Linux 最重要的三个命令在业界被称为三剑客,它们是:awk、sed、grep。本文要讲的是 grep 命令。
我们在使用 Linux 系统中,grep 命令的使用尤为频繁,熟练掌握 grep 的常见用法,能够极大地提高你的工作效率。
grep 命令是一种强大的文本搜索工具,它能使用正则表达式,按照指定的模式去匹配,并把匹配的行打印出来。需要注意的是,grep 只支持匹配而不能替换匹配的内容,替换的功能可以由 sed 来完成。
整体上 grep 还是比较简单的,文中不会详细列举所有的选项和参数,会以多个具体示例来说明 grep 的使用方法和场景,帮助你快速学会 grep 的常见用法。
示例实战
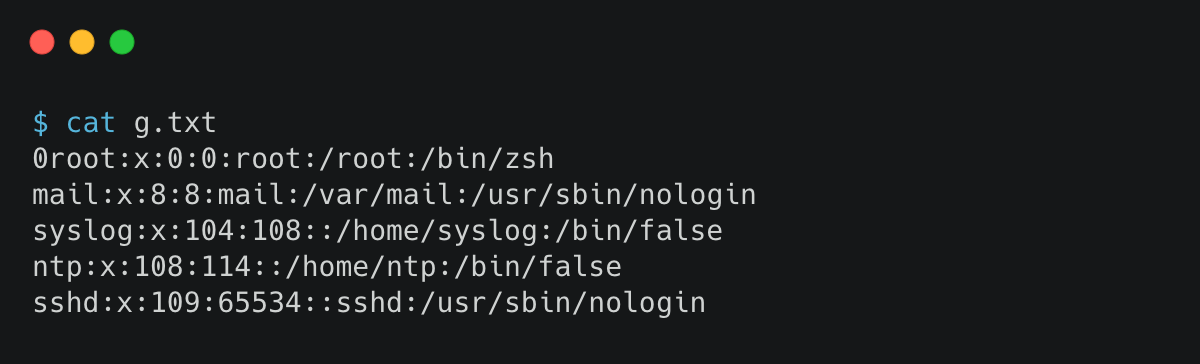
废话不说了,直接实战。文章中的示例 需要一个样例文件,文件内容如下:
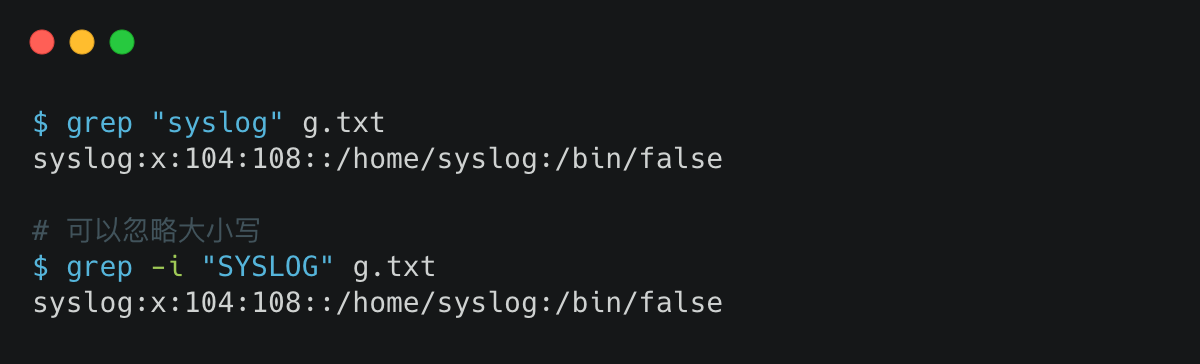
1. 把包含 syslog 的行过滤出来
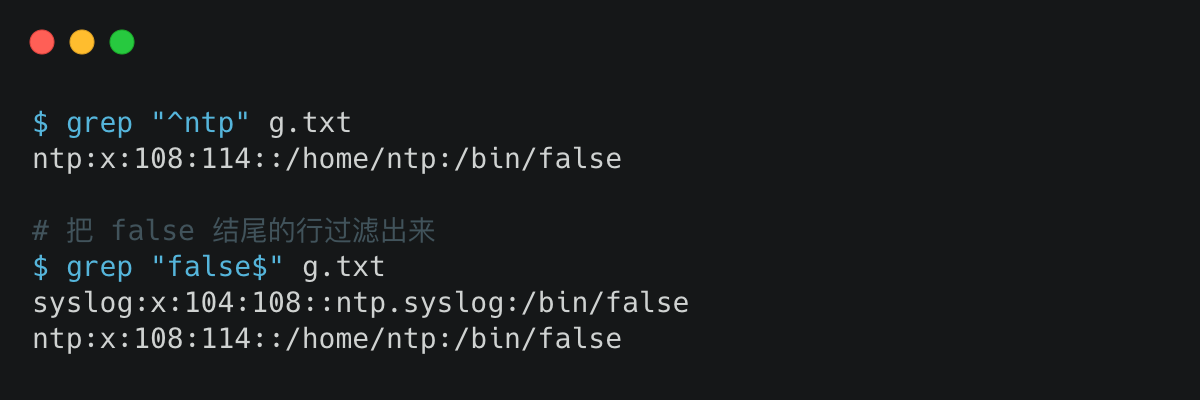
2. 把以 ntp 开头的行过虑出来
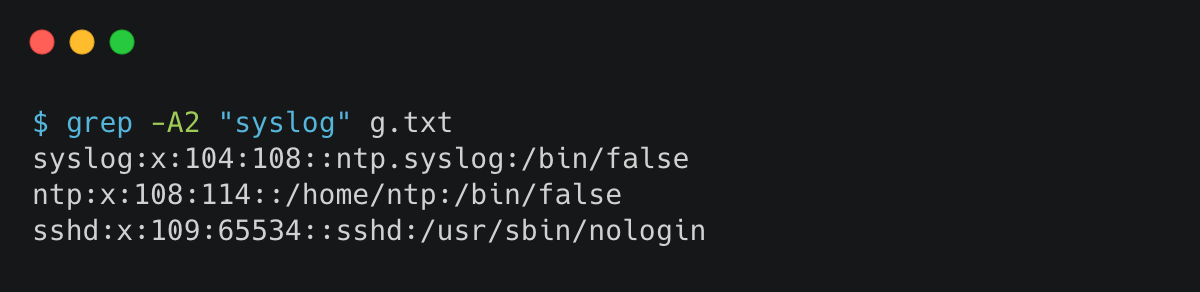
3. 把匹配 ntp 的行以及下边的两行过滤出来
4. 把包含 syslog 及上边的一行过滤出来

5. 把包含 syslog 以及上、下一行内容过滤出来
