数据来源:爬取UCI公开心脏病数据集
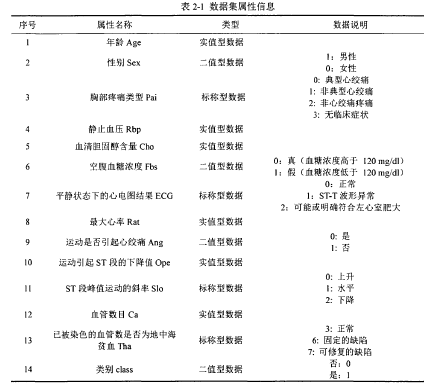
对于非数值型特征,需要对其进行数值类型的转换。在原始数据中,大部分的数据类型是字符串,对非实值型数据(字符串数值类型),需要进行数值类型的转换,即根据每个字段的含义将其转化为对应的数值。对于二值类的数据,例如在性别的特征中,包含男性和女性两种取值,可以将女性映射为0,男性映射为1。对于多值型属性,比如在胸部疼痛类型的数据特征中,可以通过疼痛由重到轻将其映射成0-3的数值,典型的心绞痛映射为0,非典型的心绞痛映射为1,非心绞痛疼痛映射为2,无临床症状映射为3。
选出13个属性特征和1个类别特征后,用于实验的数据csv文件部分展示如下:
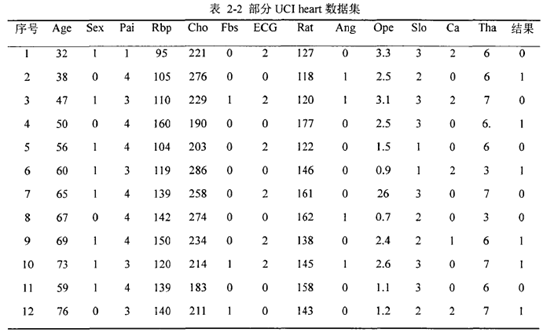
特征属性包含实值型、二值型、标称型三类,分别作不同处理。
数据预处理:
不同的特征具有不一样的量纲,不同特征的尺寸和规格有可能存在不一致的情况,因此,实值型数据需要归一化。
import pandas as pd data = pd.read_csv(r'D:\Heart.csv') # 开始进行数据处理【没有缺失值】 normal = [1, 4, 5, 8, 10, 12, 11] # 标准化处理 one_hot = [3, 7, 13] # one_hot编码 binary = [14] # 原始类别为1的依然为1类,原始为2的变为0类 #数据处理 def trans(exdata, nor=normal, oh=one_hot, bin=binary): keylist = exdata.keys() newexdata = pd.DataFrame() for ikey in range(len(keylist)): if ikey + 1 in nor: newexdata[keylist[ikey]] = (exdata[keylist[ikey]] - exdata[keylist[ikey]].mean()) / exdata[keylist[ikey]].std() elif ikey + 1 in bin: newexdata[keylist[ikey]] = [1 if inum == 1 else 0 for inum in exdata[keylist[ikey]]] elif ikey + 1 in oh: newdata = pd.get_dummies(exdata[keylist[ikey]], prefix=keylist[ikey]) newexdata = pd.concat([newexdata,newdata], axis=1) return newexdata Data = trans(data).values x_pre_data = Data[:, :-1] y_data = Data[:, -1].reshape(-1, 1) #最终的可用于算法的数据 model_data = [x_pre_data, y_data]
Logistic Regression:
简单说说我理解的逻辑回归用于分类的原理,有个函数叫sigmoid函数y=1/(1+(exp(-x))),它能把R映射到(0,1),像极了概率值应该满足的条件,因此,输入就是特征的线性变换wx+b,输出是由这些特征判定为某一类的概率值。综合正,负类,损失函数L=p(0)p(1)=p(1)[1-p(1)],梯度下降法等迭代求使损失函数取得最小值时的参数w,b。参数确定下来了,表示模型就训练好了,再来一个新样本,输入特征X,就可以知道应该被分为哪一类。
Support Vector Machines:
支持向量机,就是在样本空间里找到能划分正负样本的一个支撑面,为了让正负样本更易区分,就需要让这个间隔越大越好(倒数越小越好),像特征维度比较多的时候,求解就有点复杂,什么拉格朗日乘子法,KKT条件,对偶条件,核函数(已劝退了)。
当然,什么复杂的模型实现,用sklearn就import就好了,不过听说现在招算法要手推这些哦。害,趁早改行。
算法评价:
正样本分正确TP(True Positive),正样本分错FP,负样本分对TN,负样本分错FN
准确率Accuracy=(TP+TN)/ALL,精确率Precision=TP/(TP+FP),召回率Recall=TP/(TP+FN),F1-Measure=2*Precision*Recall/(Precision+Recall)
此外还有TPR=TP/(TP+FN),TFR=FP/(FP+TN),以此为坐标画的线叫ROC曲线(如下图所示),曲线下面积AUC越接近1表示算法性能越好。

算法评价也可以用sklearn.metrics来实现
