小知识:
1、子类继承父类的三种方式
class Dog(Animal): #子类 派生类 def __init__(self,name,breed, life_value,aggr): # Animal.__init__(self,name,breed, life_value,aggr)#让子类执行父类的方法 就是父类名.方法名(参数),连self都得传 super().__init__(name,life_value,aggr) #super关键字 ,都不用传self了,在新式类里的 # super(Dog,self).__init__(name,life_value,aggr) #上面super是简写 self.breed = breed def bite(self,person): #狗的派生方法 person.life_value -= self.aggr def eat(self): #父类方法的重写 super().eat() print('dog is eating')
2、对象通过索引设置值的三种方式
方式一:重写__setitem__方法
class Foo(object): def __setitem__(self, key, value): print(key,value) obj = Foo() obj["xxx"] = 123 #给对象赋值就会去执行__setitem__方法
方式二:继承dict
class Foo(dict): pass obj = Foo() obj["xxx"] = 123 print(obj)
方式三:继承dict,重写__init__方法的时候,记得要继承父类的__init__方法
class Foo(dict): def __init__(self,val): # dict.__init__(self, val)#继承父类方式一 # super().__init__(val) #继承父类方式二 super(Foo,self).__init__(val)#继承父类方式三 obj = Foo({"xxx":123}) print(obj)
总结:如果遇到obj["xxx"] = xx ,
- 重写了__setitem__方法
- 继承dict
3、测试__name__方法
示例:
app1中: import app2 print('app1', __name__) app2中: print('app2', __name__)
现在app1是主程序,运行结果截图
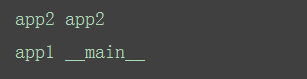
总结:如果是在自己的模块中运行,__name__就是__main__,如果是从别的文件中导入进来的,就不是__name__了
一、设置配置文件的几种方式
==========方式一:============ app.config['SESSION_COOKIE_NAME'] = 'session_lvning' #这种方式要把所有的配置都放在一个文件夹里面,看起来会比较乱,所以选择下面的方式 ==========方式二:============== app.config.from_pyfile('settings.py') #找到配置文件路径,创建一个模块,打开文件,并获取所有的内容,再将配置文件中的所有值,都封装到上一步创建的配置文件模板中
print(app.config.get("CCC"))
=========方式三:对象的方式============
import os
os.environ['FLAKS-SETTINGS'] = 'settings.py'
app.config.from_envvar('FLAKS-SETTINGS')
===============方式四(推荐):字符串的方式,方便操作,不用去改配置,直接改变字符串就行了 ==============
app.config.from_object('settings.DevConfig')
----------settings.DevConfig----------
from app import app
class BaseConfig(object):
NNN = 123 #注意是大写
SESSION_COOKIE_NAME = "session_sss"
class TestConfig(BaseConfig):
DB = "127.0.0.1"
class DevConfig(BaseConfig):
DB = "52.5.7.5"
class ProConfig(BaseConfig):
DB = "55.4.22.4"
