准备环境
1、JDK1.8版本,在5.X版本之后要求必须使用JDK8级以上版本
2、准备elasticsearch安装包,我这里使用的是6.X版本的
3、准备好Linux,我这里准备了三台centos7来进行搭建
下面说下如果不会进行搭建Linux的可以找曾经的docker这个章节进行学习,docker第一章有介绍到如何搭建环境
这里给出相应的下载地址
JDK1.8:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Elasticearch:https://www.elastic.co/downloads/elasticsearch
centos7:https://www.centos.org
这里需要你提前安装好JDK环境,这个就非常简单了,如果这个都搞不定的话,是不会来学习这个技术的!所以不再这里进行详细的说明了!
下面进行的是安装过程,这里就进行流水账的方式进行记录了
首先我分配了三台Linux虚拟机:
| 地址 | 192.168.56.60 | 192.168.56.61 | 192.168.56.62 |
|---|---|---|---|
| 名称 | ETL-node1 | ETL-node2 | ETL-node3 |
| 作用 |
一、单节点安装配置及配置文件参数说明
上面是准备好的基础环境,这里是三台Linux都已经装好了JDK环境,并且安装文件以及放在了/usr/local/server目录下面

如上图环境已经准备完毕,左边的是node1,右上的是node2,右下是node3
解压elasticsearch-6.3.zip文件
$ yum install -y zip unzip
$ unzip elasticsearch-6.3.zip

先来看下目录结构吧

bin:存放着一些脚本
lib:库文件
logs:日志文件
config:配置文件
modules:加载的模块列表,内置插件
plugins:自定义插件
去看elasticsearch.yml配置文件中的属性吧:
cluster.name:
node.name:
cluster.name: elasticsearch
node.name: es-node01
bootstrap.memory_lock: true
network.host: 192.168.1.101
bootstrap.system_call_filter: false
http.port: 9200
bootstrap.memory_lock: true
#旧版本叫bootstrap.mlockall: true


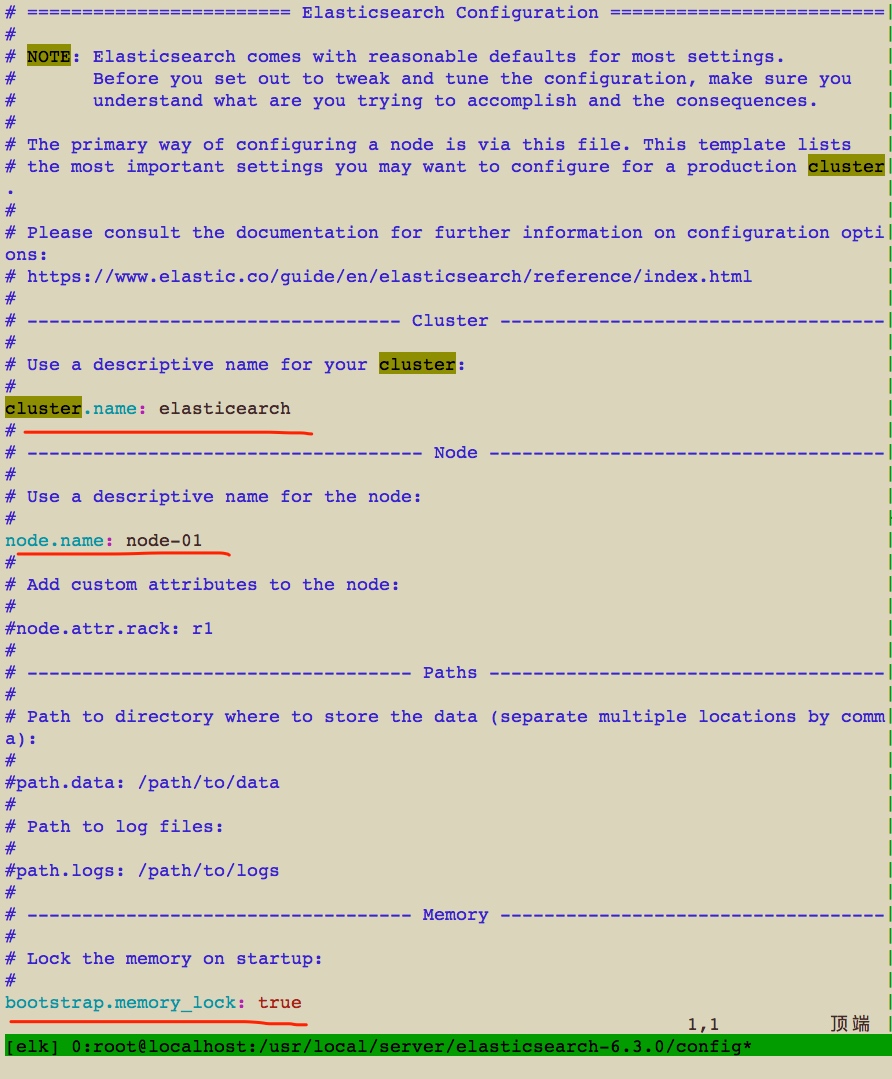
按照上面这个内容将其配置好,然后就可以进行启动了!
我这里整理一份我的node1节点的elasticsearch.yml配置信息:
cluster.name: elasticsearch
node.name: node-01
bootstrap.memory_lock: true
network.host: 192.168.56.60
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.56.61", "192.168.56.62"]
discovery.zen.minimum_master_nodes: 3
gateway.recover_after_nodes: 3
node1节点的jvm-options配置文件
修改jvm内存设置,这里根据自己的具体情况进行设置
-Xms1g
-Xmx1g
使用命令
$ ./bin/elasticsearch
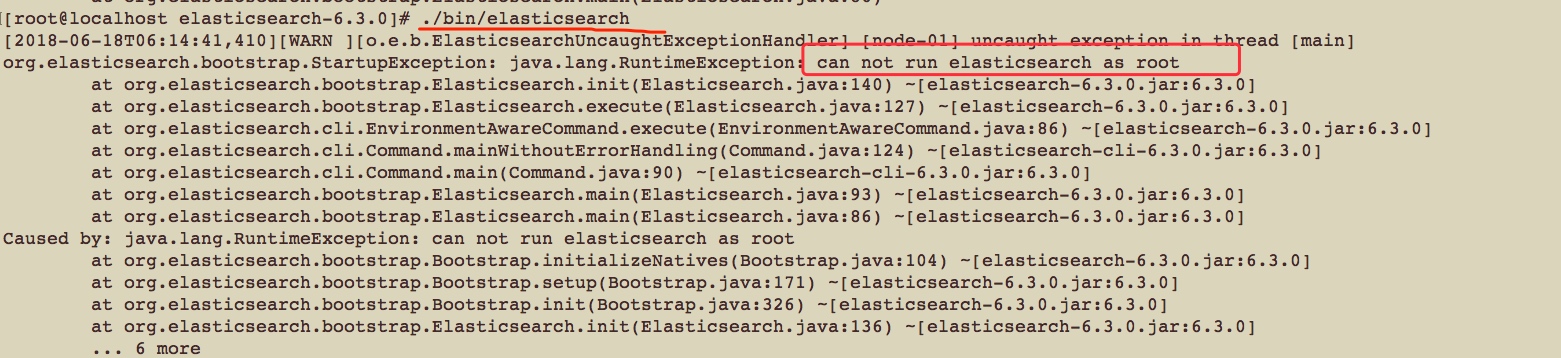
启动的时候需要注意,之前我都是使用的root用户进行操作的,但是elasticsearch为了安全起见,是不允许使用root进行启动的,所以我们先创建一个账号和用户组,然后把elasticsearch的文件夹设置成这个账号和用户组中的文件,现在我的elasticsearch文件下的所有文件都是root:rootroot用户和root用户组下面的内容

