简介
用一个可伸缩的窗口遍历字符串,时间复杂度大致为O(n)。适用于“寻找符合某条件的最小子字符串”题型。
题目
求某字符串T中含有某字符串S的所有字符的最小子字符串。如果不存在则返回"".
算法
用左右两个指针维护一个窗口。
- 将右指针右移,直至窗口满足条件,包含S中所有字符。
- 将左指针左移,直至窗口不再满足条件。此过程中每移动一次,都更新最小子字符串。
- 重复1、2两步。
WHY IT WORKS
设想一个最naive的算法如何遍历T中的所有子字符串。以T中的每一个字符为子字符串的起始字符,从1开始,增加子字符串的长度直至触及T的尾字符,这样就是遍历了T中的所有子字符串。
比如字符串“ABCD”,以'A'开头的子字符串有"A", "AB", "ABC", "ABCD";以'B'开头的有"B", "BC", "BCD";以'C'开头的有"C", "CD";以"D"开头的有"D"。这样遍历的时间复杂度是O(n^2)。
我们把目光集中于起始字符,看看滑动窗口的效用。

滑动窗口算法中的第一步立足于某字符x,相当于以x为起始字符,寻找满足条件的子字符串。由于题中要求最短的子字符串,所以一旦满足条件就可停下,不必再往下寻找,相当于节省了一部分算力。

假设第一步中找到的子字符串以某字符y结束,且x至y这个子字符串的长度为m。则遍历到现在为止,找到的子字符串答案的长度<=m。(假设x之前还有其他元素,则1、2步已重复过数轮)

在第二步中,通过移动左指针对窗口进行收缩。假设左指针到达元素z时,窗口不再满足条件。则在左指针移动的过程中,以(x,z)开区间内的元素作为起始字符,y为结束字符进行了遍历。
将结束字符固定在y处是对naive解法的重要优化,蕴含了滑动窗口算法可以正确找出答案的主要数学原理:
对x、z之间的某一元素t,以t为起始字符且满足条件的最小子字符串必在y处结束。
证明:窗口收缩在z左侧,保证了t至y的字符串满足条件;设t至y不是最小的子字符串,则存在由t开始至字符r的的字符串满足条件,且r在y左侧,那么x至r的字符串也必满足条件,与第一步中得到的结论矛盾,故得证。
因为这个原理,x和z之间的元素只靠窗口左边界收缩就得到了遍历。时间复杂度由平方变成了线性。
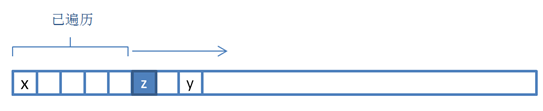
在第二步中,以[x, z)区间内的元素为起始字符的所有子字符串得到遍历。下一轮次的第一步会以z为起始字符进行寻找。如此往复,随着窗口交替伸展和收缩,所有的可能性(即以所有元素作为起始字符的子字符串)都会得到遍历。
IMPLEMENTATION
以上分析确定了滑动窗口算法的大致框架。至于如何记录窗口的状态、判断窗口是否满足条件,题目中挖了一个小坑。
乍一看,似乎可以用HashSet保存T中的字符(且称为重要字符),用来查看T中是否存在某字符。用另一个HashSet记录窗口中出现的重要字符,并用一个counter记录窗口中重要字符的个数,若与T的长度相等则认为符合条件。看起来天衣无缝,但如果T中存在重复字符,如"AABCC",则该方法不再有效。
可对该方法做一个小改进使之可以符合题意:用HashMap来保存重要字符及出现的次数。如果T为"AABCC",则保存为[A--2, B--1, C--2]。另用一个HashMap记录窗口中的重要字符及数量,用counter记录窗口中达到次数的不重复的重要字符数。如A出现2次则counter可加1,B出现1次counter即可加1,同理,C必须出现2次counter才可加1。通过将counter的值与第一个HashMap的size对比来判断窗口是否满足条件。
写代码时,若以句为单元进行思考则写起来费时且易出错,特别是边界条件上的错误。一个比较靠谱的方法是先写一个大致框架,然后将细节填入。只要框架合理,代码一般错不了。
先用注释勾勒出大致框架。(可以当作流程图看,重要的是那两个while内部的安排)
public String minWindow(String s, String t) { //创建HashMap1,将t中字符及出现次数存入 //初始化窗口、窗口的HashMap2、counter //创建minLength记录最小字符串的长度;创建result保存当前找到的最小字符串 while(/*窗口右端未超出s*/) { //记录右边界所指的元素到HashMap2 //若该元素次数满足条件,++counter //若窗口满足条件则让左边界慢慢收缩,否则跳过这个while,继续伸展右边界 while(/*counter == HashMap2.size()*/) { //若窗口长度小于minLength, 更新minLength、result //由于要收缩左边界,将HashMap2中记录的左边界元素减1 //如左边界元素次数不再满足条件,--counter l++; //收缩左边界 } r++; //伸展右边界 } return result; }
如果理解了以上框架便不难填入细节,细节实现在下面,供参考。(注:这是一个正确的解法,但并不是最优的解法,见优化一节)


