新手才开始写博客,不周之处请原谅,有错误请指正。
>>> a = [1,4,2,5,3]
>>> b = sorted(enumerate(a),key = lambda x:x[1])
>>> b
[(0, 1), (2, 2), (4, 3), (1, 4), (3, 5)]
>>> b[1]
(2, 2)
>>> b[1][1]
2
>>> b[1][0]
2
b = sorted(enumerate(a),key = lambda x:x[1],reverse = False)
这儿可以加第三个参数,reverse = True按降序排列,reverse = False按升序排列
关于enumerate()使用方法(copy来的)
enumerate()说明
- enumerate()是python的内置函数
- enumerate在字典上是枚举、列举的意思
- 对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
- enumerate多用于在for循环中得到计数
-
例如对于一个seq,得到:
(0, seq[0]), (1, seq[1]), (2, seq[2]) - enumerate()返回的是一个enumerate对象,例如:
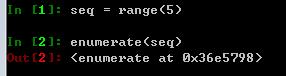
enumerate()使用
- 如果对一个列表,既要遍历索引又要遍历元素时,首先可以这样写:
list1 = ["这", "是", "一个", "测试"]
for i in range (len(list1)):
print i ,list1[i]- 1
- 2
- 3
- 上述方法有些累赘,利用enumerate()会更加直接和优美:
list1 = ["这", "是", "一个", "测试"]
for index, item in enumerate(list1):
print index, item
>>>
0 这
1 是
2 一个
3 测试- enumerate还可以接收第二个参数,用于指定索引起始值,如:
list1 = ["这", "是", "一个", "测试"]
for index, item in enumerate(list1, 1):
print index, item
>>>
1 这
2 是
3 一个
4 测试补充
如果要统计文件的行数,可以这样写:
count = len(open(filepath, 'r').readlines())- 1
这种方法简单,但是可能比较慢,当文件比较大时甚至不能工作。
可以利用enumerate():
count = 0
for index, line in enumerate(open(filepath,'r')):
count += 1