创建用户用户组:
$ groupadd elc
$ useradd elc -g elc -p elc
$ chown -R elc:elc elasticsearch-6.3.0
重新设置一个好记的密码给elc用户
使用下面命令,后面输入两次密码就可以了
$ passwd elc

想要使用sudo不输密码,去修改下面文件
$ sudo vim /etc/sudoers
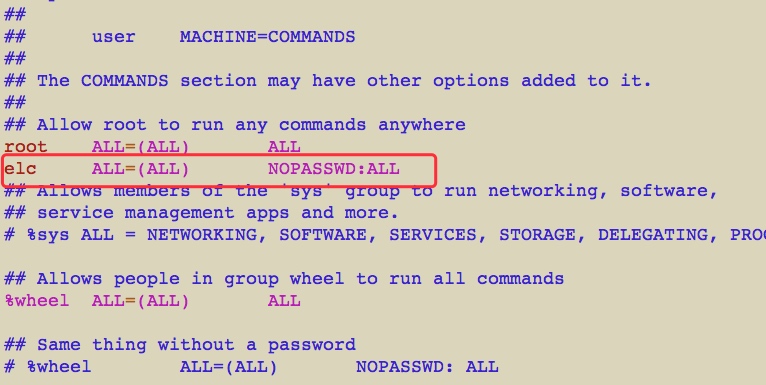
保存使用qw!

好了现在开始在进行启动
启动之前切换用户,运行elasticsearch启动脚本,这个脚本在elasticsearch文件目录的bin目录下面
$ su elc
$ ./bin/elasticsearch
启动的时候报错了,想办法把他解决掉

二、启动错误解决
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: memory locking requested for elasticsearch process but memory is not locked
[3]: max number of threads [3886] for user [elc] is too low, increase to at least [4096]
[4]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
来看一下这四个错误:
1、[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
原因:无法创建本地文件问题,用户最大可创建文件数太少
解决办法:切换到root用户,编辑/etc/security/limits.conf配置文件,添加相关内容
* soft nofile 65536
* hard nofile 131072
备注:* 代表Linux所有用户名称
2、[2]: memory locking requested for elasticsearch process but memory is not locked
原因:因为我们在配置文件中配置了锁定内存,但是现在elasticsearch无法锁定内存,所以报错
解决办法:
切换到root用户,编辑/etc/security/limits.conf配置文件,添加如下内容
* soft memlock unlimited
* hard memlock unlimited
保存、退出、重新登录才可生效
临时取消限制
ulimit -l unlimited
增加/etc/security/limits.conf解决上面两个问题

重新启动

只剩下后面两个错误了
注意:上面这两个错误需要保存退出之后重新登录才有效
3、[3]:max number of threads [3886] for user [elc] is too low, increase to at least [4096]
原因:
无法创建本地线程,用户最大可创建线程数太少
解决办法:
切换到root用户,修改文件/etc/security/limits.d/90-nproc.conf
这里需要注意的是,在centos6中是90-nproc.conf这个文件,在centos7中是20-nproc.conf这个文件
在修改完成之后需要重启机器或者退出终端重新进入才能生效
将
* soft nproc 3886
修改为
* soft nproc 4096
这里配置完成之后使用命令,查看
$ ulimit -a
因为我的是centos7设置了这个地方并没有生效所以,我还要在/etc/security/limits.conf文件中添加两个配置
* soft nproc 4096
* hard nproc 4096
设置完成之后退出终端,使用命令查看

上面这些配置就是我们设置的这些配置,包括什么文件打开限制,用户线程限制等等
4、[4]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
原因:最大虚拟内存太小
解决办法:切换到root用户下,修改配置文件/etc/sysctl.conf
添加如下配置
vm.max_map_count=655360
修改完成之后执行
$ sysctl -p

