实时数据分页去重问题

 3209
3209  收藏
收藏1. 问题描述
将分页、降序数据用瀑布流展示的时候,因为数据总量是不断变化的,导致之前第一页的数据可能变成第二页,第三页,这样客户查看的时候可能出现重复数据展示。(最新的数据会插到列表的最前端)。 典型的是活动参与人列表页,因为这部分数据对于业务方来说可能非常重要,不能出现任何的重复或者顺序显示的不对。
2. 实际场景
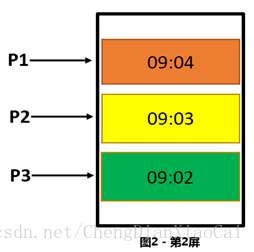
用户按照分页降序请求瀑布流数据的时候,请求完第一页,在该页停留了 5 分钟,这段时间内数据库中可能已经插入了多条新数据,再次请求第二页的时候就有可能出现一些重复数据,对于客户体验很不好,而且很可能引发客户的投诉。
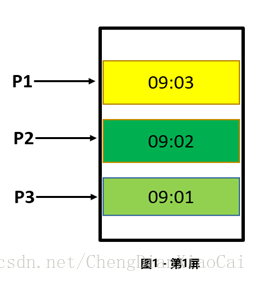
效果图:
P1 在第一屏的时候在第一页,如果客户在一分钟内没有做任何操作,下一分钟下滑页面的时候去DB中获取第二页的时候会拿到重复的数据。
3. 解决方案
(1)添加缓存
让动态数据变成静态数据,但不能从根本上解决数据重复问题,只能在一个时间段内保证不出现重复数据,缓存失效后仍然可能出现重复数据。
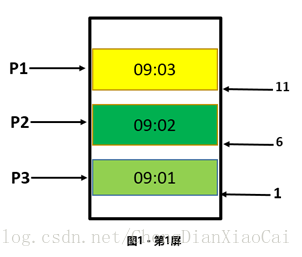
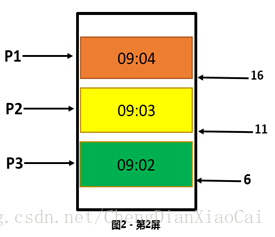
(2)增加序列号(唯一有序),
记录上一页请求结果的最后一条记录,请求下一页的时候加上这条记录用于后端判断,后端只取该记录之后的数据,强行将动态数看做静态数据处理。
-
/**
-
* P1 的最后一条记录序列号是 11, 查询第二页的时候加上这个条件,只取 id 小于 11 的数据,可* 以取到正确数据
-
*/
-
List<User> getUsers(size, serialNo){
-
List<User> users = selectFromESOrDBWhereIdIsLower(size, serialNo);
-
return users
-
}
这种方案的关键在于一个唯一且有序的序列号,根据这个序列号可以进行条件查询,可以锁定一个固定的范围。
目前这种方案也是今日头条采用的方案:
简化版头条分页数据出参 JSON:

-
{
-
"return_count":15,
-
"data":[
-
{
-
"behot_time":1494381138
-
},
-
{
-
"behot_time":1494380958
-
},
-
{
-
"behot_time":1494380778
-
},
-
{
-
"behot_time":1494380598
-
},
-
{
-
"behot_time":1494380238
-
},
-
{
-
"behot_time":1494380058
-
},
-
{
-
"behot_time":1494379878
-
},
-
{
-
"behot_time":1494379698
-
},
-
{
-
"behot_time":1494379518
-
},
-
{
-
"behot_time":1494379338
-
},
-
{
-
"behot_time":1494378978
-
},
-
{
-
"behot_time":1494378798
-
},
-
{
-
"behot_time":1494378798
-
}
-
]
-
}
从这个出参 JSON 我们可以看到每条记录都有一个唯一有序的序列号。
方案实践:
参与人列表显示的是当前期的所有参与人订单记录(按支付时间降序显示),思考过程中我们想过使用 payTime、orderId 作为序列号,但是最后方案都行不通,原因如下:
orderId: 订单编号:订单编号对于数据库来说一定是唯一的,用它可以唯一的定位一条记录,但是因为 orderId 的生成(下单)与用户支付之间有一个时差,导致 orderid 小的订单可能支付时间很晚,也就是 orderId 唯一但是没有顺序。
通过以上的分析:payTime 因为不符合唯一性不能作为序列号,orderId 因为不符合有序性也不能作为序列号。所以第二种方案对于我们的项目来说也不适用,没有办法保证数据不重复显示。