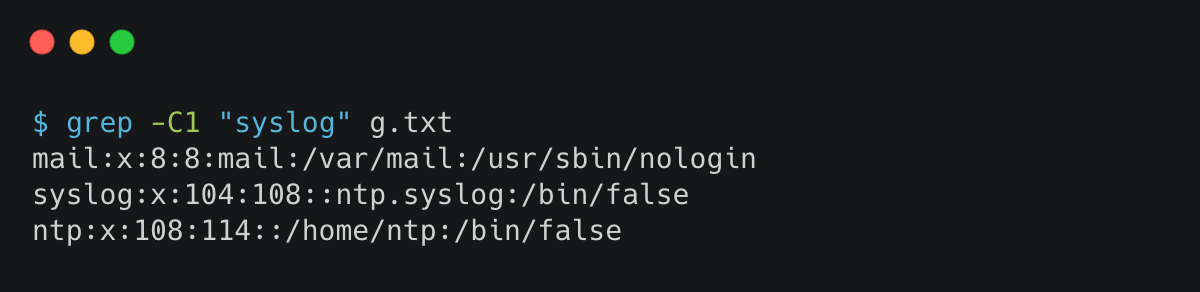
6. 过滤某个关键词,并输出行号
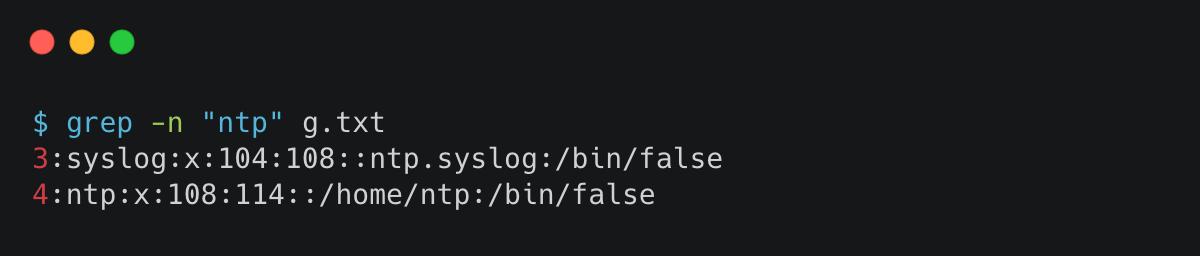
7. 过滤不包含某关键词,并输出行号
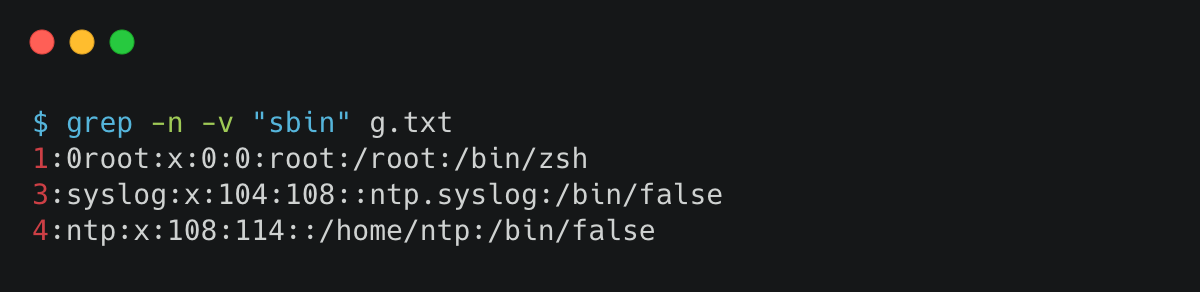
8. 删除掉空行

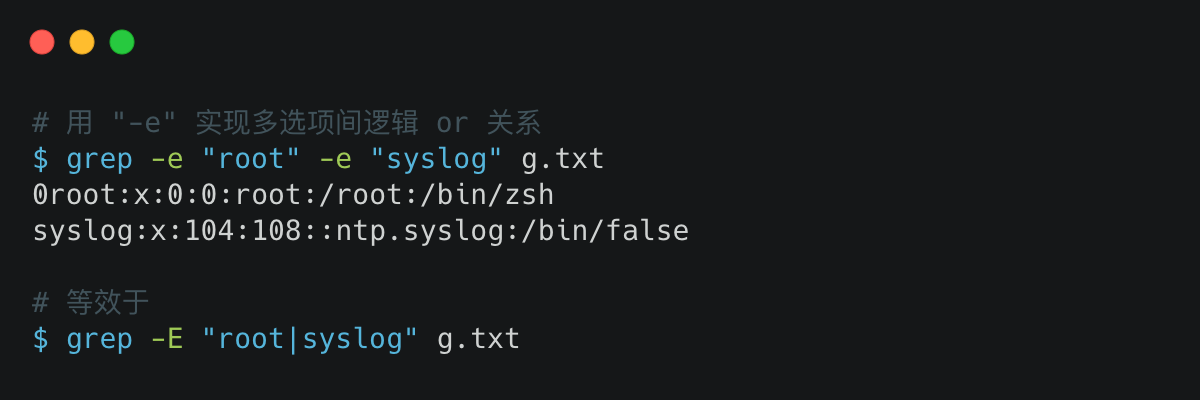
9. 过滤包含 root 或 syslog 的行
10. 查看当前目录中包含某关键词的所有文件(这个很有用)

简单总结
通过了一些简单案例操作,我们应该已经熟悉了 grep 的常见用法,下边再来简单总结 grep 的常见选项,相信在实战练习后再来总结应该会有更好的学习效果。
-A:除了匹配行,额外显示该行之后的N行-B:除了匹配行,额外显示该行之前的N行-C:除了匹配行,额外显示该行前后的N行-c:统计匹配的行数-e:实现多个选项间的逻辑 or 关系-E:支持扩展的正则表达式-F:相当于 fgrep-i:忽略大小写-n:显示匹配的行号-o:仅显示匹配到的字符串-q:安静模式,不输出任何信息,脚本中常用-s:不显示错误信息-v:显示不被匹配到的行-w:显示整个单词--color:以颜色突出显示匹配到的字符串