上面这些内容设置完成之后重新启动elasticsearch
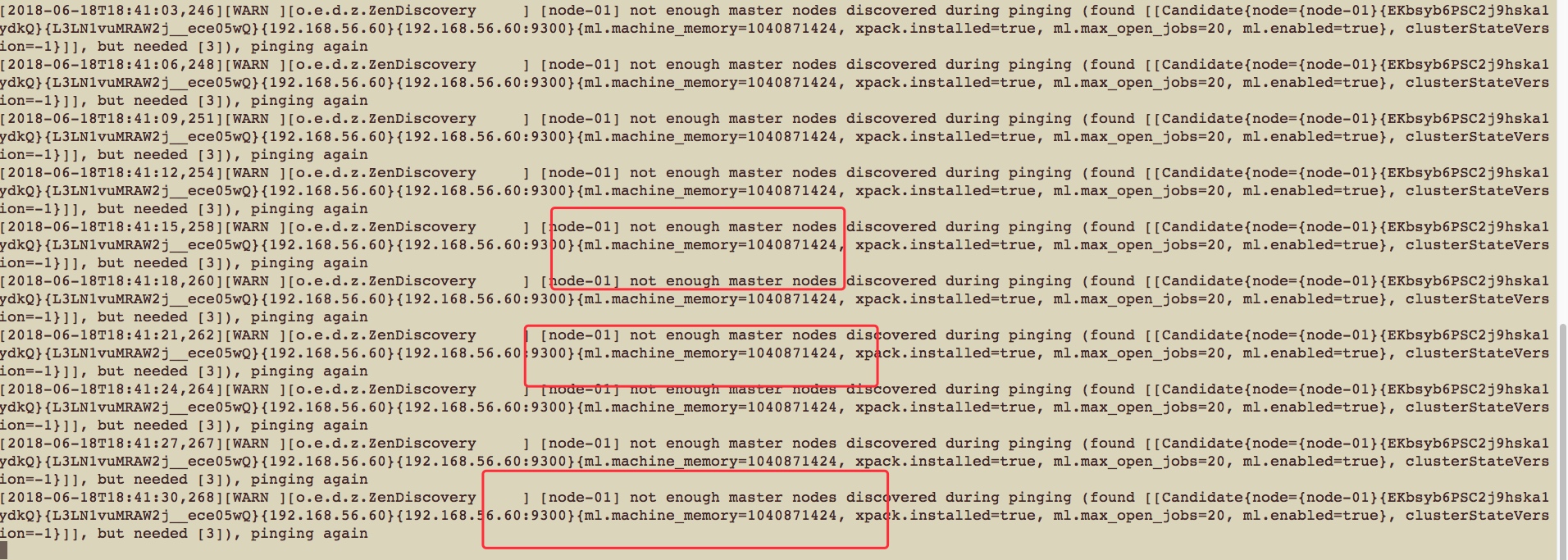
好了启动是启动完成了,也没有报错,但是没有启动成功,因为我们在配置文件中配置了服务发现新相关的内容,他需要三个节点启动成功之后然后才能启动,我们是需要3个节点,现在只有一个,等会我们按照上面的配置在将其他节点进行配置上!
三、配置其他节点
上面呢,我们只是吧192.168.56.60这台机器上的node1节点配置完成,接下来根据上面的两节内容将下面的剩余节点配置完成,那么在后面的两个节点当中我就只会列出我的配置文件,错误的解决上面已经说了,包括jdk8的安装,用户的新建,以及用户权限,文件权限这些内容后面就不会再讲
192.168.56.61机器node2节点elasticsearch.yml配置文件列表:
cluster.name: elasticsearch
node.name: node-02
node.attr.rack: r1
bootstrap.memory_lock: true
network.host: 192.168.56.61
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.56.60", "192.168.56.62"]
discovery.zen.minimum_master_nodes: 3
gateway.recover_after_nodes: 3
192.168.56.62机器node3节点elasticsearch.yml配置文件列表:
cluster.name: elasticsearch
node.name: node-03
node.attr.rack: r1
bootstrap.memory_lock: true
network.host: 192.168.56.62
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.56.60", "192.168.56.61"]
discovery.zen.minimum_master_nodes: 3
gateway.recover_after_nodes: 3
上面这两个就是node2和node3的节点配置,按照上面的配置文件进行配置的
按照上面的配置配置完成之后,分别启动三台节点
这个时候有个问题,就是防火墙的问题,他们之间是需要进行互相之间进行同行的,所以说,要么你把防火墙关闭,要么吧他们需要的通信端口打开
他们之间有两个默认端口:9200、9300
就是上面这两个端口
centos7关闭防火墙,并且关闭开机自启动
$ systemctl stop firewalld
$ systemctl disable firewalld
或者去开放端口
centos7开放端口
#添加端口(--permanent)永久生效
$ firewall-cmd --zone=public --add-port=9200/tcp --permanent
$ firewall-cmd --zone=public --add-port=9300/tcp --permanent
#重新加载
$ firewall-cmd --reload
#查看端口
$ firewall-cmd --zone= public --query-port=80/tcp
#删除端口
$ firewall-cmd --zone= public --remove-port=80/tcp --permanent
上面这些关于防火墙的东西设置完成之后就进行启动
#守护进程方式启动
$ ./bin/elasticsearch
#后台启动
$ ./bin/elasticsearch -d
分别启动三个节点
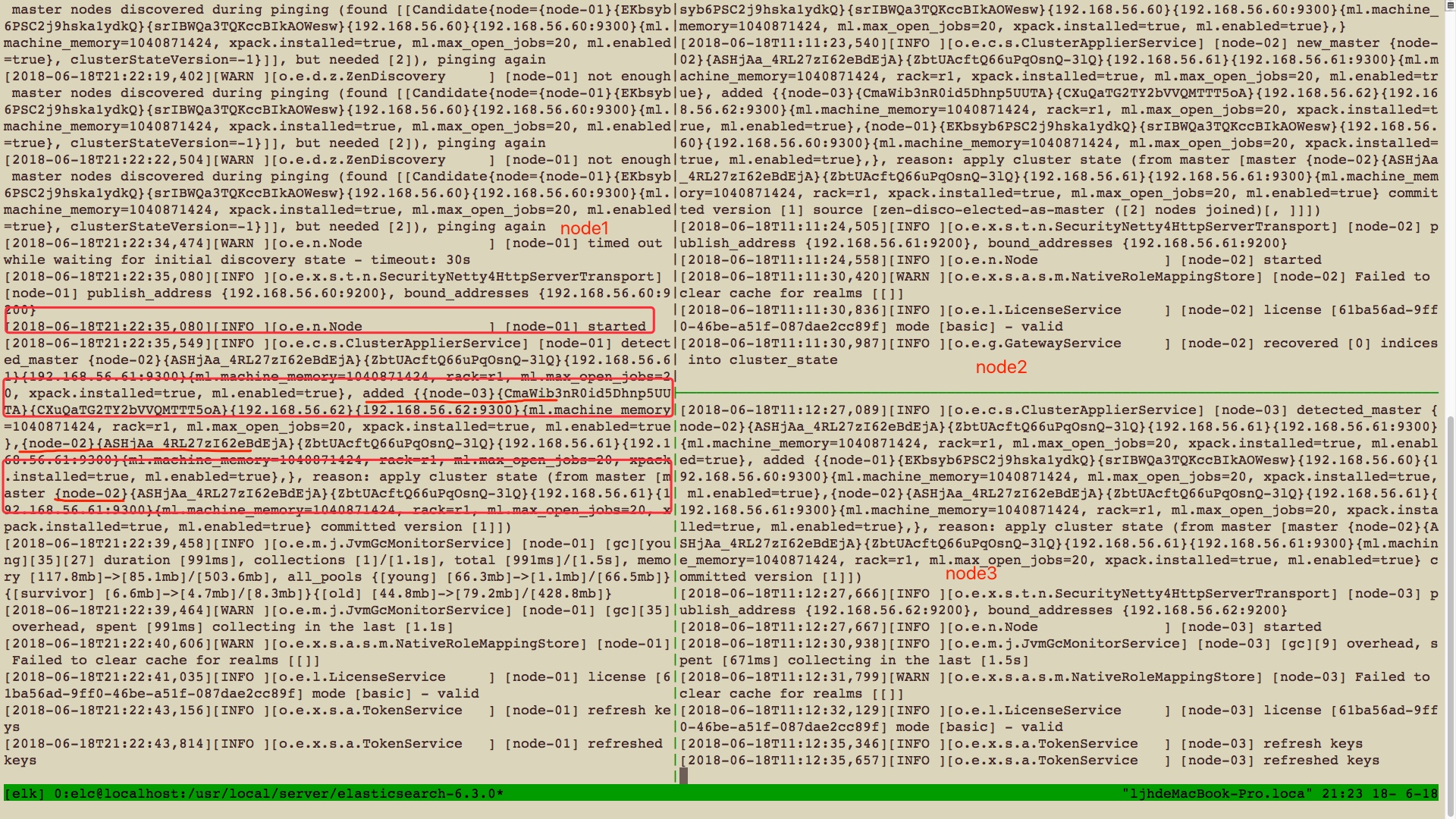
启动完成之后可以看到如上信息,很明显现在master节点是node1,现在我们可以通过elasticsearch提供的一些restful的接口尝试着访问他,看我们的集群是否已经搭建成功


