最近在看论文,因为论文都是全英文的,所以需要论文查看的软件,在macOS上找到一款很好用的软件叫做知云文献翻译
知云文献翻译
界面长这样,可以长段翻译,总之很不错
它的下载地址是:https://www.yuque.com/xtranslator/zy/

百度翻译API申请
使用自己的api有两个好处:
一、更加稳定
二、可以自定义词库,我看的是医疗和机器学习相关的英文文献,可以自定义
api申请
先进入api申请官网:https://api.fanyi.baidu.com/
在上方控制台、根据流程申请后
可以在这里看到自己的ID和密钥
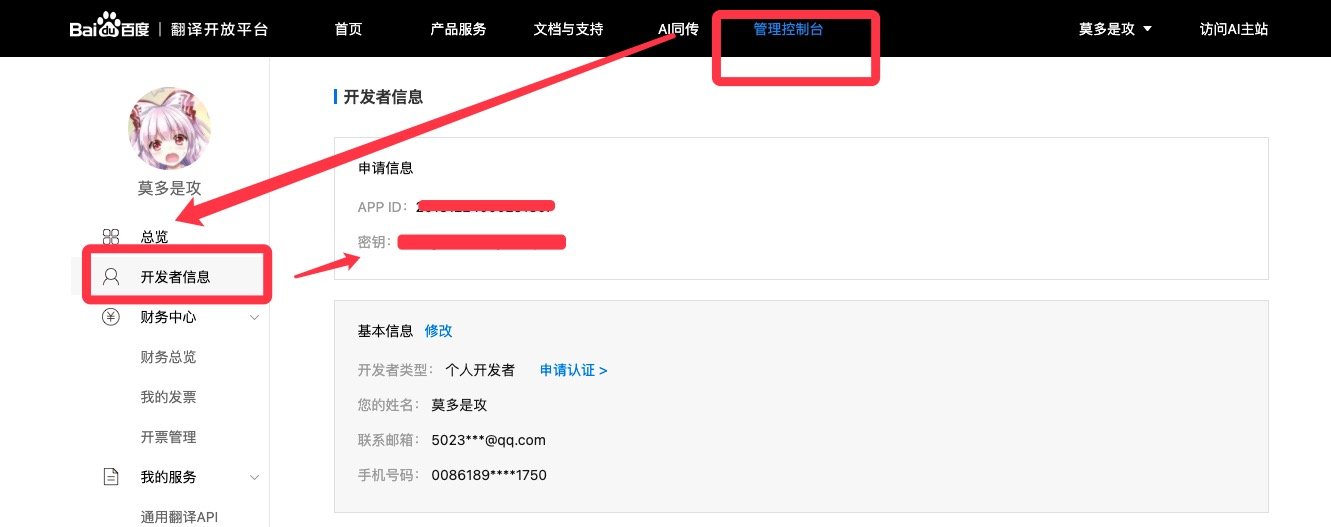
填入就可以了
自定义术语库

我看的是机器学习的文献,因此在术语库里添加,导入文件(我会把文本放在后面

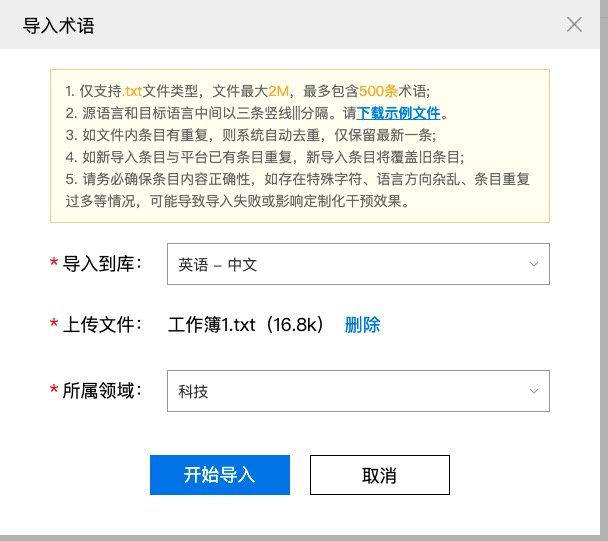
导入后完成,有部分词语不翻译,比如MNIST这样的专有词语,就会报错,忽略掉就可以了
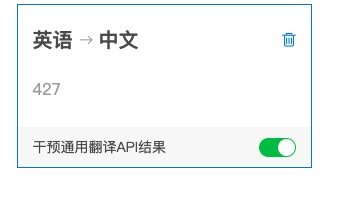
开启术语库就行了
术语库的资料来源:https://www.aminer.cn/ml_taxonomy
机器学习术语库
Supervised Learning|||监督学习
Unsupervised Learning|||无监督学习
Semi-supervised Learning|||半监督学习
Reinforcement Learning|||强化学习
Active Learning|||主动学习
Online Learning|||在线学习
Transfer Learning|||迁移学习
Automated Machine Learning (AutoML)|||自动机器学习
Representation Learning|||表示学习
Minkowski distance|||闵可夫斯基距离
Gradient Descent|||梯度下降
Stochastic Gradient Descent|||随机梯度下降
Over-fitting|||过拟合
Regularization|||正则化
Cross Validation|||交叉验证
Perceptron|||感知机
Logistic Regression|||逻辑回归
Maximum Likelihood Estimation|||最大似然估计
Newton’s method|||牛顿法
K-Nearest Neighbor|||K近邻法
Mahanalobis Distance|||马氏距离
Decision Tree|||决策树
Naive Bayes Classifier|||朴素贝叶斯分类器
Generalization Error|||泛化误差
PAC Learning|||概率近似正确学习
Empirical Risk Minimization|||经验风险最小化
Growth Function|||成长函数
VC-dimension|||VC维
Structural Risk Minimization|||结构风险最小化
Eigendecomposition|||特征分解
Singular Value Decomposition|||奇异值分解
Moore-Penrose Pseudoinverse|||摩尔-彭若斯广义逆
Marginal Probability|||边缘概率
Conditional Probability|||条件概率
Expectation|||期望
Variance|||方差
Covariance|||协方差
Critical points|||临界点
Support Vector Machine|||支持向量机
Decision Boundary|||决策边界
Convex Set|||凸集
Lagrange Duality|||拉格朗日对偶性
KKT Conditions|||KKT条件
Coordinate ascent|||坐标下降法
Sequential Minimal Optimization (SMO)|||序列最小化优化
Ensemble Learning|||集成学习
Bootstrap Aggregating (Bagging)|||装袋算法
Random Forests|||随机森林
Boosting|||提升方法
Stacking|||堆叠方法
Decision Tree|||决策树
Classification Tree|||分类树
Adaptive Boosting (AdaBoost)|||自适应提升
Decision Stump|||决策树桩
Meta Learning|||元学习
Gradient Descent|||梯度下降
Deep Feedforward Network (DFN)|||深度前向网络
Backpropagation|||反向传播
Activation Function|||激活函数
Multi-layer Perceptron (MLP)|||多层感知机
Perceptron|||感知机
Mean-Squared Error (MSE)|||均方误差
Chain Rule|||链式法则
Logistic Function|||逻辑函数
Hyperbolic Tangent|||双曲正切函数
Rectified Linear Units (ReLU)|||整流线性单元
Residual Neural Networks (ResNet)|||残差神经网络
Regularization|||正则化
Overfitting|||过拟合
Data(set) Augmentation|||数据增强
Parameter Sharing|||参数共享
Ensemble Learning|||集成学习
Dropout|||
L2 Regularization|||L2正则化
Taylor Series Approximation|||泰勒级数近似
Taylor Expansion|||泰勒展开
Bayesian Prior|||贝叶斯先验