与 grep 相似的工具还有 egrep、fgrep,实用性并不强,其功能完全可以通过 grep 的扩展参数来实现,所以就不再扩展。
好了,本次分享就到这里了!谢谢大家,我是肖邦,欢迎关注后续的精彩内容。
出处:https://www.cnblogs.com/liwei0526vip/p/14337738.html
=======================================================================================
介绍
熟悉 Linux 的同学一定知道大名鼎鼎的 Linux 三剑客,它们是 grep、awk、sed,我们今天要聊的主角就是 sed。
sed 全名叫 stream editor,流编辑器,用程序的方式来编辑文本,与 vim 的交互式编辑方式截然不同。它的功能十分强大,加上正则表达式的支持,可以进行大量的复杂文本的编辑操作。
实际上 sed 提供的功能非常复杂,有专门的书籍讲解它。本文不会讲 sed 的全部东西,只会从 sed 的工作原理、常见使用方法等方面进行说明和讲解,同时也会给出大量的实践用例来帮助更好的理解 sed 基本用法。文中的知识点真正掌握后,足以应付平时工作中的基本需求。
它有自己的使用场景:
- 自动化程序中,不适合交互方式编辑的;
- 大批量重复性的编辑需求;
- 编辑命令太过复杂,在交互文本编辑器难以输入的情况;
工作原理