要想在视图函数中获取配置文件的值,都是通过app.config来拿。但是如果视图函数和Flask创建的对象app不在一个模块。就得
导入来拿。可以不用导入,。直接导入一个current_app,这个就是当前的app对象,用current_app.config就能查看到了当前app的所有的配置文件
from flask import Flask,current_app
@app.route('/index',methods=["GET","POST"]) def index(): print(current_app.config) #当前的app的所有配置 session["xx"] = "fdvbn" return "index"
二、蓝图(flask中多py文件拆分都要用到蓝图)
如果代码非常多,要进行归类。不同的功能放在不同的文件,吧相关的视图函数也放进去。蓝图也就是对flask的目录结构进行分配(应用于小,中型的程序),
小中型:
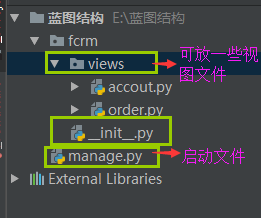
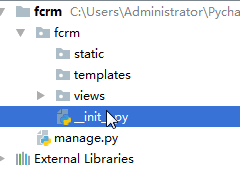
manage.py
import fcrm if __name__ == '__main__': fcrm.app.run()
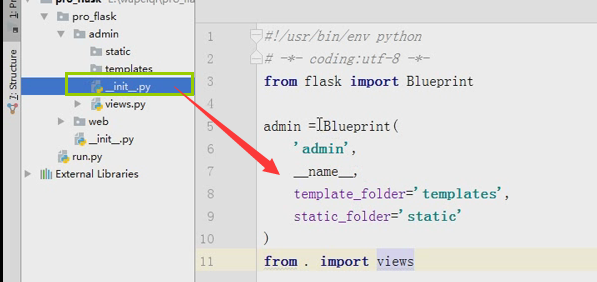
__init__.py(只要一导入fcrm就会执行__init__.py文件)
from flask import Flask #导入accout 和order from fcrm.views import accout from fcrm.views import order app = Flask(__name__) print(app.root_path) #根目录 app.register_blueprint(accout.accout) #吧蓝图注册到app里面,accout.accout是创建的蓝图对象 app.register_blueprint(order.order)
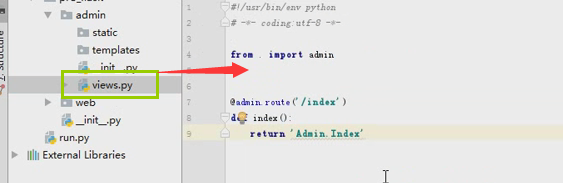
accout.py
from flask import Blueprint,render_template accout = Blueprint("accout",__name__) @accout.route('/accout') def xx(): return "accout" @accout.route("/login") def login(): return render_template("login.html")
order.py
from flask import Blueprint order = Blueprint("order",__name__) @order.route('/order') def register(): #注意视图函数的名字不能和蓝图对象的名字一样 return "order
使用蓝图时需要注意的

大型:
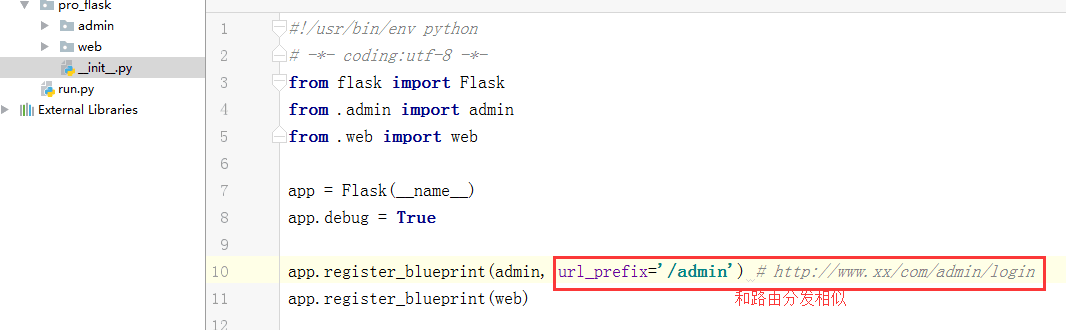
三、数据库连接池
flask中是没有ORM的,如果在flask里面连接数据库有两种方式
一:pymysql
二:SQLAlchemy
是python 操作数据库的一个库。能够进行 orm 映射官方文档 sqlchemy
SQLAlchemy“采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型”。SQLAlchemy的理念是,SQL数据库的量级和性能重要于对象集合;而对象集合的抽象又重要于表和行。
链接池原理
- BDUtils数据库链接池 - 模式一:基于threaing.local实现为每一个线程创建一个连接,关闭是 伪关闭,当前线程可以重复 - 模式二:连接池原理 - 可以设置连接池中最大连接数 9 - 默认启动时,连接池中创建连接 5 - 如果有三个线程来数据库中获取连接: - 如果三个同时来的,一人给一个链接 - 如果一个一个来,有时间间隔,用一个链接就可以为三个线程提供服务 - 说不准 有可能:1个链接就可以为三个线程提供服务 有可能:2个链接就可以为三个线程提供服务 有可能:3个链接就可以为三个线程提供服务 PS、:maxshared在使用pymysql中均无用。链接数据库的模块:只有threadsafety>1的时候才有用
那么我们用pymysql来做。
为什么要使用数据库连接池呢?不用连接池有什么不好的地方呢?