Bayesian Inference|||贝叶斯推理
Gaussian Prior|||高斯先验
Maximum-a-Posteriori (MAP)|||最大后验
Linear Regression|||线性回归
L1 Regularization|||L1正则化
Constrained Optimization|||约束优化
Lagrange Function|||拉格朗日函数
Denoising Autoencoder|||降噪自动编码器
Label Smoothing|||标签平滑
Eigen Decomposition|||特征分解
Convolutional Neural Networks (CNNs)|||卷积神经网络
Semi-Supervised Learning|||半监督学习
Generative Model|||生成模型
Discriminative Model|||判别模型
Multi-Task Learning|||多任务学习
Bootstrap Aggregating (Bagging)|||装袋算法
Multivariate Normal Distribution|||多元正态分布
Sparse Parametrization|||稀疏参数化
Sparse Representation|||稀疏表示
Student-t Prior|||学生T先验
KL Divergence|||KL散度
Orthogonal Matching Pursuit (OMP)|||正交匹配追踪算法
Adversarial Training|||对抗训练
Matrix Factorization (MF)|||矩阵分解
Root-Mean-Square Error (RMSE)|||均方根误差
Collaborative Filtering (CF)|||协同过滤
Nonnegative Matrix Factorization (NMF)|||非负矩阵分解
Singular Value Decomposition (SVD)|||奇异值分解
Latent Sematic Analysis (LSA)|||潜在语义分析
Bayesian Probabilistic Matrix Factorization (BPMF)|||贝叶斯概率矩阵分解
Wishart Prior|||Wishart先验
Sparse Coding|||稀疏编码
Factorization Machines (FM)|||分解机
second-order method|||二阶方法
cost function|||代价函数
training set|||训练集
objective function|||目标函数
expectation|||期望
data generating distribution|||数据生成分布
empirical risk minimization|||经验风险最小化
generalization error|||泛化误差
empirical risk|||经验风险
overfitting|||过拟合
feasible|||可行
loss function|||损失函数
derivative|||导数
gradient descent|||梯度下降
surrogate loss function|||代理损失函数
early stopping|||提前终止
Hessian matrix|||黑塞矩阵
second derivative|||二阶导数
Taylor series|||泰勒级数
Ill-conditioning|||病态的
critical point|||临界点
local minimum|||局部极小点
local maximum|||局部极大点
saddle point|||鞍点
local minima|||局部极小值
global minimum|||全局最小点
convex function|||凸函数
weight space symmetry|||权重空间对称性
Newton’s method|||牛顿法
activation function|||激活函数
fully-connected networks|||全连接网络
Resnet|||残差神经网络
gradient clipping|||梯度截断
recurrent neural network|||循环神经网络
long-term dependency|||长期依赖
eigen-decomposition|||特征值分解
feedforward network|||前馈网络
vanishing and exploding gradient problem|||梯度消失与爆炸问题
contrastive divergence|||对比散度
validation set|||验证集
stochastic gradient descent|||随机梯度下降
learning rate|||学习速率
momentum|||动量
gradient descent|||梯度下降
poor conditioning|||病态条件
nesterov momentum|||Nesterov 动量
partial derivative|||偏导数
moving average|||移动平均
quadratic function|||二次函数
positive definite|||正定
quasi-newton method|||拟牛顿法
conjugate gradient|||共轭梯度
steepest descent|||最速下降
reparametrization|||重参数化
standard deviation|||标准差
coordinate descent|||坐标下降
skip connection|||跳跃连接
convolutional neural network|||卷积神经网络
convolution|||卷积
pooling|||池化
feedforward neural network|||前馈神经网络