sed 作为一种非交互式编辑器,它使用预先设定好的编辑指令对输入的文本进行编辑,完成之后输出编辑结果。
简单描述 sed 工作原理:
- sed 从输入文件中读取内容,每次处理一行内容,并把当前的一行内容存储在临时的缓冲区中,称为
模式空间。 - 接着用 sed 命令处理缓存区中的内容;
- 处理完毕后,把缓存区的内容送往屏幕;
- 接着处理下一行;
这样不断重复,直到文件末尾,文件内容并没有改变,除非你使用重定向输出或指定了 i 参数
正则表达式
sed 基本上就是在玩正则表达式模式匹配,所以,会玩 sed 的人,正则表达式能力一般都比较强。正则表达式内容相对较多,本节不会重点讲解正则表达式。
为了能够让大部分朋友比较轻松地学习本文知识,这里还是简单介绍下正则表达式的基本内容。如果是专门做正则编程开发的,可以去买本正则的书籍来看。
(一)基本正则表达式
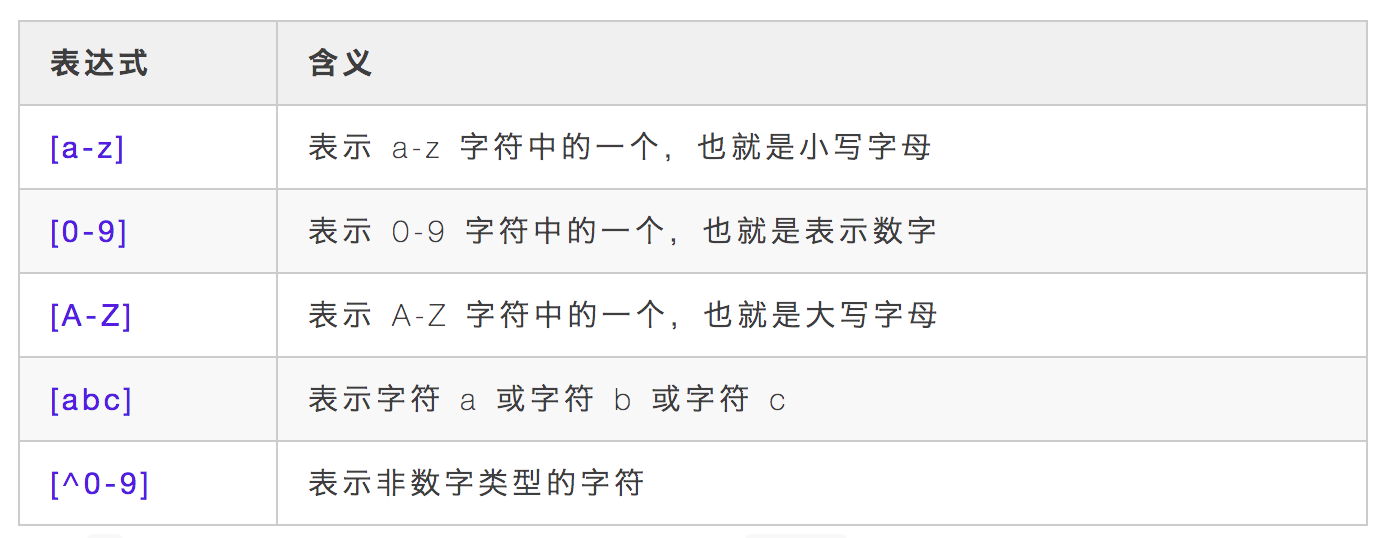
.,表示匹配任意一个字符,除了换行符,类似 Shell 通配符中的?;*,表示前边字符有 0 个或多个;.*,表示任意一个字符有 0 个或多个,也就是能匹配任意的字符;^,表示行首,也就是每一行的开始位置,^abc匹配以 abc 开头的字符串;$,表示行尾,也就是每一行的结尾位置,}$匹配以大括号结尾的字符串;{},表示前边字符的数量范围,{2},表示重复 2 次,{2,}重复至少 2次,{2,4}重复 2-4 次;[],括号中可以包含表示字符集的表达式,使用方法大概如下几种