方式一、每次操作都要链接数据库,链接次数过多
#!usr/bin/env python # -*- coding:utf-8 -*- import pymysql from flask import Flask app = Flask(__name__) # 方式一:这种方式每次请求,反复创建数据库链接,多次链接数据库会非常耗时 # 解决办法:放在全局,单例模式 @app.route('/index') def index(): # 链接数据库 conn = pymysql.connect(host="127.0.0.1",port=3306,user='root',password='123', database='pooldb',charset='utf8') cursor = conn.cursor() cursor.execute("select * from td where id=%s", [5, ]) result = cursor.fetchall() # 获取数据 cursor.close() conn.close() # 关闭链接 print(result) return "执行成功" if __name__ == '__main__': app.run(debug=True)
方式二、不支持并发
#!usr/bin/env python # -*- coding:utf-8 -*- import pymysql from flask import Flask from threading import RLock app = Flask(__name__) CONN = pymysql.connect(host="127.0.0.1",port=3306,user='root',password='123', database='pooldb',charset='utf8') # 方式二:放在全局,如果是单线程,这样就可以,但是如果是多线程,就得加把锁。这样就成串行的了 # 不支持并发,也不好。所有我们选择用数据库连接池 @app.route('/index') def index(): with RLock: cursor = CONN.cursor() cursor.execute("select * from td where id=%s", [5, ]) result = cursor.fetchall() # 获取数据 cursor.close() print(result) return "执行成功" if __name__ == '__main__': app.run(debug=True)
方式三:由于上面两种方案都不完美,所以得把方式一和方式二联合一下(既让减少链接次数,也能支持并发)所有了方式三,需要
导入一个DButils模块
基于DButils实现的数据库连接池有两种模式:
模式一:为每一个线程创建一个链接(是基于本地线程来实现的。thread.local),每个线程独立使用自己的数据库链接,该线程关闭不是真正的关闭,本线程再次调用时,还是使用的最开始创建的链接,直到线程终止,数据库链接才关闭
注: 模式一:如果线程比较多还是会创建很多连接,模式二更常用
#!usr/bin/env python # -*- coding:utf-8 -*- from flask import Flask app = Flask(__name__) from DBUtils.PersistentDB import PersistentDB import pymysql POOL = PersistentDB( creator=pymysql, # 使用链接数据库的模块 maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制 setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."] ping=0, # ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always closeable=False, # 如果为False时, conn.close() 实际上被忽略,供下次使用,再线程关闭时,才会自动关闭链接。如果为True时, conn.close()则关闭链接,那么再次调用pool.connection时就会报错,因为已经真的关闭了连接(pool.steady_connection()可以获取一个新的链接) threadlocal=None, # 本线程独享值得对象,用于保存链接对象,如果链接对象被重置 host='127.0.0.1', port=3306, user='root', password='123', database='pooldb', charset='utf8' ) @app.route('/func') def func():
conn = POOL.connection()
cursor = conn.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
cursor.close()
conn.close() # 不是真的关闭,而是假的关闭。 conn = pymysql.connect() conn.close()
conn = POOL.connection()
cursor = conn.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
cursor.close()
conn.close()
if __name__ == '__main__': app.run(debug=True)
模式二:创建一个链接池,为所有线程提供连接,使用时来进行获取,使用完毕后在放回到连接池。
PS:假设最大链接数有10个,其实也就是一个列表,当你pop一个,人家会在append一个,链接池的所有的链接都是按照排队的这样的方式来链接的。
链接池里所有的链接都能重复使用,共享的, 即实现了并发,又防止了链接次数太多
import time import pymysql import threading from DBUtils.PooledDB import PooledDB, SharedDBConnection POOL = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建 maxcached=5, # 链接池中最多闲置的链接,0和None不限制 maxshared=3, # 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制 setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."] ping=0, # ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always host='127.0.0.1', port=3306, user='root', password='123', database='pooldb', charset='utf8' ) def func(): # 检测当前正在运行连接数的是否小于最大链接数,如果不小于则:等待或报raise TooManyConnections异常 # 否则 # 则优先去初始化时创建的链接中获取链接 SteadyDBConnection。 # 然后将SteadyDBConnection对象封装到PooledDedicatedDBConnection中并返回。 # 如果最开始创建的链接没有链接,则去创建一个SteadyDBConnection对象,再封装到PooledDedicatedDBConnection中并返回。 # 一旦关闭链接后,连接就返回到连接池让后续线程继续使用。 # PooledDedicatedDBConnection conn = POOL.connection() # print(th, '链接被拿走了', conn1._con) # print(th, '池子里目前有', pool._idle_cache, ' ') cursor = conn.cursor() cursor.execute('select * from tb1') result = cursor.fetchall() conn.close() conn = POOL.connection() # print(th, '链接被拿走了', conn1._con) # print(th, '池子里目前有', pool._idle_cache, ' ') cursor = conn.cursor() cursor.execute('select * from tb1') result = cursor.fetchall() conn.close() func()
五、本地线程:保证每个线程都只有自己的一份数据,在操作时不会影响别人的,即使是多线程,自己的值也是互相隔离的
没用线程之前
import threading
import time