from Heart_Data import model_data as H_Data from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score,f1_score,roc_auc_score,recall_score,precision_score sklr = LogisticRegression(penalty='l2', tol=10, solver='lbfgs',max_iter=9000) regre = sklr.fit(H_Data[0], H_Data[1].T[0]) predata = sklr.predict(H_Data[0]) acc_score = accuracy_score(H_Data[1].T[0],predata) roc_auc_score1 = roc_auc_score(H_Data[1].T[0],predata) reca_score = recall_score(H_Data[1].T[0],predata) prec_score = precision_score(H_Data[1].T[0],predata) f1_score1 = f1_score(H_Data[1].T[0],predata) print('acc: ', acc_score) print('reca: ', reca_score) print('f1: ', f1_score1) print('prec: ', prec_score) print('auc: ', roc_auc_score1)
from sklearn.metrics import accuracy_score,f1_score,roc_auc_score,recall_score,precision_score from sklearn import svm import SVM_Classify_Data as sdata def sk_svm_train(intr, labeltr, inte, labelte, kener): clf = svm.SVC(kernel=kener) # 开始训练 clf.fit(intr, labeltr) predata=clf.predict(inte) acc_test = accuracy_score(labelte,predata) auc_test = roc_auc_score(labelte,predata) rec_test = recall_score(labelte,predata) pre_test = precision_score(labelte,predata) f1_test = f1_score(labelte,predata) return acc_test, auc_test,rec_test,pre_test,f1_test def result(datadict, he='rbf'): testacc,testauc,testrec,testpre,testf1 = [],[],[],[],[] resu = [] for jj in datadict: # 训练数据 xd = datadict[jj][0][:, :-1] yd = datadict[jj][0][:, -1] # 测试数据 texd = datadict[jj][1][:, :-1] teyd = datadict[jj][1][:, -1] # 开始训练 resu = sk_svm_train(xd, yd, texd, teyd, he) testacc.append(resu[0]) testauc.append(resu[1]) testrec.append(resu[2]) testpre.append(resu[3]) testf1.append(resu[4]) acc=sum(testacc)/len(testacc) auc=sum(testauc)/len(testauc) rec=sum(testrec)/len(testrec) pre=sum(testpre)/len(testpre) f1=sum(testf1)/len(testf1) print("acc:",acc) print("auc:",auc) print("rec:",rec) print("pre:",pre) print("f1:",f1) if __name__ == "__main__": result(sdata.kfold_train_datadict, he='rbf')
注:SVM数据处理方面有点不同,把数据分成十份,做10-fold交叉验证,所以最后是用列表储存十次的结果再求个平均。
10份的训练集,测试集准确率如图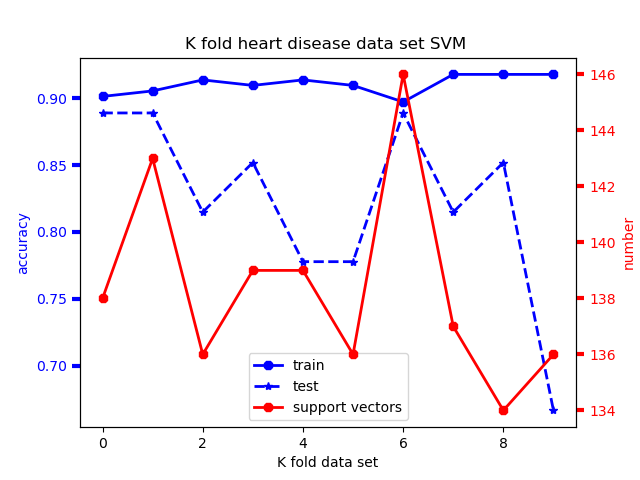
最后的实验结果

参考
总结:
遇到一个很蠢的问题,在Anfany的代码里SVM只用了clf.score(intrain,labeltrain)求准确率,为了求其他指标,我使用clf.accuracy_score(intrain,labeltrain)提示SVC对象没有accuracy_score方法。直接用accuracy_score(intrain,labeltrain)也不行。后来顿悟了。第一,分类器一般都有score方法,和准确率是一个意思,参数.score(X,y);第二,引入sklearn.metrics后有accuracy_score等方法,独立使用,注意参数是accuracy_score(y,y_prediction),y_prediction要通过clf.predict(X)求得。