最近准备重新研究一下推荐系统的东西,用到的数据集是Audioscrobbler音乐数据集。我用python处理数据集中artist_data.txt这个文件的时候,先读取每一行然后进行处理:
with open('artist_data.txt','r')as f:
for line in f:
process(line)#对每行进行的具体处理
但是我发现每次都处理一部分数据就停止了,也就是本来有一百多万行数据结果只处理了八千多行。我定位到了处理结束的那一行,发现数据有一个用 SUB 标记的乱码,如图所示:
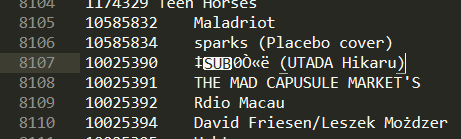
多次查找之后我发现这个文件中这样的符号还不止一个。
这个问题在网上很难找到相关的讨论,最后终于从一个论坛大家的回复中找到了答案。说,所有的Windows系统都会把SUB(ASCII 26)当做标准文本的末尾来处理,这样的存在主要是为了某种兼容性考虑。而Python中用‘r’模式读文件就是以标准文本进行处理,所以会遇到这个问题。如果用‘rb’的二进制读取方式就不会有问题了,也就是应该这样:
with open('artist_data.txt','rb')as f:顺便说一下,这样的问题在大多数支持POSIX标准的Linux中是不会出现的,因为Linux中把所有的文件都当做二进制文件处理的,r和rb两种读取模式没有本质上的区别。至此,这个问题得到了解决,虽然解决的方式很简单,但是知道为什么要这样解决可是费了好大的功夫,鉴于网上相关的讨论很少,自己记录下来。
感谢这个论坛中各位大神的积极讨论:https://www.v2ex.com/t/157187