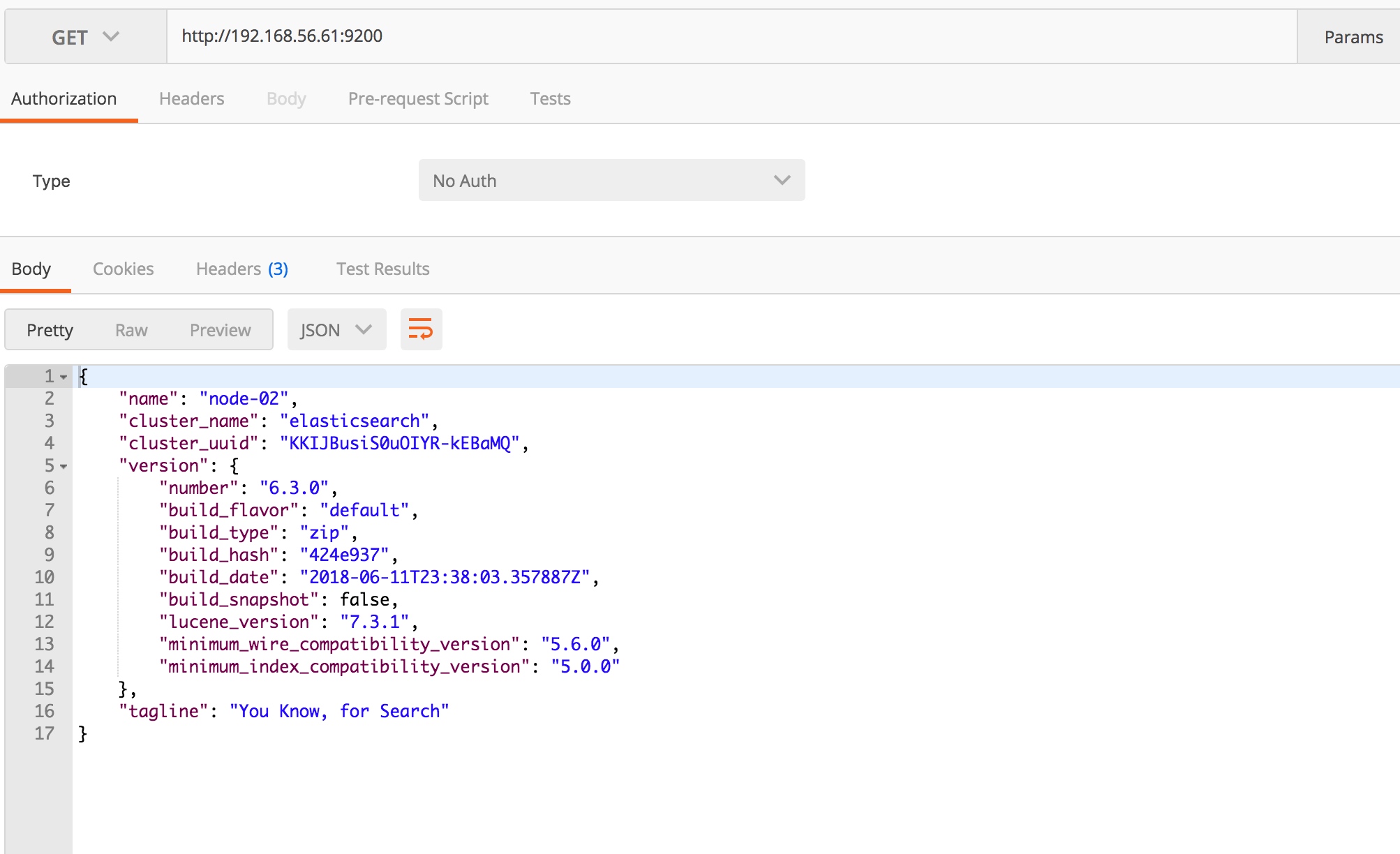
看上面说明是成功了哈!
四、安装elasticsearch-head插件
我们在使用elasticsearch当中怎么能通过更加直观或者高效的方式进行管理或者查看,那么这里就有了一个插件能够在网页中让我们进行一些对elasticsearch基本的操作和查看的功能,这个插件也是用elasticsearch提过的restful进行整合写出来的,方便使用,下面就来进行安装吧
插件地址:https://github.com/mobz/elasticsearch-head
将插件下载下来,我这里放在了/usr/local/server目录下面,把名字改成了elasticsearch-head,可以来看一下解压的目录结构
解压
$ unzip elasticsearch-head-master.zip
查看目录信息:

