词法分析程序(Lexical Analyzer)要求:
- 从左至右扫描构成源程序的字符流
- 识别出有词法意义的单词(Lexemes)
- 返回单词记录(单词类别,单词本身)
- 滤掉空格
- 跳过注释
- 发现词法错误
程序结构:
输入:字符流(什么输入方式,什么数据结构保存)
处理:
–遍历(什么遍历方式)
–词法规则
输出:单词流(什么输出形式)
–二元组
单词类别:
1.标识符(10)
2.无符号数(11)
3.保留字(一词一码)
4.运算符(一词一码)
5.界符(一词一码)
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
: |
17 |
|
if |
2 |
:= |
18 |
|
then |
3 |
< |
20 |
|
while |
4 |
<= |
21 |
|
do |
5 |
<> |
22 |
|
end |
6 |
> |
23 |
|
l(l|d)* |
10 |
>= |
24 |
|
dd* |
11 |
= |
25 |
|
+ |
13 |
; |
26 |
|
- |
14 |
( |
27 |
|
* |
15 |
) |
28 |
|
/ |
16 |
# |
0 |
#include <stdio.h>
#include <string.h>
char prog[80],token[8],ch;
int p,syn,m,n,sum;
char *rwtab[6]={"begin","if","then","while","do","end"};
void scaner(void);
main()
{
p=0;
printf("
输入一串字符(按#号键结束):
");
do{
scanf("%c",&ch);
prog[p++]=ch;
}while(ch!='#');
p=0;
do{
scaner();
switch(syn)
{
case 11:
printf("(%-10d%5d)
",sum,syn);
break;
case -1:
printf("你输入的字符串有误
");
return 0;
break;
default:
printf("(%-10s%5d)
",token,syn);
break;
}
}while(syn!=0);
}
void scaner(void)
{
sum=0;
for(m=0;m<8;m++)
token[m++]=NULL;
ch=prog[p++];
m=0;
while((ch==' ')||(ch=='
'))
ch=prog[p++];
if(((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z')))
{
while(((ch>='a')&&(ch<='z'))||((ch>='A')&&(ch<='Z'))||((ch>='0')&&(ch<='9')))
{
token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{
syn=n+1;
break;
}
}
else if((ch>='0')&&(ch<='9'))
{
while((ch>='0')&&(ch<='9'))
{
sum=sum*10+ch-'0';
ch=prog[p++];
}
p--;
syn=11;
}
else
{
switch(ch)
{
case '<':
token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=21;
token[m++]=ch;
}
else
{
syn=20;
p--;
}
break;
case '>':
token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=24;
token[m++]=ch;
}
else
{
syn=23;
p--;
}
break;
case '+':
token[m++]=ch;
ch=prog[p++];
if(ch=='+')
{
syn=17;
token[m++]=ch;
}
else
{
syn=13;
p--;
}
break;
case '-':
token[m++]=ch;
ch=prog[p++];
if(ch=='-')
{
syn=29;
token[m++]=ch;
}
else
{
syn=14;
p--;
}
break;
case '!':
token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=22;
token[m++];
}
else
{
syn=31;
p--;
}
break;
case '=':
token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=25;
token[m++]=ch;
}
else
{
syn=18;
p--;
}
break;
case '/':
syn=16;
token[m++]=ch;
break;
case '*':
syn=15;
token[m++]=ch;
break;
case '(':
syn=27;
token[m++]=ch;
break;
case ')':
syn=28;
token[m++]=ch;
break;
case '{':
syn=5;
token[m++]=ch;
break;
case '}':
syn=6;
token[m++]=ch;
break;
case ';':
syn=26;
token[m++]=ch;
break;
case '"':
syn=30;
token[m++]=ch;
break;
case '#':
syn=0;
token[m++]=ch;
break;
case ':':
syn=17;
token[m++]=ch;
break;
default:
syn=-1;
break;
}
}
token[m++]='�';
}
实验截图:
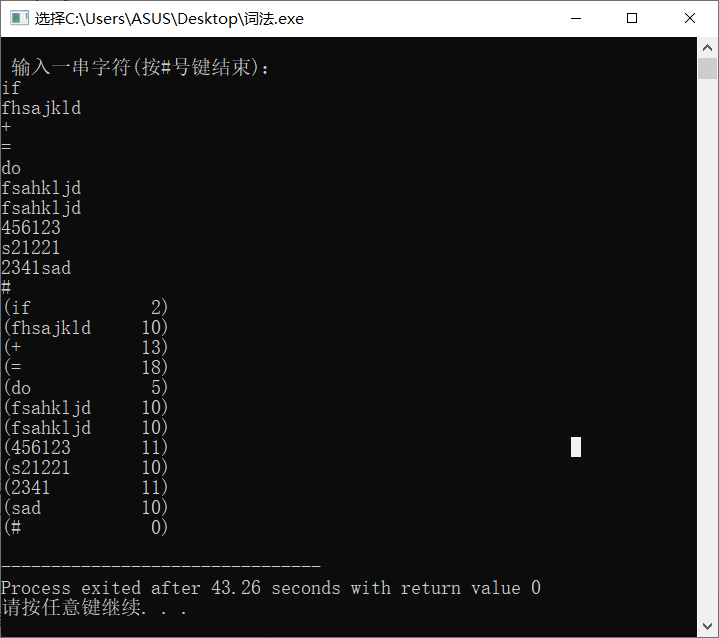
这次的代码从网上摘抄下来,自个没写出来。
原文链接:https://blog.csdn.net/rill_zhen/article/details/7722882