题目原文:
特殊的二进制序列是具有以下两个性质的二进制序列:
- 0 的数量与 1 的数量相等。
- 二进制序列的每一个前缀码中 1 的数量要大于等于 0 的数量。
给定一个特殊的二进制序列 S,以字符串形式表示。定义一个操作 为首先选择 S 的两个连续且非空的特殊的子串,然后将它们交换。(两个子串为连续的当且仅当第一个子串的最后一个字符恰好为第二个子串的第一个字符的前一个字符。)
在任意次数的操作之后,交换后的字符串按照字典序排列的最大的结果是什么?
示例 1:
输入: S = "11011000" 输出: "11100100" 解释: 将子串 "10" (在S[1]出现) 和 "1100" (在S[3]出现)进行交换。 这是在进行若干次操作后按字典序排列最大的结果。
说明:
S的长度不超过50。S保证为一个满足上述定义的特殊 的二进制序列。
尝试解答:
先上我自己的代码:
1 class Solution: 2 def segmentation(self,S): 3 list1 = list() 4 cnt = 0 5 start = 0 6 7 for i in range(len(S)): 8 if S[i] == "1": 9 cnt+=1 10 else: 11 cnt+=-1 12 if cnt==0: 13 list1.append(S[start:i+1]) 14 start = i+1 15 if start == len(S): 16 return list1 17 18 def makeLargestSpecial(self, S: str) -> str: 19 20 list2 = [] 21 if S == "": 22 return "" 23 else: 24 list1 = self.segmentation(S) 25 if len(list1)==1: 26 str2 = list1[0][1:-1] 27 return "1"+self.makeLargestSpecial(str2)+"0" 28 else: 29 #a = [] 30 #for i in range(len(list1)): 31 # a.append(int(list1[i])) 32 #a.sort(reverse=True) 33 #for i in range(len(list1)): 34 # list1[i]=str(a[i]) 35 #print(a) 36 37 38 for i in list1: 39 list2.append(self.makeLargestSpecial(i)) 40 list2.sort(reverse=True) 41 42 return "".join(list2) 43 44 45 if __name__ == "__main__": 46 solu = Solution() 47 print(solu.makeLargestSpecial("1101001110001101010110010010"))
思路是经典的递归,根据特殊字符串的数字特征,套用了类似压栈、弹栈的方法,但并不完全一样,像”110100“这种数据压栈弹栈就不太符合,但这个数据去掉外面的一层”1“跟”0“变成了”1010“就符合了,所以我先写了一个分割函数用来专门将父串分割为子串。
之后完整处理步骤如下图所示:

思路稍微动动脑筋是能想出来的,但是实现的过程有些曲折,调测试用例的时候遇到了几个问题看我调的过程就知道有多菜了(爆哭),看一下下面几张图:
错误一:

显然这次是只对第一次分割进行了排序,并没有对所有子串执行
错误二:
通过这两个测试用例可以看出来,虽然每个子串执行了排序,但好像sort()的排序结果没那么正确?其实并不是人家函数有问题,sort()对数字字符串排序效果如下图所示:

跟题目中的取最大值天然契合,但是愚钝的我当时没有想到这一层,觉得数位越长的字符串越应该排在前面,于是就出现了我代码中的一个可笑的操作:

未果之后我终于找到了问题所在,其实是因为开始的思路有问题,开始是先对父串进行排序又对子串进行了相应操作,应该改为先对子串进行排序后组合为父串再进行相应操作。
标准题解:
大佬们的思路其实相差不大,都是将问题类比到更直观的表现方式上,但问题本质没变,还是递归。
思路一:
类比到括号字符串问题
转换为括号字符串,就很容易了
解题思路
相信好多人看到题目中 “特殊的二进制序列” 的定义就懵逼了,这到底是什么鬼?