因为该插件是使用nodejs编写的,所以我们需要安装nodejs环境,并且使用npm进行安装改插件
安装nodejs环境:
使用yum进行安装,在安装环境的使用我是使用的root用户进行安装的
//这里下载nodejs的一些镜像文件,默认的基础yum库是没有nodejs相关的库的(这里下载的是最新版本的nodejs库)
$ curl --silent --location https://rpm.nodesource.com/setup_6.x | bash -
//安装nodejs环境
$ yum -y install nodejs
如果没有curl命令的话,安装他
$ yum install -y curl
查看nodejs和npm版本信息
$ node -v
$ npm -v

说明安装成功
下面再来说下,由于nodejs中的npm库的站点是在国外,所以使用起来非常慢,所以下面就挂载个淘宝的镜像,这样快些
如下
$ npm install -gd express --registry=http://registry.npm.taobao.org

或者使用
这种方式是直接设置了镜像仓库,直接设置是淘宝的镜像,而上面这种方式在每次使用安装的时候都会要求使用--registry来指定镜像仓库,上面实际上就是安装了一个express的插件,这个插件是为了演示安装的,你可以不用安装,只是为了说明,安装的时候需要指定镜像仓库,而下面这种方式是直接设置了镜像仓库,所以每次安装的时候不需要再去手动指定
$ npm config set registry http://registry.npm.taobao.org

上面的操作完成之后进入elasticsearch-head插件目录内,然后安装插件
安装插件
$ npm install
等着上面跑完就完成了
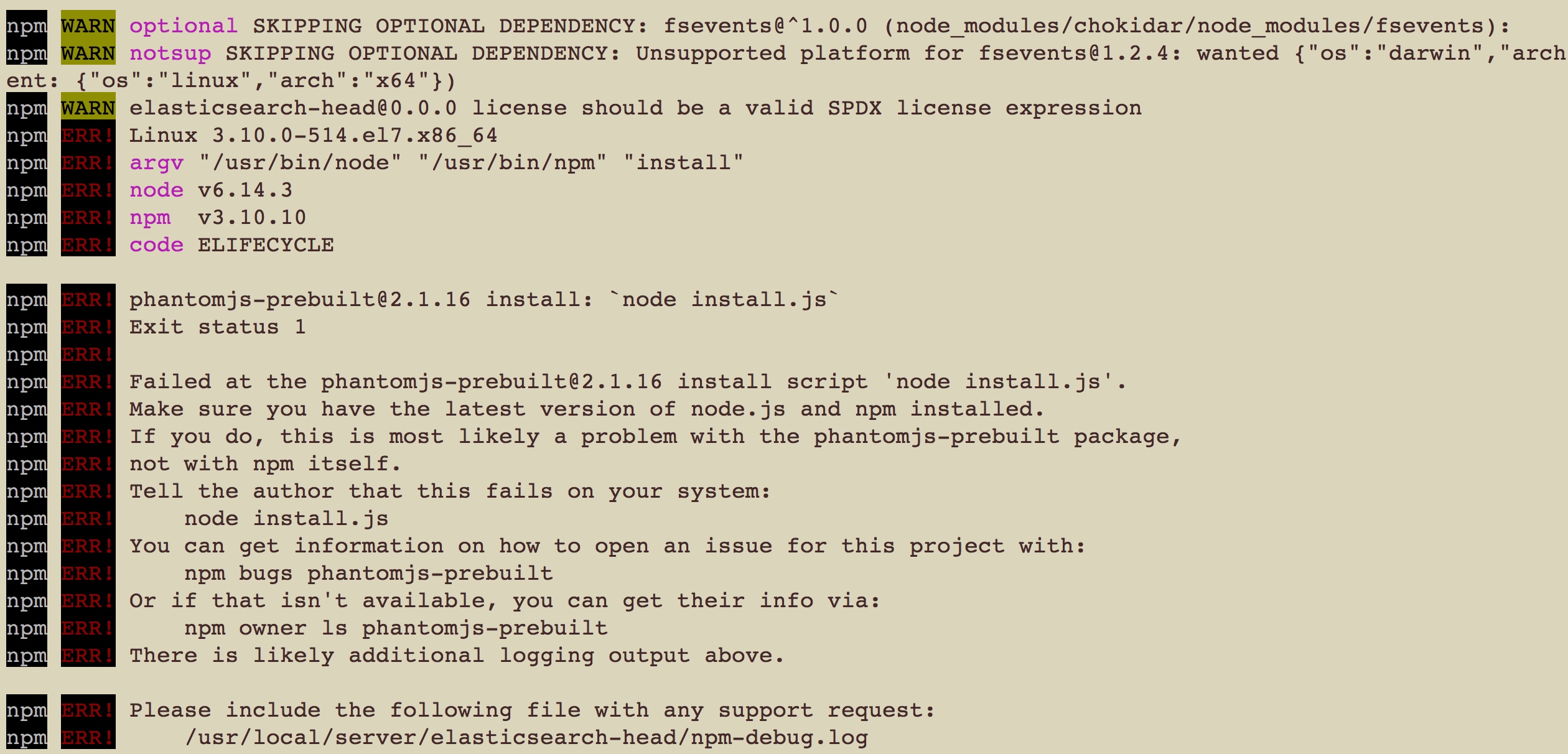
很尴尬的是报错了,看下是由于什么引起的报错
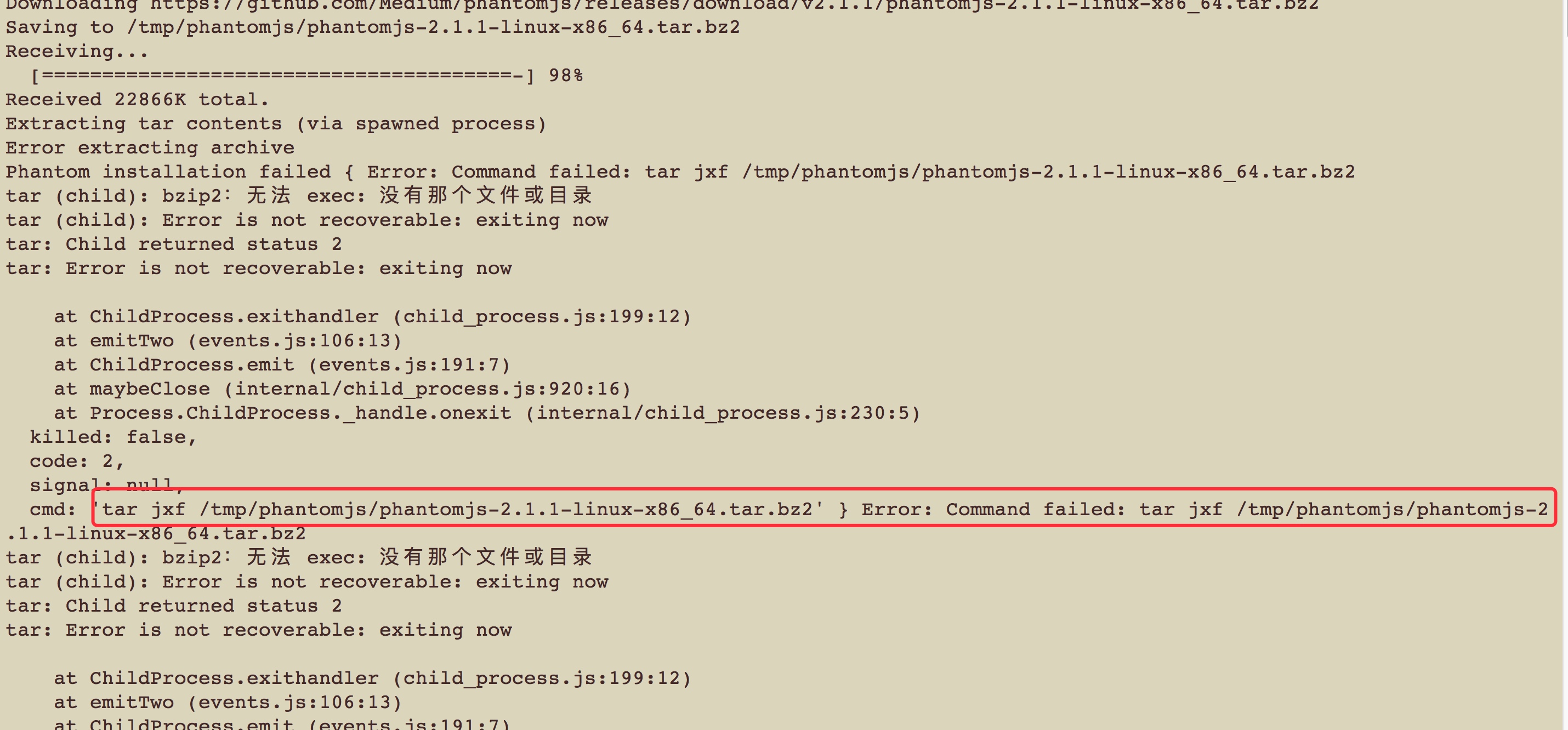
看上面的信息是因为下载了一个文件phantomjs-2.1.1-linux-x86_64.tar.bz2这个文件在/tmp/phantomjs/这个目录下面,然后它使用tar -jxf来解压出错了,既然是这样,那我们自己手动帮他解压一下吧
解压tar.bz2需要安装bzip2解压软件,然后再进行解压
$ yum install -y bzip2
$ bzip2 -d phantomjs-2.1.1-linux-x86_64.tar.bz2

