1、oracle索引空值问题
当在有空值得列上建立单列索引时,如果搜索条件为 is null 在解释计划中可以看到,对于此列oracle并没有使用索引查询;
但是当建立的是多列索引是,就会按照索引来进行查询。
2、B-树索引
示意图:
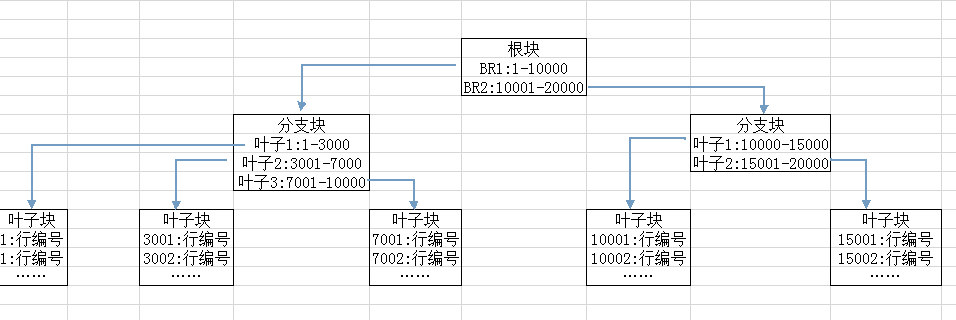
在B-树索引中,将会按照从上到下的顺序进行索引。如果列的选择度不低的话,索引扫描就会很慢。原因就在于要遍历很多的叶子快来取出不同的行编号。
随着出入数据的增多,最右侧的叶子块也在一直的增大,可能会导致缓冲区的繁忙等待。这种类型的最右侧索引的快速增长被称为 右侧增长索引 。后面将谈到一些解决方法。
3、位图索引
位图索引不适合用于需要大量DML操作的表(DML指除select以外的SQL语句)。适合用于大多数数据具有较少的唯一的列进行的只读运算的数据仓库表。
位图索引要注意的一点是。更新一个具有位图索引的列,必须要更新位图索引。
4、分区索引
4.1、局部索引
局部索引使用LOCAL关键字来建立。
create index index_name on table_name (column_name) local;
当用到分区索引的时候,会直接查找匹配分区的内容,而不是查询每个分区。
4.2、全局索引
全局索引用GLOBAL来创建
4.3、散列分区
回归到B-数索引中所说到的右侧增长索引问题,就可以用散列分区的方式来进行分区。
与范围分区的方式不同散列分区是把所有的数据均匀的分布在不同的分区内。具体方法如下:
--范围分区
create table table2
partition by range(year)
(partition p_2012 values less than (2013),
partition p_2013 values less than (2014),
partition p_2014 values less than (2015),
partition p_max values less than (maxvalue)
)
as
select * from table1;
--散列分区
drop sequence sf;
create sequence sf cache 200;
drop table table3;
create table table3
partition by hash(sid)
partitions 32
as
select sf.nextval sid,t.* from table1 t;
--通过以下代码可以查到
select dbms_rowid.rowid_object(rowid) obj_id,count(*) from table3
group by dbms_rowid.rowid_object(rowid);
OBJ_ID COUNT(*)
---------- ----------
86232 4717
86236 4571
86240 4696
86257 4633
86234 4547
86235 4580
86241 4717
86249 4589
86250 4612
86251 4623
86261 4742
86238 4578
……
create unique index index_table3_sid on table3(sid) local;
select * from table3_sid where sid =10000;
--查看其解释计划,可以得到

5、压缩索引
压缩索引是B-树索引的一个变体,更适合于引导列中具有重复值的列
create index index_name on table_name(column1,column2,column3) compress N;
其中N为压缩前几项。例如N=2就是压缩column1,column2这两项索引。
压缩索引适用于引导列具有较少唯一值的索引。
6、基于函数的索引
create create index index_name on table_name(function_name(column1));
在select是必须加上function_name(column1)才能使用索引,只用column1的话,还是全表扫描。
7、反转键索引
也是一种解决右侧增长索引问题的一种方法,但是因为索引是反转的所以不能使用范围运算符
create index index_name on table_name (column_name) global reverse;
不常用,因为会引起其他的一些负面影响