maximum likelihood|||最大似然
back propagation|||反向传播
artificial neural network|||人工神经网络
deep feedforward network|||深度前馈网络
hyperparameter|||超参数
sparse connectivity|||稀疏连接
parameter sharing|||参数共享
receptive field|||接受域
chain rule|||链式法则
tiled convolution|||平铺卷积
object detection|||目标检测
error rate|||错误率
activation function|||激活函数
overfitting|||过拟合
attention mechanism|||注意力机制
transfer learning|||迁移学习
autoencoder|||自编码器
unsupervised learning|||无监督学习
back propagation|||反向传播
pretraining|||预训练
dimensionality reduction|||降维
curse of dimensionality|||维数灾难
feedforward neural network|||前馈神经网络
encoder|||编码器
decoder|||解码器
cross-entropy|||交叉熵
tied weights|||绑定的权重
PCA|||PCA
principal component analysis|||主成分分析
singular value decomposition|||奇异值分解
SVD|||SVD
singular value|||奇异值
reconstruction error|||重构误差
covariance matrix|||协方差矩阵
Kullback-Leibler (KL) divergence|||KL散度
denoising autoencoder|||去噪自编码器
sparse autoencoder|||稀疏自编码器
contractive autoencoder|||收缩自编码器
conjugate gradient|||共轭梯度
fine-tune|||精调
local optima|||局部最优
posterior distribution|||后验分布
gaussian distribution|||高斯分布
reparametrization|||重参数化
recurrent neural network|||循环神经网络
artificial neural network|||人工神经网络
feedforward neural network|||前馈神经网络
sentiment analysis|||情感分析
machine translation|||机器翻译
pos tagging|||词性标注
teacher forcing|||导师驱动过程
back-propagation through time|||通过时间反向传播
directed graphical model|||有向图模型
speech recognition|||语音识别
question answering|||问答系统
attention mechanism|||注意力机制
vanishing and exploding gradient problem|||梯度消失与爆炸问题
jacobi matrix|||jacobi矩阵
long-term dependency|||长期依赖
clip gradient|||梯度截断
long short-term memory|||长短期记忆
gated recurrent unit|||门控循环单元
hadamard product|||Hadamard乘积
back propagation|||反向传播
attention mechanism|||注意力机制
feedforward network|||前馈网络
named entity recognition|||命名实体识别
Representation Learning|||表征学习
Distributed Representation|||分布式表征
Multi-task Learning|||多任务学习
Multi-Modal Learning|||多模态学习
Semi-supervised Learning|||半监督学习
NLP|||自然语言处理
Neural Language Model|||神经语言模型
Neural Probabilistic Language Model|||神经概率语言模型
RNN|||循环神经网络
Neural Tensor Network|||神经张量网络
Graph Neural Network|||图神经网络
Graph Covolutional Network (GCN)|||图卷积网络
Graph Attention Network|||图注意力网络
Self-attention|||自注意力机制
Feature Learning|||表征学习
Feature Engineering|||特征工程
One-hot Representation|||独热编码
Speech Recognition|||语音识别
DBM|||深度玻尔兹曼机
Zero-shot Learning|||零次学习
Autoencoder|||自编码器
Generative Adversarial Network(GAN)|||生成对抗网络
Approximate Inference|||近似推断
Bag-of-Words Model|||词袋模型
Forward Propagation|||前向传播
Huffman Binary Tree|||霍夫曼二叉树
NNLM|||神经网络语言模型
N-gram|||N元语法
Skip-gram Model|||跳元模型
Negative Sampling|||负采样
CBOW|||连续词袋模型
Knowledge Graph|||知识图谱