解压完成之后可以看到tar.bz2编程了tar
这个时候再帮他吧这个解压了吧
$ tar -vxf phantomjs-2.1.1-linux-x86_64.tar

然后再回到elasticsearch-head插件进行重新安装
$ npm install
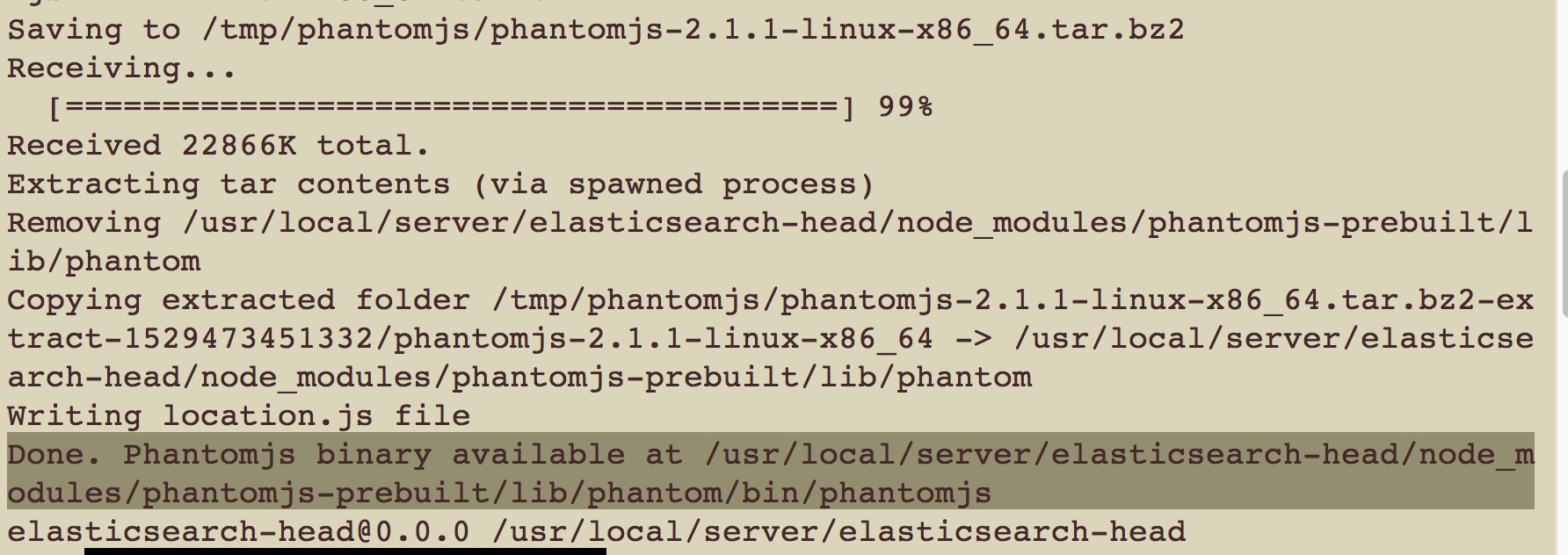
可以看到我们帮他解压了,之后之前的错误没了
上面的安装完成之后进行下面的内容设置,下面进行设置elasticsearch-head和elasticsearch-head进行整合的配置,需要去配置elasticsearch-head的相关设置
1、设置
/elasticsearch-head/Gruntfile.js文件
connect: {
server: {
options: {
hostname: '192.168.56.61',
port: 9100,
base: '.',
keepalive: true
}
}
}
如上配置是设置我们需要监控的机器hostname
2、设置
/elasticsearch-head/_site/app.js文件
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200";
全局搜索如下内容将其修改为如下内容
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://192.168.56.61:9200";
这里将localhost修改成你安装elasticsearch-head所在机器的ip,我这里安装在192.168.56.61这台机子上的
3、设置
elasticsearch所有相关节点,让这些节点支持跨域请求
在所有的elasticsearch机器上面修改elasticsearch.yml文件如下,增加如下内容
# 是否支持跨域
http.cors.enabled: true
# *表示支持所有域名
http.cors.allow-origin: "*"
我这边已经设置完成,我在三台机子上面都已经设置了,不设置的话elasticsearch.head是不能请求到其他三个节点的接口的,因为跨域问题
上面的这三个设置设置完成之后,尝试启动elasticsearch-head
在elasticsearch-head目录下使用该命令进行启动,我这里使用的是root用户,因为安装也是用root进行安装的
$ npm run start
下面这种方式是后台启动
/usr/local/server/elasticsearch-head/node_modules/grunt/bin/grunt server &
启动之后看到如下结果:
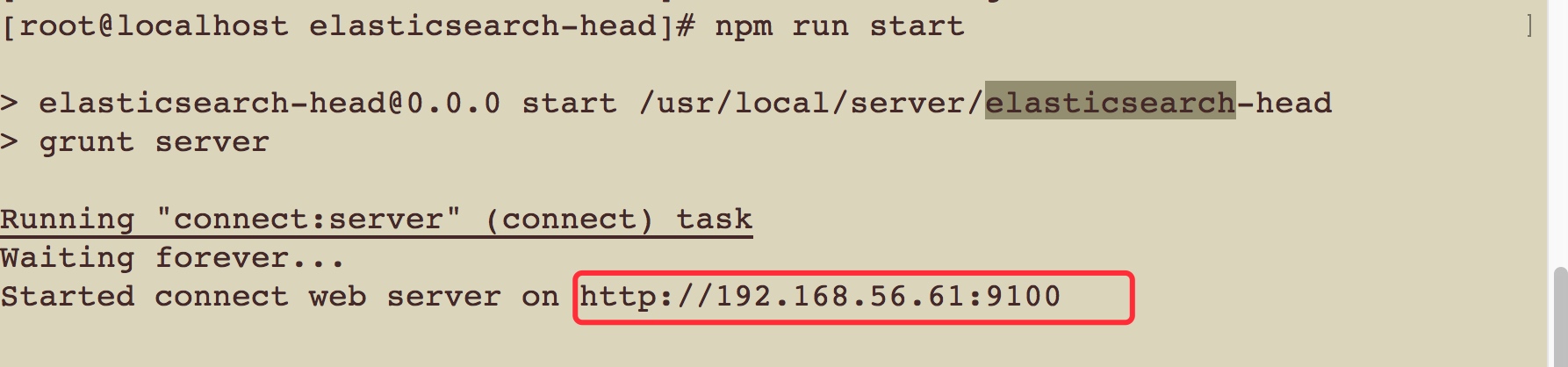
说明启动成功
在浏览器中访问这个地址,如下内容

