- 什么是HBase数据库?
- HBase是分布式、面向列(列族)的开源数据库;
- HDFS为HBase提供可靠的底层数据存储服务;
- Zookeeper为HBase提供稳定服务和Failover机制;
- HBase是一个通过大量廉价机器解决海量数据的高速存储和读取的分布式数据库解决方案。
- HBase数据库有什么特点?
- 海量存储
HBase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几百毫秒内返回数据。
-
- 列式存储
这里说的列式存储其实说的是列族存储,HBase是根据列族来存储数据的,列族下面可以有非常多的列,列族在创建表时就必须指定。
-
- 极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
-
- 高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
-
- 稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,列可以在数据库运行的过程中动态的添加,在列数据为空的情况下,是不会占用存储空间的。
- 数据是怎么存的
- 逻辑存储结构
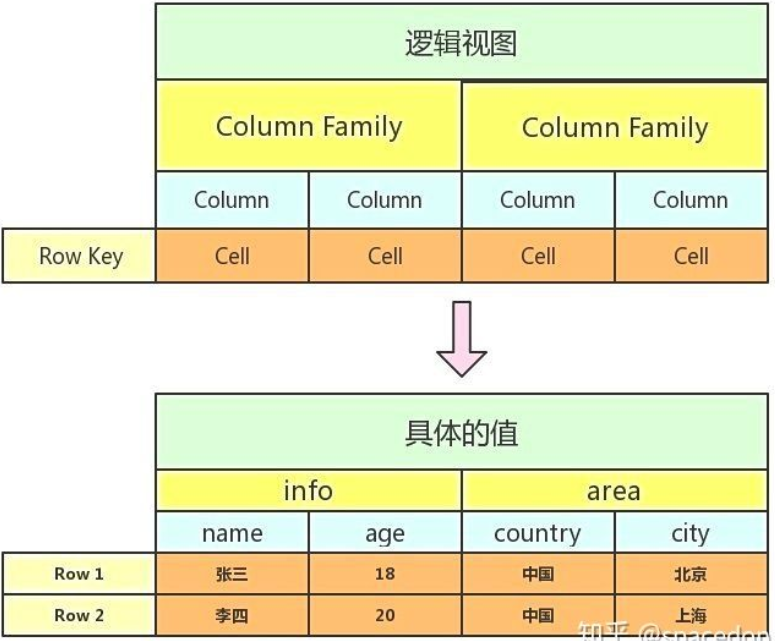
-
-
- Column Family又叫列族,Hbase通过列族划分数据的存储,列族下面可以包含任意多的列,实现灵活的数据存取。Hbase表的创建的时候就必须指定列族。Hbase的列族不是越多越好,官方推荐的是列族最好小于或者等于3。
- Column 为列属于某一个列簇,在 HBase 中可以进行动态的添加。
- Row Key 表的主键,按照字典序排序。
- Cell 指具体的值。
- Version在这张图里面没有显示出来,这个是指版本号,用时间戳(TimeStamp)来表示。
- Hbase是一个kv数据库,怎么根据Key来获取Value呢?
-
Hbase的key包含以下内容:
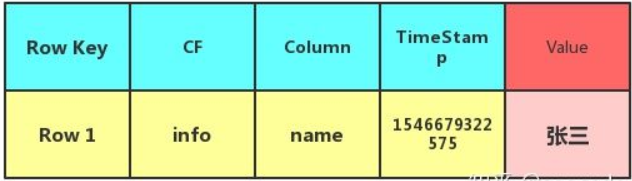
Key是由 Column Family、Column和TimeStamp来组成的。TimeStamp 在 HBase 中充当的作用就是版本号,因为在 HBase 中有着数据多版本的特性,所以同一个 Key可以有多个版本的 Value 值(可以通过配置来设置多少个版本)。
-
- HBase的物理存储结构
HBase的架构图如下:
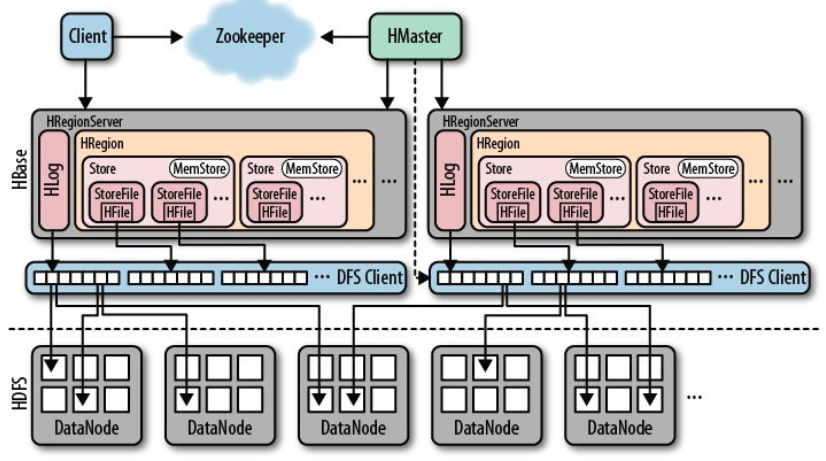
从图中可以看出Hbase是由Client、Zookeeper、HMaster、HRegionServer、HRegion、HStore、HDFS等几个部分组成,下面来介绍一下几个部分的相关功能:
-
- Client
Client包含了访问Hbase的接口,Client还会维护对应的cache来加速Hbase的访问。
-
- Zookeeper
ZooKeeper是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
Hbase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
具体工作如下:
- 通过Zoopkeeper来保证集群中只有1个master在运行,如果master异常,会通过竞争机制产生新的master提供服务;
- 通过Zoopkeeper来注册HRegionserver和HRegion;
- 通过Zoopkeeper存储元数据的统一入口地址等。
-
- Hmaster
Hmaster节点的主要职责如下:
- 协调多个RegionServer,监测各个RegionServer之间的状态,并平衡RegionServer之间的负载;
- 为RegionServer分配Region;
- 发现失效的Region,并将失效的Region分配到正常的RegionServer上;
- HDFS上的垃圾文件回收;
- 处理Schema更新请求等。
-
- HRegionServer
HregionServer就是一个机器节点,包含多个HRegion,是服务器中的一个进程。它的功能概括如下:
- 维护Hmaster为其分配的Region;
- 处理HRegion的IO请求,负责与底层HDFS的交互;
- 负责切分正在运行过程中变得超过阈值的Hregion;
-
- HRegion