所以题目最难的地方就是 “不说人话”。其实只要想到这种定义就是 “有效的括号字符串” 就容易许多了,“1” 代表 “(”,“0” 代表 “)”。
- 0 和 1 的数量相等。 → “右括号” 数量和 “左括号” 相同。
- 二进制序列的每一个前缀码中 1 的数量要大于等于 0 的数量。→ “右括号” 必须能够找到一个 “左括号” 匹配。
再看题目中 “操作” 的定义:首先选择 S 的两个 连续 且非空的 特殊 的子串,然后将它们交换。
翻译过来就是:选择 S 中的两个 相邻 的 有效的括号字符串,然后交换即可。
现在再来解决问题。首先分析 “有效的括号字符串” 的性质。
- 一个有效的括号字符串一般能够被拆分为一段或几段,其中每一段都是 “不可拆分的有效的括号字符串”,比如,“()(())” 可以拆分为 “()” 和 “(())”。
- 另外,“有效的括号字符串” 中的每一 “段” 内部 (即去掉最外层括号的字串)都是另一个 “有效括号字符串”,比如 “(())” 里面是 “()”。
根据上面的规则,我们可以 递归地 将二进制序列对应的 “括号字符串” 分解。以序列 “110011100110110000” 为例: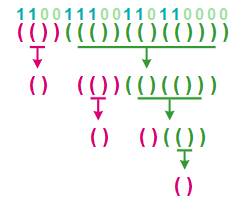
我们容易想到一种 递归地 解题思路。
- 第一步,将字符串拆分成一段或几段 “不可拆分的有效的括号字符串”。
- 第二步,将每一段 内部 的子串(也是 “有效的括号字符串”)分别重新排列成字典序最大的字符串(解决子问题)。
- 第三步,由于 每一对相邻的段都可以交换,因此无限次交换相当于我们可以把各个段以 任意顺序 排列。我们要找到字典序最大的排列。
这里有一个值得思考的地方:由于每一 “段” 必会以 “0” 结尾,因此只要将 “字典序最大” 的串放在第一位,“字典序次大” 的串放在第二位,...,就可以得到字典序最大的排列。(即将各个段按照字典序从大到小排序即可)。
1 class Solution { 2 public: 3 int *ne; 4 void arrange(string& s, int l, int r) { 5 if(l <= r) { 6 multiset<string> strs; // 注意,必须是 "multiset",以便保持重复的字符串 7 for(int i = l; i <= r;) { 8 arrange(s, i+1, ne[i]-1); 9 strs.insert(s.substr(i, ne[i] - i + 1)); 10 i = ne[i] + 1; 11 } 12 int p = l; 13 for(auto it = strs.rbegin(); it != strs.rend(); ++it) 14 for(char c : *it) 15 s[p++] = c; 16 } 17 } 18 string makeLargestSpecial(string s) { 19 ne = new int[s.size()]; 20 stack<int> st; 21 for(int i = 0; i < s.size(); ++i) { 22 if(s[i] == '1') { 23 st.push(i); 24 } else { 25 ne[st.top()] = i; 26 st.pop(); 27 } 28 } 29 arrange(s, 0, (int)s.size() - 1); 30 return s; 31 } 32 }; 33 34 //作者:newhar 35 //链接:https://leetcode-cn.com/problems/special-binary-string/solution/zhuan-huan-wei-gua-hao-zi-fu-chuan-jiu-hen-rong-yi/ 36 //来源:力扣(LeetCode) 37 //著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
再传一套相同思路的python代码,相当精炼:
1 class Solution: 2 def makeLargestSpecial(self, S: str) -> str: 3 return makeLargestSpecial(S) 4 # return ans 5 6 def makeLargestSpecial(S): 7 stkc, pos = 0, 0 8 new_subs = [] 9 for i in range(len(S)): 10 if S[i] == '0': 11 stkc -= 1 12 else: 13 stkc += 1 14 15 if stkc == 0: 16 new_subs.append('1' + makeLargestSpecial(S[pos+1:i]) + '0') 17 pos = i + 1 18 19 new_subs.sort(reverse=True) 20 return ''.join(new_subs) 21 22 if __name__=='__main__': 23 print(makeLargestSpecial("11001011101000101100")) 24 25 #作者:TheWizard 26 #链接:https://leetcode-cn.com/problems/special-binary-string/solution/can-kao-da-lao-jie-fa-by-cjliux/ 27 #来源:力扣(LeetCode) 28 #著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