1 public String minWindow(String s, String t) { 2 if(s == null || t== null || t.length() == 0 || s.length() == 0) 3 return s; 4 5 //创建HashMap1 6 HashMap<Character, Integer> required = new HashMap<>(); 7 //初始化窗口、窗口的HashMap2、counter 8 HashMap<Character, Integer> contained = new HashMap<>(); 9 int l = 0, r = 0, counter = 0; 10 //创建minLength记录最小字符串的长度;创建result保存当前找到的最小字符串 11 int minLength = Integer.MAX_VALUE; 12 String result = ""; 13 14 //将t中字符及出现次数存入 15 for(int i = 0; i < t.length(); i++) { 16 int count = required.getOrDefault(t.charAt(i), 0); 17 required.put(t.charAt(i), count + 1); 18 } 19 20 while(r < s.length()/*窗口右端未超出s*/) { 21 char current = s.charAt(r); 22 if(required.containsKey(current)){ 23 //记录右边界所指的元素到HashMap2 24 int count = contained.getOrDefault(current, 0); 25 contained.put(current, count + 1); 26 //若该元素次数满足条件,++counter 27 if(contained.get(current).intValue() == required.get(current).intValue()) 28 ++counter; 29 } 30 31 //若窗口满足条件则让左边界慢慢收缩,否则跳过这个while,继续伸展右边界 32 while(counter == required.size()/*counter == HashMap2.size()*/) { 33 //若窗口长度小于minLength, 更新minLength、result 34 if(r - l + 1 < minLength) { 35 result = s.substring(l, r + 1); 36 minLength = r - l + 1; 37 } 38 char toDelete = s.charAt(l); 39 if(required.containsKey(toDelete)) { 40 //由于要收缩左边界,将HashMap2中记录的左边界元素减1 41 contained.put(toDelete, contained.get(toDelete) - 1); 42 //如左边界元素次数不再满足条件,--counter 43 if(contained.get(toDelete).intValue() == required.get(toDelete).intValue() - 1) 44 --counter; 45 } 46 l++; //收缩左边界 47 } 48 r++; //伸展右边界 49 } 50 return result; 51 }
注意在27及43行,比较Integer的值时,必须用.intValue()进行比较,否则比较的是Integer对象的地址。当Integer对象的值较小时,对象存在常量池中,用contained.get(current) == required.get(current)直接比较不会出错。但Integer值比较大从而无法放入常量池时会出错,导致counter永远不被更新,错误地返回空字符串。
复杂度
空间上用了两个HashMap,复杂度为O(n + m),n和m分别为s和t的长度。
时间上,滑动窗口算法本身含有左右两个指针,这两个指针都只向右移动,最差的情况是每个元素都被两个指针各遍历一遍,所以滑动窗口的时间为2n。由于还要对t进行遍历来记录其中的字符,所以总的时间复杂度为O(n + m)。
优化
在leetcode使用的代码引擎中,上述实现的执行时间为33ms,在所有的java实现中仅排名77%。
最优实现为2ms,非常简洁,抄录如下
1 class Solution { 2 public String minWindow(String s, String t) { 3 int[] map = new int[128]; 4 for (char c : t.toCharArray()) 5 map[c]++; 6 int counter = t.length(), begin = 0, end = 0, distance = Integer.MAX_VALUE, head = 0; 7 while (end < s.length()) { 8 if (map[s.charAt(end++)]-- > 0) 9 counter--; 10 while (counter == 0) { // valid 11 if (end - begin < distance) 12 distance = end - (head = begin); 13 if (map[s.charAt(begin++)]++ == 0) 14 counter++; // make it invalid 15 } 16 } 17 return distance == Integer.MAX_VALUE ? "" : s.substring(head, head + distance); 18 } 19 }
大致框架跟上面的实现差不多,优化点如下:
- 用数组而非HashMap存取字符,因为不需要算哈希值及在桶中遍历元素,性能有所提升
- 直接在原数组的基础上做减法,这样就不需要第二个HashMap,且免去了containsKey()等方法的调用,简洁又高效
- 每次更新子字符串时,不求出字符串的值,只记录head和distance,从而substring()方法只在最后调用一次
另外一个优化的思路是先遍历一遍s,记录其中所有重要元素的位置,然后l和r只在这些位置上进行移动。由于仍然需要遍历,时间复杂度仍然是O(n + m),只是滑动窗口本身的复杂度被减小了。这种方法在leetcode的test case进行测试对性能的提升结果不明显,大概在秒级。比较适用于s中重要元素的个数远小于s的长度的情况,即t的长度相对比较短,且s中含有许多t中没有的元素。