(3)前端维护数据池
如果数据的相对顺序不发生变化的话,比如参与人列表数据,按照参与时间降序排列,这种情况可以用增加唯一标识的方式解决,因为数据的相对顺序没有变化,所以之后请求到的数据都是之前没有请求过的,所以可以很好的保证数据不重复,但是无法保证数据的即时性。
如果数据的相对顺序不断变化,并且这样的数据还要求绝对不重复的话,比如按销售进度排序首页商品信息,可能一次大的营销活动会导致之前销量不高的数据排序迅速蹿高,进度快速提升,导致排序发生改变,那么增加记录唯一标识的方法也不能保证数据的不重复性,这个时候只能通过前端维护一个数据池,将之前已经请求到的数据存放进去,从后台请求到新的数据后查看数据池中是否已经存在,只显示不存在的部分,新请求到的数据也都不断的维护到数据池中。
(4)顺序分页,逆序显示
前端维护数据池的方式虽然可以保证不出现重复数据,但是如果数据量很大的时候可能会导致数据池很大,而且前端做去重操作可能会导致数据量少于请求数量,而且顺序无法保证,影响客户体验,这样我们就必须思考新的方案,最后的方案是之前方案的一个逆向思维,不再做逆序分页,因为逆序分页总有最新的数据加进来影响数据总量和分页的页数,如果转换思维做顺序分页,那么可以保证之前的页数不会变,只需要记录第一次请求的时候数据库数据总量,从而可以算出逆序分页的页数,然后去 ES 或者 DB 中取出数据,使用程序给数据做逆序显示,从而可以保证数据的绝对不重复,并且数据的顺序不会发生变化,而且每页请求到的数据量与请求数据量一致(最后一页可能会少一些)。
-
/*
-
* 伪代码
-
*/
-
getUsers(page, size, count){
-
//获取第一次请求数据总量:动态数据 ==> 静态数据
-
if(count == 0)
-
count = getCountFromDB()
-
-
//分页入参重新计算,ES,DB 都变成顺序查询:降序页数转换成正向页数
-
endIndex = count – (page - 1) * size;
-
startIndex = endIndex – size;
-
if(startIndex < 0)
-
startIndex = 0;
-
realSize = endIndex – startIndex;
-
-
//获取顺序分页数据
-
pageList = getPageListFromESOrDB(startIndex, realSize);
-
-
//获取反转显示数据
-
Collections.reverse(pageList);
-
-
//封装出参:带上 count
-
return (isLastPage, count, pageList)
-
}
最终上述代码成为我们最终的方案,并且在实践中取得不错的效果,保证了数据的绝对不重复,避免了因为数据重复或者顺序不对引来的客户投诉。
4. 总结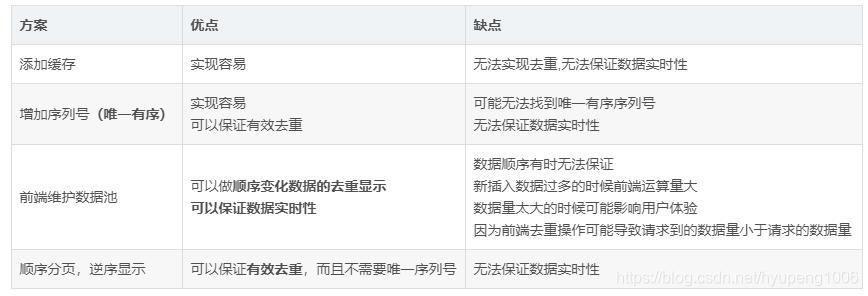
5. 思考
数据的实时性和重复性平衡点:
对于瀑布流分页数据降序显示问题,通过思考实践我们总结出了上述四种方案,加缓存、加序列号、顺序分页,逆序显示方案的目的都是为了将动态数据转换成静态数据,保证了数据的不重复性,但是不能保证数据的实时性,最新的数据可能没有办法立即显示出来,客户端去重方案可以保证数据的实时性,但是却不能绝对的保证数据的顺序和不重复性,而且大量的去重运算放到前端也不是我们所推崇的。
所以无论是选择哪种方案目前来看都没有办法同时保证数据的实时性和不重复性,那么在方案的选择时我们可以选择多种方案的一个组合、或者通过增加新的功能。
比如今日头条新闻客户端,新闻数据量很大,需要分页展示,但是新闻的数据跟作者名气、点击人数等一系列参数有关,顺序根本无法判断,而且新闻还绝对不能重复显示,那这种情况下需要将上述几种方法进行一个结合。
我们可以使用顺序分页查询、逆序显示的方式处理瀑布流分页,并且增加顶端下拉刷新功能、或者客户端去重功能,这样可以保证下拉的过程中不会出现重复数据,顶端上拉刷新可以显示最新的数据,从而在数据的实时性和重复性之间找到一个平衡。