class Foo(object): def __init__(self): self.name = None local_values = Foo() def func(num): time.sleep(2) local_values.name = num print(local_values.name,threading.current_thread().name) for i in range(5): th = threading.Thread(target=func, args=(i,), name='线程%s' % i) th.start()
打印结果:
1 线程1 0 线程0 2 线程2 3 线程3 4 线程4
用了本地线程之后
import threading import time # 本地线程对象 local_values = threading.local() def func(num): """ # 第一个线程进来,本地线程对象会为他创建一个 # 第二个线程进来,本地线程对象会为他创建一个 { 线程1的唯一标识:{name:1}, 线程2的唯一标识:{name:2}, } :param num: :return: """ local_values.name = num # 4 # 线程停下来了 time.sleep(2) # 第二个线程: local_values.name,去local_values中根据自己的唯一标识作为key,获取value中name对应的值 print(local_values.name, threading.current_thread().name) for i in range(5): th = threading.Thread(target=func, args=(i,), name='线程%s' % i) th.start()
打印结果:
1 线程1 2 线程2 0 线程0 4 线程4 3 线程3
六、上下文管理
a、类似于本地线程 创建Local类: { 线程或协程唯一标识: { 'stack':[request],'xxx':[session,] }, 线程或协程唯一标识: { 'stack':[] }, 线程或协程唯一标识: { 'stack':[] }, 线程或协程唯一标识: { 'stack':[] }, } b、上下文管理的本质 每一个线程都会创建一个上面那样的结构, 当请求进来之后,将请求相关数据添加到列表里面[request,],以后如果使用时,就去读取 列表中的数据,请求完成之后,将request从列表中移除 c、关系 local = 小华={ 线程或协程唯一标识: { 'stack':[] }, 线程或协程唯一标识: { 'stack':[] }, 线程或协程唯一标识: { 'stack':[] }, 线程或协程唯一标识: { 'stack':[] }, } stack = 强哥 = { push pop top } 存取东西时都要基于强哥来做 d、最近看过一些flask源码,flask还是django有些区别 - Flask和Django区别? - 请求相关数据传递的方式 - django:是通过传request参数实现的 - Flask:基于local对象和,localstark对象来完成的 当请求刚进来的时候就给放进来了,完了top取值就行了,取完之后pop走就行了 问题:多个请求过来会不会混淆 -答: 不会,因为,不仅是线程的,还是协程,每一个协程都是有唯一标识的: from greenlent import getcurrentt as get_ident #这个就是来获取唯一标识的
flask的request和session设置方式比较新颖,如果没有这种方式,那么就只能通过参数的传递。
flask是如何做的呢?
- 本地线程:是Flask自己创建的一个线程(猜想:内部是不是基于本地线程做的?) vals = threading.local() def task(arg): vals.name = num - 每个线程进来都是打印的自己的,只有自己的才能修改, - 通过他就能保证每一个线程里面有一个数据库链接,通过他就能创建出数据库链接池的第一种模式 - 上下文原理 - 类似于本地线程 - 猜想:内部是不是基于本地线程做的?不是,是一个特殊的字典
#!/usr/bin/env python # -*- coding:utf-8 -*- from functools import partial from flask.globals import LocalStack, LocalProxy ls = LocalStack() class RequestContext(object): def __init__(self, environ): self.request = environ def _lookup_req_object(name): top = ls.top if top is None: raise RuntimeError(ls) return getattr(top, name) session = LocalProxy(partial(_lookup_req_object, 'request')) ls.push(RequestContext('c1')) # 当请求进来时,放入 print(session) # 视图函数使用 print(session) # 视图函数使用 ls.pop() # 请求结束pop ls.push(RequestContext('c2')) print(session) ls.push(RequestContext('c3')) print(session)
3. Flask内部实现
#!/usr/bin/env python # -*- coding:utf-8 -*- from greenlet import getcurrent as get_ident def release_local(local): local.__release_local__() class Local(object): __slots__ = ('__storage__', '__ident_func__') def __init__(self): # self.__storage__ = {} # self.__ident_func__ = get_ident object.__setattr__(self, '__storage__', {}) object.__setattr__(self, '__ident_func__', get_ident) def __release_local__(self): self.__storage__.pop(self.__ident_func__(), None) def __getattr__(self, name): try: return self.__storage__[self.__ident_func__()][name] except KeyError: raise AttributeError(name) def __setattr__(self, name, value): ident = self.__ident_func__() storage = self.__storage__ try: storage[ident][name] = value except KeyError: storage[ident] = {name: value} def __delattr__(self, name): try: del self.__storage__[self.__ident_func__()][name] except KeyError: raise AttributeError(name) class LocalStack(object): def __init__(self): self._local = Local() def __release_local__(self): self._local.__release_local__() def push(self, obj): """Pushes a new item to the stack""" rv = getattr(self._local, 'stack', None) if rv is None: self._local.stack = rv = [] rv.append(obj) return rv def pop(self): """Removes the topmost item from the stack, will return the old value or `None` if the stack was already empty. """ stack = getattr(self._local, 'stack', None) if stack is None: return None elif len(stack) == 1: release_local(self._local) return stack[-1] else: return stack.pop() @property def top(self): """The topmost item on the stack. If the stack is empty, `None` is returned. """ try: return self._local.stack[-1] except (AttributeError, IndexError): return None stc = LocalStack() stc.push(123) v = stc.pop() print(v)