一、模型可解释性
近年来,机器学习(深度学习)取得了一系列骄人战绩,但是其模型的深度和复杂度远远超出了人类理解的范畴,或者称之为黑盒(机器是否同样不能理解?),当一个机器学习模型泛化性能很好时,我们可以通过交叉验证验证其准确性,并将其应用在生产环境中,但是很难去解释这个模型为什么会做出此种预测,是基于什么样的考虑?作为机器学习从业者很容易想清楚为什么有些模型存在性别歧视、种族歧视和民族仇恨言论(训练样本的问题),但是很多场景下我们需要向模型使用方作出解释,让其清楚模型为什么要做出此种预测,如模型替代医生判断病情,给出病人合理的解释至关重要,在商业场景中,模型为公司做出决策,需要给出令管理层信服的解释。另外,给出解释也可以帮助我们进一步改善模型,优化特征,提高泛化性。
本文就LIME( Local Interpretable Model-Agnostic Explanations, LIME)方法如何解释黑盒模型作出简要的介绍和公式推导,介绍其优缺点,文末附上自己的一些简单思考
二、 LIME
LIME的主要思想是利用可解释性模型(如线性模型,决策树)局部近似目标黑盒模型的预测,此方法不深入模型内部,通过对输入进行轻微的扰动,探测黑盒模型的输出发生何种变化,根据这种变化在兴趣点(原始输入)训练一个可解释性模型。值得注意的是,可解释性模型是黑盒模型的局部近似,而不是全局近似,这也是其名字的由来。
LIME的数学表示如下:
对于实例(x)的解释模型(g),我们通过最小化损失函数来比较模型(g)和原模型(f)的近似性,其中,(Omega (g))代表了解释模型(g)的模型复杂度,(G)表示所有可能的解释模型(例如我们想用线性模型解释,则(G)表示所有的线性模型),(pi_{x}) 定义了(x)的邻域。我们通过最小化(L)使得模型(f)变得可解释。其中,模型(g),邻域范围大小,模型复杂度均需要定义。
下面对于结构化数据类型,简要说明LIME的工作流程。
对于结构化数据,首先确定可解释性模型,兴趣点x,邻域的范围。LIME首先在全局进行采样,然后对于所有采样点,选出兴趣点x的邻域,然后利用兴趣点的邻域范围拟合可解释性模型。如下图(^1)
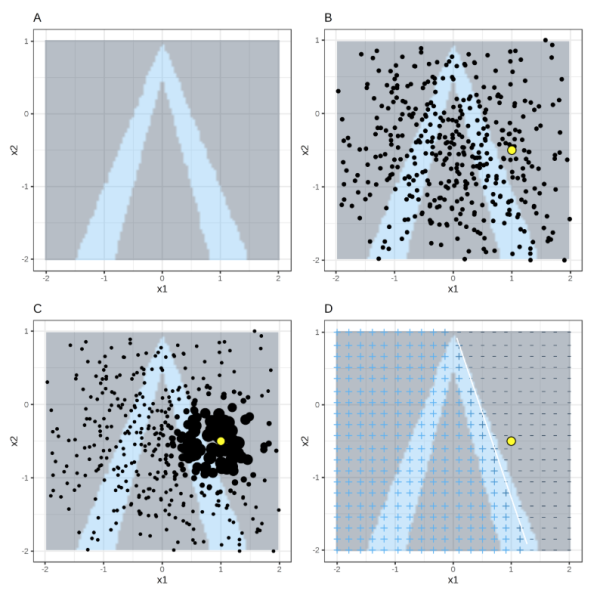
其中,背景灰色为负例,背景蓝色为正例,黄色为兴趣点,小粒度黑色点为采样点,大粒度黑点为邻域范围,右下图为LIME的结果。
LIME的优点我们很容易就可以看到,原理简单,适用范围广,可解释任何黑箱模型。但是在实际应用中,存在几个问题:
- 需要确定邻域范围;邻域范围不同,得到的局部可解释性模型可能会有很大的差别,如下图
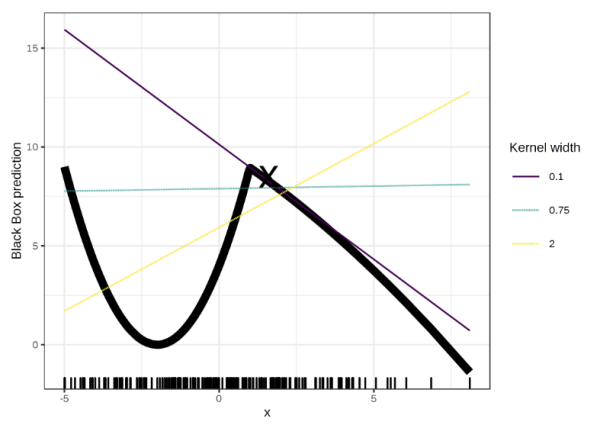
对于x=1.6,不同的邻域范围(0.1,0.75,2)对应的可解释性模型是完全不同的,甚至相悖。
-
采样是全样本集采样,采样是利用高斯分布进行采样,忽略了特征之间的关系,这可能导致一些不大可能出现的样本点来解释模型。
-
解释模型的复杂度需要提前定义。
-
解释的不稳定性。利用相同参数相同方法进行的重复解释,得到的结果可能完全不同.(^5)
三、总结
模型可解释性作为目前机器学习领域研究的热门,LIME的成果是很有启发性的,通过对黑盒模型某局部点的无限次探测,拟合出一个局部可解释性的简单模型。但是其缺点同样明显,这些缺点也导致了LIME方法难以大规模应用。
后续将介绍基于Shapley值的SHAP方法(现在在研读,就是有点看不懂。看懂了再写)
参考链接:
- https://christophm.github.io/interpretable-ml-book/lime.html
- https://blog.csdn.net/a358463121/article/details/52313585
- https://cloud.tencent.com/developer/article/1096716
- 论文地址:https://arxiv.org/pdf/1602.04938v1.pdf
- Alvarez-Melis, David, and Tommi S. Jaakkola. “On the robustness of interpretability methods.” arXiv preprint arXiv:1806.08049 (2018).)
本文由飞剑客原创,如需转载,请联系私信联系知乎:@AndyChanCD