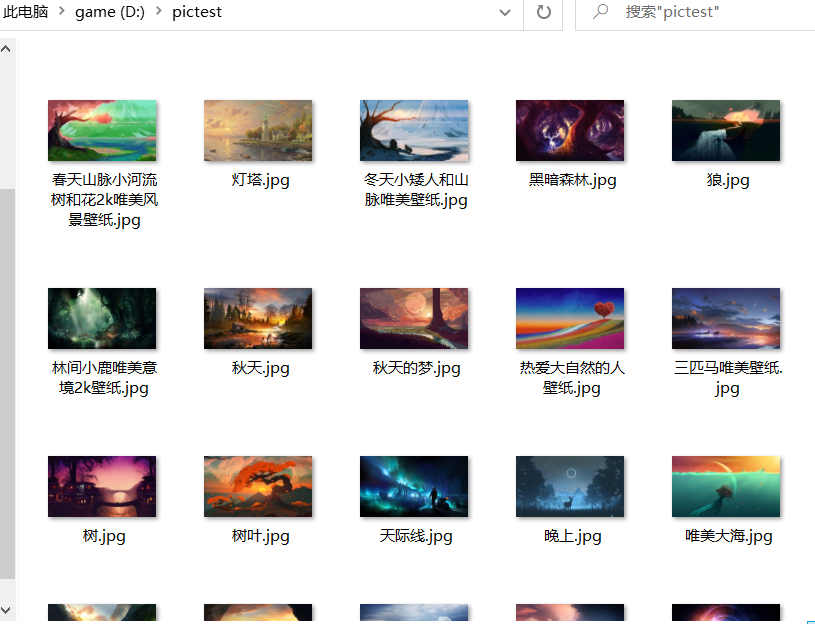
最终结果如下:
参考文章:https://blog.csdn.net/xuelucky/article/details/81217906