HRegion是一个数据表(Table)中的一个分片在一个HRegionServer中的表达。
一个Table可以有多个HRegion,HBase使用rowKey将表水平切割成多个HRegion,每个HRegion都纪录了它的StartKey和EndKey,由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。HRegion由HMaster分配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)。
HRegion是Hbase中分布式存储和负载均衡的最小单元,HRegion是按大小分割的,随着数据增多,HRegion不断增大,当增打到一个阈值的时候,HRegion就会分割为两个新的HRegion.
-
- HStore
HRegion由多个HStore构成,每个HStore对应了一个Table在这个HRegion中的一个列族列族(Column Family),即每个列族就是一个集中的存储单元,因而最好将具有相近IO特性的列存储在一个列,以实现高效读取。HStore是HBase中存储的核心,它实现了读写HDFS功能,一个HStore由一个MemStore 和0个或多个StoreFile组成。
-
- MemStore
MemStore是一个写缓存(In Memory Sorted Buffer),数据写入时会写入MemStore中,由MemStore根据一定的算法将数据Flush到StoreFile,通常每个HRegion中的每个列族有一个自己的MemStore。
-
- StoreFile
StoreFile 用于存储HBase的数据(Cell/KeyValue),StoreFile以HFile格式保存在HDFS上。HFile是Hadoop的二进制格式文件。实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile.
-
- WAL(HLog)
WAL即Write Ahead Log,在早期版本中称为HLog,它是HDFS上的一个文件,如其名字所表示的,所有写操作都会先保证将数据写入这个Log文件后,才会真正更新MemStore,最后写入HFile中。采用这种模式,可以保证HRegionServer宕机后,我们依然可以从该Log文件中读取数据,Replay所有的操作,而不至于数据丢失。
-
- HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为Hbase提供高可用(Hlog存储在HDFS)的支持,提供元数据和表数据的底层分布式存储服务,数据多副本,保证的高可靠和高可用性。
- HBase读取数据的过程
- Client访问zookeeper,获取元数据存储所在的HRegionServer 。
- 通过刚刚获取的地址访问对应的HRegionServer ,拿到对应的表存储所在的HRegionServer;
- 去表所在的HRegionServer进行数据的读取;
- 查找对应的HRegion,在HRegion中寻找列族,先从MemStore中读取,如果找不到去BlockCache中寻找,再找不到就进行StoreFile的遍历;
- 找到数据之后会先缓存到BlockCache中,再将结果返回。
Ps: BlockCache为HBase读缓存。
- HBase写入数据的过程
- Client访问Zookeeper,获取元数据存储所在的HRegionServer;
- 通过刚刚获取的地址访问对应的HRegionServer ,拿到对应的表存储所在的HRegionServer ;
- 去表所在的HRegionServer进行数据的添加;
- 查找对应的HRegion,在HRegion中寻找列族,在WAL中备份完数据后向MemStore中写入数据;
- 当MemStore写入的值超过阈值,触发溢写操作(flush),进行文件的溢写,成为一个StoreFile ;
- 随着StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile;
- 当StoreFile中的数据逐渐变大之后,达到某一个阈值,会进行裂变(一个HRegion等分为两个HRegion,并分配到不同的HRegionServer),原本的HRegion会下线,新Split出来的两个HRegion会被HMaster分配到相应的HRegionServer上,使得原先1个HRegion的压力得以分流到2个HRegion上。
