AlexNet
相关文献:
ImageNet Classification with Deep Convolutional Neural Networks
Alex Krizhevsky Ilya Sutskever Geoffrey E. Hinton
2012 NIPS
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
AlexNet的特点;
- 用relu代替sigmoid
- local response normalization,提高泛化能力
- 分到多个GPU训练,提高训练效率
- 用数据增强和dropout避免过拟合
网络结构
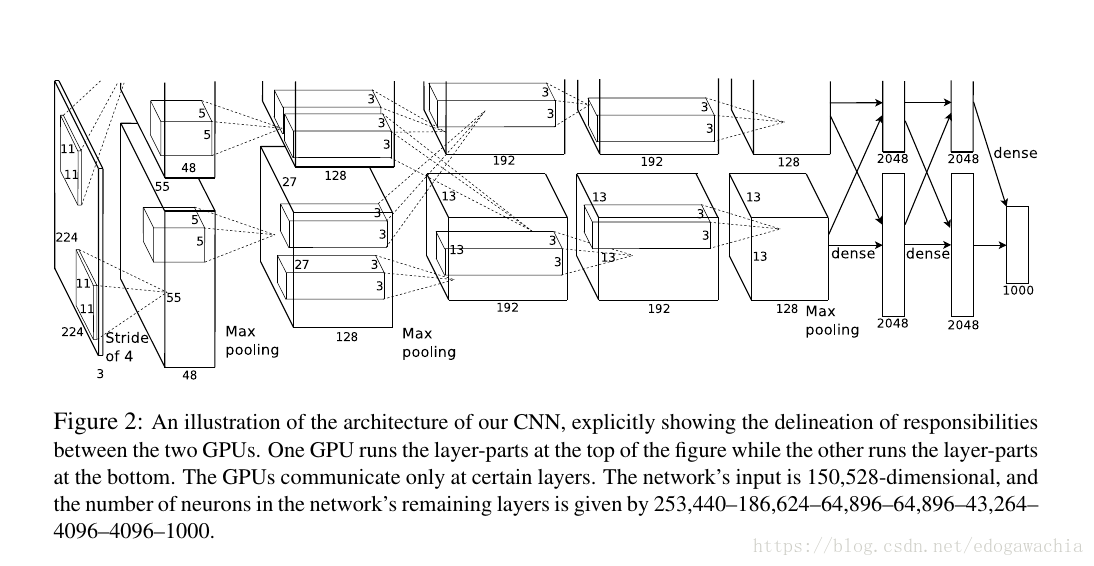
上面是论文中的图,示意GPU并行操作的连接和分离。不过没有画出没一层的内部结构,所以参照下图进行说明:

总体结构:5层卷积,3层全连接。
注意到,这里的激活函数已经不是lenet用的sigmoid形式的tanh函数,而是用了ReLU函数,可以避免sigmoid的饱和区域难以下降的困难。
前面的两层卷积后面跟了一个local contrast norm,局部对比度归一化处理。在第一个convolution,第二个convolution,以及最后一个convolution后跟了一个max pooling,这里的max pooling 池化方法也是第一次应用于CNN分类。对比之前的lenet用的是降采样(局部2×2区域求和乘以系数加bias)。并且,这里的pooling是overlap的,有重叠的池化。在这个model的设计中,作者在实验中观察到,stride=2,kernel=3的时候比起stride和kernel相等的不重叠的pooling可以降低top-1和top-5的error,所以用了重叠的pooling。后面用了两层带relu的全连接,各4096。最后一层是全连接1000,对应于1000个分类。
参照论文中的图,最开始输入的是224×224×3的图像,然后用11×11的大kernel卷积一遍,卷积的stride=4,取4是因为这是相邻的两个感知域的中心点的距离(kernel是11,如果要想该kernel相邻的包含它的中心的话,最多移动4个长度)。注意,到了第二层开始,网络就被分到两个GPU去了。而且在第2,4,5层的时候只在本GPU上运算,而在第3层的时候进行一次GPU的通信,也就是将两个GPU上的feature map都连接到后一层。在最后的dense层的时候在进行综合,从而使得网络的训练可以在多个GPU上进行,提高了效率。
下面介绍AlexNet里的一些技术创新。
ReLU 非线性激活函数
Deep convolutional neural networks with ReLUs train several times faster than their equivalents with tanh units.