我们就能通过在web页面上进行管理我们的集群情况,我们能够查询搜索elasticsearch中的数据信息,后面会专门写这部分的内容,这里就只是做一个简单的介绍,具体怎么使用后面再说!哎,又给自己挖了个坑!坑太多,都怕自己填不过来啊!慢慢填吧。。。。。。。
elasticsearch-head这个插件只需要安装在一台上就可以了,他就能够链接到其他集群的机子!
五、安装Kibana
这个也是一个标配了,使用elasticsearch的,Kibana也是一个工具了,同样也是给我们提供了操作elasticsearch的一些工具,同时能够根据elasticsearch的数据给我们生成一些图标啊,统计图啊,地图啊等等东西!
来吧,继续安装吧,因为之前我把elasticsearch-head安装在了192.168.56.61这台机子上,那么我Kibana也就安装在这台机子上吧!
官方下载地址:https://www.elastic.co/cn/downloads/kibana
这里我把下载好的文件放在这里了
解压,然后把这个文件分配在elc用户和用户组权限下
$ tar -xvf kibana-6.3.0-linux-x86_64.tar
$ chown -R elc:elc kibana-6.3.0-linux-x86_64
kibana的安装非常简单的,毕竟是官方出的东西
下面进行修改kibana的配置文件,在kibana解压出来的目录中config/kibana.yml中进行修改
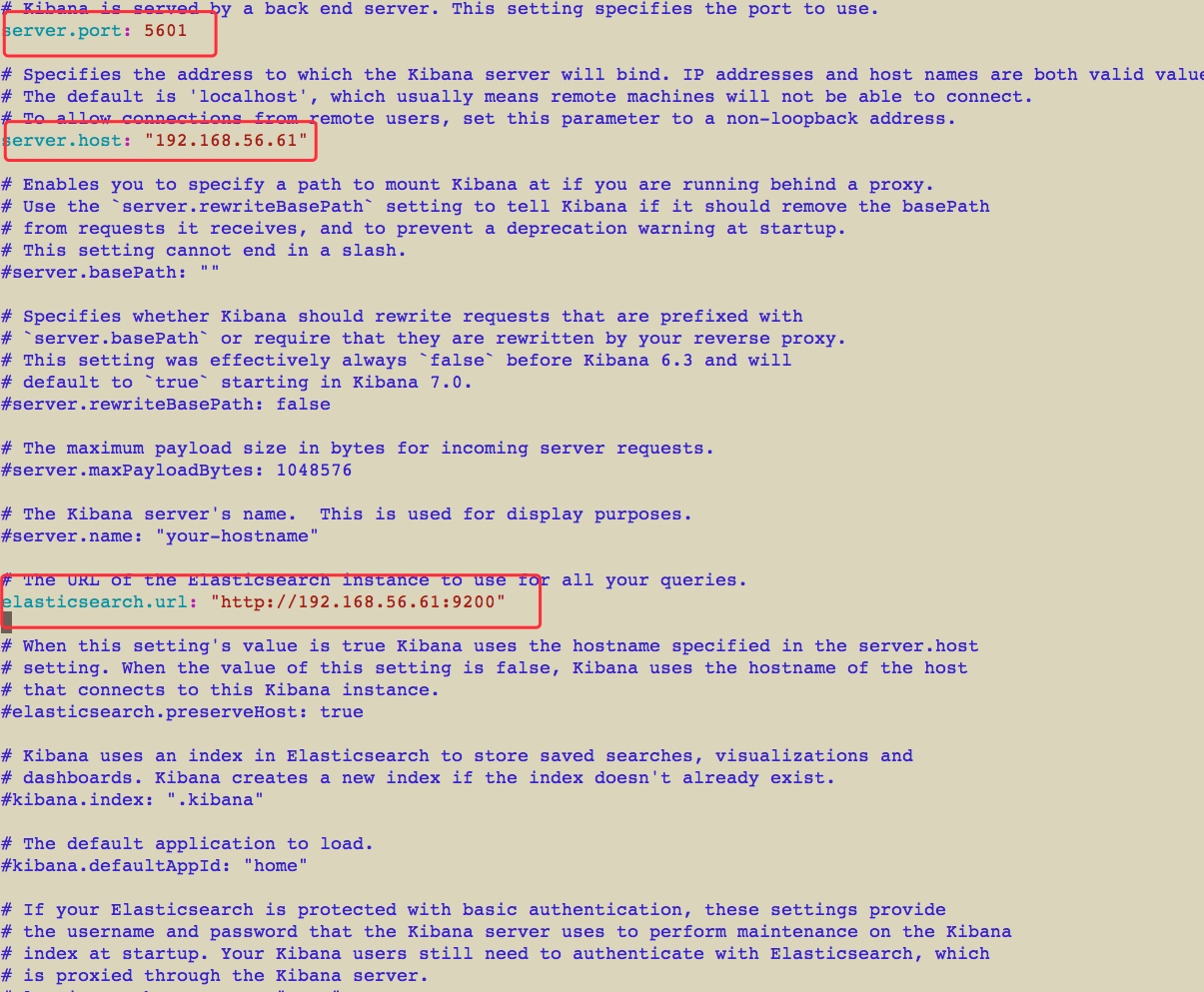
暂时修改这三个就足够了,吧ip配成安装的这台的ip就可以了,配成其他另外两台的也是可以的但是server.host这个还是配置成安装的机器的ip
然后就可以尝试启动了
$ ./bin/kibana

