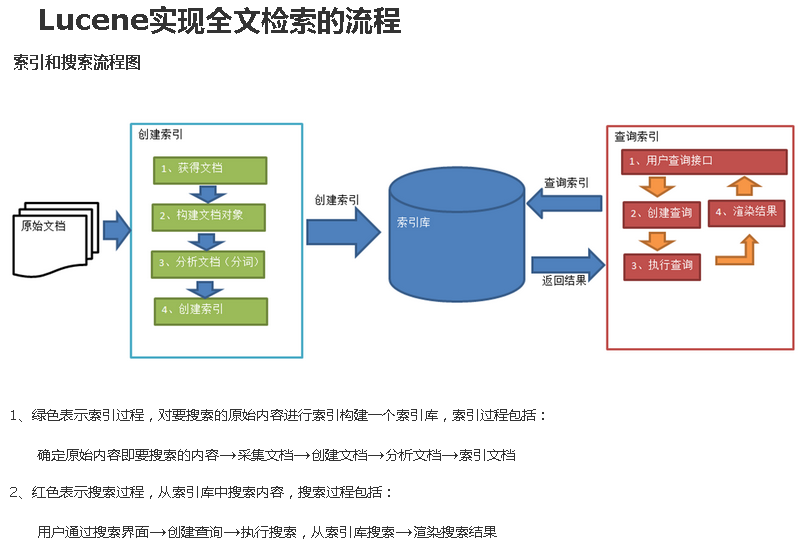
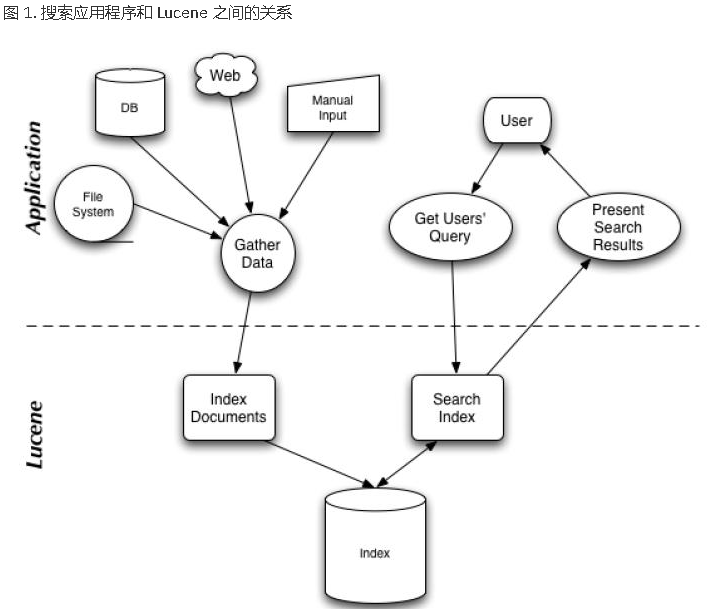
Lucene索引过程分为3个主要操作步骤:将原始文档转换成文本、分析文本、将分析好的文本保存至索引中
一、提取文本和创建文档
从 pdf、word等非纯文本格式文件中,提取文本格式信息。建立起对应的,包含各个域的文档后,就可以对这些文本信息进行分析。
使用 Tika框架实现
二、分析文档
调用 IndexWriter对象的 addDocument方法,将数据传递给Lucene进行索引操作。
分析文本,将文本数据分割成语汇单元串,执行一些可选操作。
一起构成分析器。
三、向索引添加文档
lucene索引包含一个或多个段
segments_N
Segments 0, Segments 1, Segments 2, Segments 3,……, Segments n
每个段都是一个独立的索引。每个段,都包含多个文件 _X.<ext>
如果使用混合文件格式,那么上述索引文件,会被压缩成一个单一的文件 _X.cfs
段文件:_<N>
索引时,需要进行的基本操作(添加、更新、删除)
Donate捐赠
如果我的文章帮助了你,可以赞赏我 6.66 元给我支持,让我继续写出更好的内容)


(微信) (支付宝)
微信/支付宝 扫一扫