思路二:
类比于找山谷问题
1 namespace impl { // 排序 2 // 元素类型为 pair<子串的左边界,子串的右边界> 3 // 第i个字符是1的在前,0的在中,短到没有第i个字符的放最后 4 template<typename RangeIter> inline pair<RangeIter, RangeIter> 5 three_way_partition(RangeIter rng_begin, RangeIter rng_end, size_t idx) { 6 auto i = rng_begin, j = rng_begin, k = rng_end - 1; 7 while(j <= k) { 8 if(j->second + idx >= j->first) { 9 iter_swap(j, k); 10 -- k; 11 } else if(j->first[idx] == '1') { 12 iter_swap(i, j); 13 ++ i; 14 ++ j; 15 } else { 16 ++ j; 17 } 18 } 19 return {i, j}; 20 } 21 22 // 元素类型为 pair<子串的左边界,子串的右边界> 23 template<typename RangeIter> 24 void sort_ranges_rec(RangeIter rng_begin, RangeIter rng_end, size_t i) { 25 while(rng_end - rng_begin > 1) {// 如果不做三路划分,那么遇到有两个相等子串时无法终止 26 auto part_point = three_way_partition(rng_begin, rng_end, i); 27 auto mid = part_point.first; 28 rng_end = part_point.second; 29 sort_ranges_rec(rng_begin, mid, ++i); 30 rng_begin = mid; 31 } 32 } 33 34 // 元素类型为 pair<子串的左边界,子串的右边界> 35 template<typename RangeIter, typename BufferIter> 36 inline void sort_ranges(RangeIter rng_begin, RangeIter rng_end, BufferIter buffer) { 37 auto ib = rng_begin->first; 38 auto i = buffer; 39 sort_ranges_rec(rng_begin, rng_end, 1); // 第0个字符必为'1',从1开始 40 // 把排序后子串重新拼到一起 41 for(auto j = rng_begin; j != rng_end; ++ j) { 42 // std::copy 复制一段区间 43 i = copy(j->first, j->second, i); 44 } 45 copy(buffer, i, ib); 46 } 47 48 // 构造、排序子串 49 template<typename Iter> 50 class RangeSorter { 51 vector<pair<Iter, Iter>> ranges; 52 vector<char> buffer; 53 public: 54 RangeSorter(size_t n) : buffer(n) {} 55 void new_range(Iter rng_begin, Iter rng_end) { 56 ranges.emplace_back(rng_begin, rng_end); 57 } 58 void next_range(Iter rng_end) { 59 ranges.emplace_back(ranges.back().second, rng_end); 60 } 61 void sort_and_consume(size_t n_valley) { 62 auto rngbegin = ranges.end() - (n_valley + 1), rngend = ranges.end(); 63 sort_ranges(rngbegin, rngend, buffer.begin()); 64 ranges.erase(rngbegin, rngend); 65 } 66 void sort_and_consume_all(Iter rng_end) { 67 if(!ranges.empty()) { 68 ranges.emplace_back(ranges.back().second, rng_end); 69 sort_ranges(ranges.begin(), ranges.end(), buffer.begin()); 70 } 71 } 72 }; 73 } 74 75 // 算法主要部分 76 class Solution { 77 template<typename