Relation Extraction|||关系抽取
Node Embedding|||节点嵌入
Graph Neural Network|||图神经网络
Node Classification|||节点分类
Link Prediction|||链路预测
Community Detection|||社区发现
Isomorphism|||同构
Random Walk|||随机漫步
Spectral Clustering|||谱聚类
Asynchronous Stochastic Gradient Algorithm|||异步随机梯度算法
Negative Sampling|||负采样
Network Embedding|||网络嵌入
Graph Theory|||图论
multiset|||多重集
Perron-Frobenius Theorem|||佩龙—弗罗贝尼乌斯定理
Stationary Distribution|||稳态分布
Matrix Factorization|||矩阵分解
Sparsification|||稀疏化
Singular Value Decomposition|||奇异值分解
Frobenius Norm|||F-范数
Heterogeneous Network|||异构网络
Graph Convolutional Network (GCN)|||图卷积网络
CNN|||卷积神经网络
Semi-Supervised Classification|||半监督分类
Chebyshev polynomial|||切比雪夫多项式
Gradient Exploding|||梯度爆炸
Gradient Vanishing|||梯度消失
Batch Normalization|||批标准化
Neighborhood Aggregation|||邻域聚合
LSTM|||长短期记忆网络
Graph Attention Network|||图注意力网络
Self-attention|||自注意力机制
Rescaling|||再缩放
Attention Mechanism|||注意力机制
Jensen-Shannon Divergence|||JS散度
Cognitive Graph|||认知图谱
Generative Adversarial Network(GAN)|||生成对抗网络
Generative Model|||生成模型
Discriminative Model|||判别模型
Gaussian Mixture Model|||高斯混合模型
Variational Auto-Encoder(VAE)|||变分编码器
Markov Chain|||马尔可夫链
Boltzmann Machine|||玻尔兹曼机
Kullback–Leibler divergence|||KL散度
Vanishing Gradient|||梯度消失
Surrogate Loss|||替代损失
Mode Collapse|||模式崩溃
Earth-Mover/Wasserstein-1 Distance|||搬土距离/EMD
Lipschitz Continuity|||利普希茨连续
Feedforward Network|||前馈网络
Minimax Game|||极小极大博弈
Adversarial Learning|||对抗学习
Outlier|||异常值/离群值
Rectified Linear Unit|||线性修正单元
Logistic Regression|||逻辑回归
Softmax Regression|||Softmax回归
SVM|||支持向量机
Decision Tree|||决策树
Nearest Neighbors|||最近邻
White-box|||白盒(测试 etc. )
Lagrange Multiplier|||拉格朗日乘子
Black-box|||黑盒(测试 etc. )
Robustness|||鲁棒性/稳健性
Decision Boundary|||决策边界
Non-differentiability|||不可微
Intra-technique Transferability|||相同技术迁移能力
Cross-technique Transferability|||不同技术迁移能力
Data Augmentation|||数据增强
Adaboost|||
recommender system|||推荐系统
Probability matching|||概率匹配
minimax regret|||
face detection|||人脸检测
i.i.d.|||独立同分布
Minimax|||极大极小
linear model|||线性模型
Thompson Sampling|||汤普森抽样
eigenvalues|||特征值
optimization problem|||优化问题
greedy algorithm|||贪心算法
Dynamic Programming|||动态规划
lookup table|||查找表
Bellman equation|||贝尔曼方程
discount factor|||折现系数
Reinforcement Learning|||强化学习
gradient theorem|||梯度定理
stochastic gradient descent|||随机梯度下降法
Monte Carlo|||蒙特卡罗方法
function approximation|||函数逼近
Markov Decision Process|||马尔可夫决策过程
Bootstrapping|||引导
Shortest Path Problem|||最短路径问题
expected return|||预期回报
Q-Learning|||Q学习
temporal-difference learning|||时间差分学习
AlphaZero|||
Backgammon|||西洋双陆棋
finite set|||有限集
Markov property|||马尔可夫性质
sample complexity|||样本复杂性