启动成功,现在就去访问kibana吧
http://192.168.56.61:5601
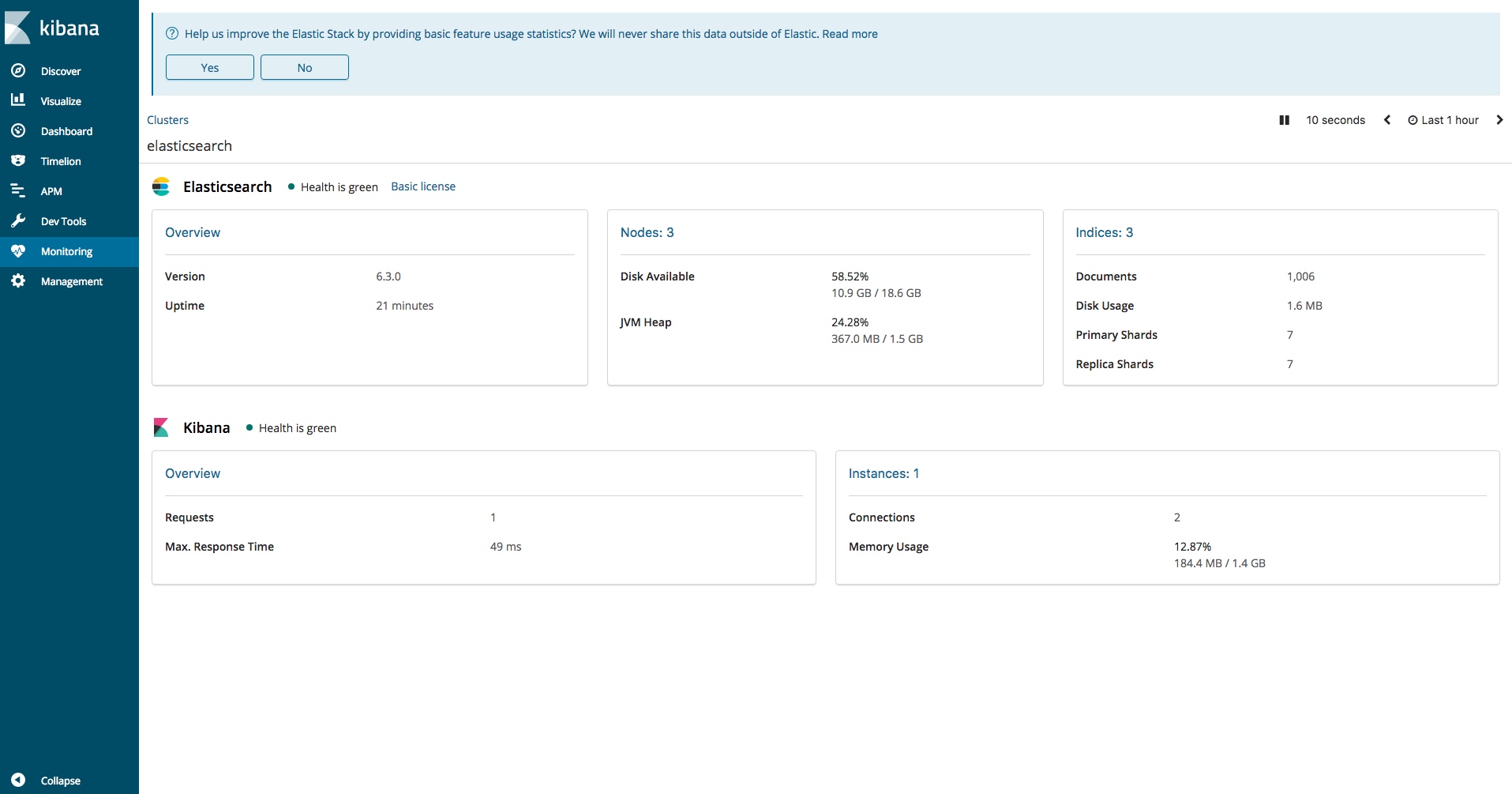
能够访问到,也能够看到我们集群的状态
kibana是一个数据可视化平台,有非常多的功能值得去探索和使用,在大数据数据分析方面还是非常有用的!安装非常简单!至于怎么去使用后面再来进行详细的探索吧!