T> using Stack = stack<T,vector<T>>; 78 using iter = string::iterator; 79 public: 80 string makeLargestSpecial(string S) { 81 auto Sbegin = S.begin(), Send = S.end(); 82 if(S.empty()) { return S; } 83 84 Stack<iter> stack_0; // 上一个1的位置 85 Stack<pair<iter,size_t>> stack_1; // pair<当前子串的左边界,等高山谷数> 86 impl::RangeSorter<iter> ranges(S.size()); 87 88 stack_0.emplace(Sbegin - 1); 89 stack_1.emplace(Sbegin - 1, 0); 90 91 for(auto i = Sbegin; i != Send; ++i) { 92 auto last1 = stack_0.top() + 1; 93 auto& t = stack_1.top(); 94 if(*i == '1') { 95 if(last1 != i) { 96 if(last1 == t.first) { // 和前面的山谷等高 97 t.second++; 98 ranges.next_range(i); 99 } else { // 比前面的山谷更高 100 stack_1.emplace(last1, 1); 101 ranges.new_range(last1, i); 102 } 103 } 104 stack_0.push(i); 105 } else { 106 if(last1 == t.first) { // 下坡到比栈顶山谷更低 107 // 构造最后一个子串 108 ranges.next_range(i); 109 ranges.sort_and_consume(t.second); 110 stack_1.pop(); 111 } 112 stack_0.pop(); 113 } 114 } 115 ranges.sort_and_consume_all(Send);// 如果 S 本身就是由多个连续特殊子串构成 116 return S; 117 } 118 }; 119 120 //作者:chronosphere 121 //链接:https://leetcode-cn.com/problems/special-binary-string/solution/c-0ms-63mb-fei-di-gui-lei-bi-yu-zhao-shan-gu-by-ch/ 122 //来源:力扣(LeetCode) 123 //著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
非递归,类比于找山谷 (C++, 0ms, 6.3MB)
解题思路
对于栈 stack_0,遍历输入 S,每遇到一个'1'就入栈当前位置,每遇到一个'0'就出栈。
初始状态栈为空,由于'1'和'0'数量相等,结束时栈也为空。那么整个遍历过程中栈高度的变化就像一片山脉。那么,连续特殊子串是什么呢?每一个山谷都对应了两个连续特殊子串的边界
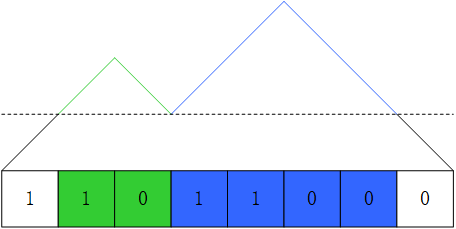
k个同样高度的山谷则对应了k+1个连续的子串
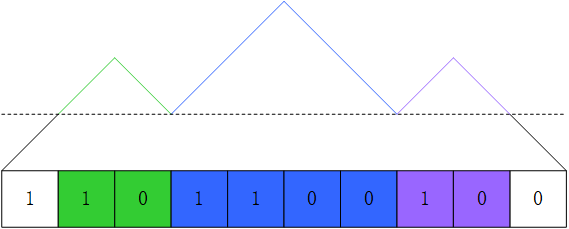
连续子串还可以套娃
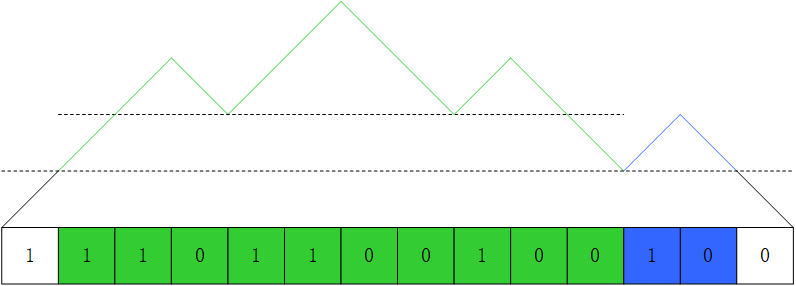
为了找到这些套娃的子串,用第二个栈 stack_1 来存储已找到的子串信息。与 stack_0 不同,不构成特殊子串的部分不会进入 stack_1。于是,每遇到一个山谷就在 stack_1 中记录下来:如果比前一个山谷高,则入栈一个新元素;如果和前一个山谷等高,则修改栈顶元素;而如果在下坡过程中发现比栈顶的山谷更低了,则说明找到了一系列连续特殊子串,可以进行排序了。
思路差距:
这道题的解答思路其实比较清晰简单,跟第一期黑盒反射复杂的映射关系不太一样,因此思路在读完题目的时候就已经构想的差不多了,力扣官方之所以判定这是一道困难题,可能是因为解答思路实现在代码上需要动不少脑子,python代码之所以很短不到50行是因为有现成的sort()函数对数字字符串进行排序(可能其他语言也有,但python牛逼!!!python天下第一!!【x】)
两位大佬的思路还是非常新颖的,有助于加深对题目的理解,这应该是积累的成果,还是应该接触更多的算法题目开阔眼界。
技术差距:
一、做完这道题还是感觉在复杂的递归问题上有些吃力,但好消息是我对递归的理解又加深了一点点(菜鸡本鸡是这样啦,宽容一些啦~),还是应该通过更多的题目加深理解,提高熟练度。
二、写代码过程中还是会犯一些小错误,好在第一期的错误没有再犯,大概这就是提高吧hhhhh,但是在S is None那里卡了我好久好久,总是有个“NoneType没有len()”方法的报错,我试了好多办法规避都没成功,最后发现问题出在这里,气得想砸电脑(爆哭),C++就不说了,跟大佬写的python相比也啰嗦不少。。。
三、思维导图对于编程相当重要啊,之前没有这个习惯张口就来,最近被高难度的题目毒打了,以后再也不敢不画思维导图了555。