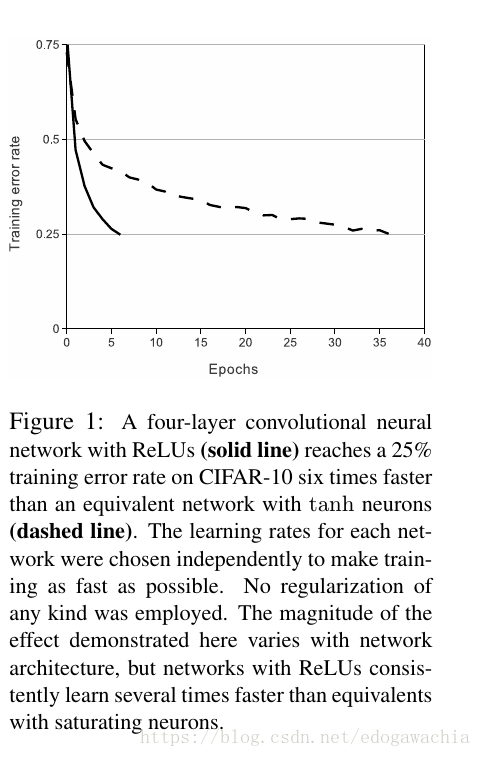
ReLU是Hinton提出来用在RBM中的,V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proc. 27th International Conference on Machine Learning, 2010,在此处被应用在模型里来加快训练速度。由于ReLU没有饱和区域,所以可以得到很好的训练效果。
Local Response Normalization(局部响应归一化)
首先要说的是,由于采用了relu替代了sigmoid,所以其实不必对激活函数的输入有规范化的要求。sigmoid之所以要求规范化是希望输入能落在线性区域而不是饱和区域。但是对于relu来说只要有大于零的训练样本,神经元就可以持续学习。但是在实验中,作者发现,进行local normalization可以提高泛化性能。所以做了一个LRN,局部归一化的操作。如图:
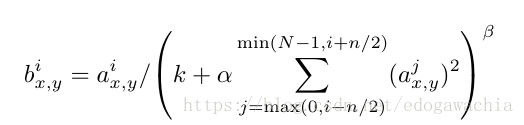
This sort of response normalization implements a form of lateral inhibition inspired by the type found in real neurons, creating competition for big activities amongst neuron outputs computed using different kernels. 也就是说,这种归一化模拟了实际神经元的侧抑制功能,提高了模型的performance。
注意这里的 i 和 j 是 第 i 和 j 个 kernel,xy是位置。其他的都是超参数。
防止过拟合的策略
由于这个网络结构的参数体量较大,所以很容易过拟合。alexnet有两种方式在避免过拟合:data augmentation和dropout
数据增强(data augmentation)
首先是translation和horizontal reflection,然后从256×256的里面分割成224×224的patch,这样数据就大了很多,但是高度inter-dependent。在测试的时候,也切出5个224的patch,然后预测求平均。
除了平移翻转之外,还用了RGB通道扰动的方法:首先对RGB像素值做一个PCA,然后找到主成分。在原来的基础上加上下面的值:
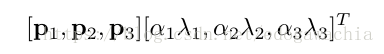
其中p是特征向量,lambda是特征值,而alpha是N(0,0.1)的随机扰动。
This scheme approximately captures an important property of natural images, namely, that object identity is invariant to changes in the intensity and color of the illumination. 物体对于不同的光照的颜色和强度应该表现出同一性(identity)
引入Dropout
G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R.R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
上面是dropout的来源,也是Hinton他们做的…..
通过dropout可以不用做多组模型用来降低test error。实际上dropout本身就有多个模型融合的意味,每个模型就是dropout掉一部分连接后剩余的trainable的网络,然后最后利用概率进行融合。这里用的是Dropout(0.5)。避免了overfitting,也使得收敛慢了一倍。
下降方法
动量为0.9,weight decay 0.0005, 梯度epsilon,batch size 128 。如下图:

2018年04月16日18:47:49