Cartesian product|||笛卡儿积
Kevin Leyton-Brown|||
SVM|||支持向量机
MNIST|||
ImageNet|||
Ensemble learning|||集成学习
Neural networks|||神经网络
Neuroevolution|||神经演化
object recognition|||目标识别
Multi-task learning|||多任务学习
Treebank|||树图资料库
covariance|||协方差
Hamiltonian Monte Carlo|||哈密顿蒙特卡罗
Inductive bias|||归纳偏置
bilevel optimization|||双层规划
genetic algorithms|||遗传算法
Bayesian linear regression|||贝叶斯线性回归
ANOVA|||方差分析
Extrapolation|||外推法
activation function|||激活函数
CIFAR-10|||
Gaussian Process|||高斯过程
k-nearest neighbors|||K最近邻
Neural Turing machine|||神经图灵机
MCMC|||马尔可夫链蒙特卡罗
Collaborative filtering|||协同过滤
AlphaGo|||
random forests|||随机森林
multivariate Gaussian|||多元高斯
Bayesian Optimization|||贝叶斯优化
meta-learning|||元学习
iterative algorithm|||迭代算法
Viterbi algorithm|||维特比算法
Gibbs distribution|||吉布斯分布
Discriminative model|||判别模型
Maximum Entropy Markov Model|||最大熵马尔可夫模型
Information Extraction|||信息提取
clique|||小圈子
conditional random field|||条件随机场
CRF|||条件随机场
triad|||三元关系
Naïve Bayes|||朴素贝叶斯
social network|||社交网络
Bayesian network|||贝叶斯网络
SVM|||支持向量机
Joint probability distribution|||联合概率分布
Conditional independence|||条件独立性
sequence analysis|||序列分析
Perceptron|||感知器
Markov Blanket|||马尔科夫毯
Hidden Markov Model|||隐马尔可夫模型
finite-state|||有限状态
Shallow parsing|||浅层分析
Active learning|||主动学习
Speech recognition|||语音识别
convex|||凸
transition matrix|||转移矩阵
factor graph|||因子图
forward-backward algorithm|||前向后向算法
parsing|||语法分析
structural holes|||结构洞
graphical model|||图模型
Markov Random Field|||马尔可夫随机场
Social balance theory|||社会平衡理论
Generative model|||生成模型
probalistic topic model|||概率语义模型
TFIDF|||词频-文本逆向频率
LSI|||潜在语义索引
Bayesian network|||贝叶斯网络模型
Markov random field|||马尔科夫随机场
restricted boltzmann machine|||限制玻尔兹曼机
LDA|||隐式狄利克雷分配模型
PLSI|||概率潜在语义索引模型
EM algorithm|||最大期望算法
Gibbs sampling|||吉布斯采样法
MAP (Maximum A Posteriori)|||最大后验概率算法
Markov Chain Monte Carlo|||马尔科夫链式蒙特卡洛算法
Monte Carlo Sampling|||蒙特卡洛采样法
Univariate|||单变量
Hoeffding Bound|||Hoeffding界
Chernoff Bound|||Chernoff界
Importance Sampling|||加权采样法
invariant distribution|||不动点分布
Metropolis-Hastings algorithm|||Metropolis-Hastings算法
Probablistic Inference|||概率推断
Variational Inference|||变量式推断
HMM|||隐式马尔科夫模型
mean field|||平均场理论
mixture model|||混合模型
convex duality|||凸对偶
belief propagation|||置信传播算法
non-parametric model|||非参模型
Gaussian process|||正态过程
multivariate Gaussian distribution|||多元正态分布
Dirichlet process|||狄利克雷过程
stick breaking process|||断棒过程
Chinese restaurant process|||中餐馆过程
Blackwell-MacQueen Urn Scheme|||Blackwell-MacQueen桶法
De Finetti's theorem|||de Finetti定理
collapsed Gibbs sampling|||下陷吉布斯采样法
Hierarchical Dirichlet process|||阶梯式狄利克雷过程
Indian Buffet process|||印度餐馆过程