(二)扩展正则表达式
扩展正则表达式使用频率上没有基本表达式那么高,但依然很重要,很多情况下没有扩展正则是搞不定的,sed 命令使用扩展正则时需要加上选项 -r。
?:表示前置字符有 0 个或 1 个;+:表示前置字符有 1 个或多个;|:表示匹配其中的一项即可;():表示分组,(a|b)b表示可以匹配 ab 或 bb 子串,且命令表达式中可以通过1、2来表示匹配的变量{}:和基本正则中的大括号中意义相同,只不过使用时不用加 转义符号;
基本语法
先介绍下 sed 的基本语法。
sed [选项] 'command' filename
选项部分,常见选项包括:-n、-e、-i、-f、-r 等。
command 子命令格式:
[地址1, 地址2] [函数] [参数(标记)]
选项简单说明:
-n,表示安静模式。默认 sed 会把每行内容处理完毕后打印到屏幕上,加上选项后就不会输出到屏幕上。-e,如果需要用 sed 对文本内容进行多种操作,则需要执行多条子命令来进行操作;-i,默认 sed 只会处理模式空间的副本内容,不会直接修改文件,如果需要修改文件,就要指定-i选项;-f,如果命令操作比较多时,用-e会有点力不从心,这时需要把多个子命令写入脚本文件,使用-f选项指定执行该脚本;-r:如果需要支持扩展正则表达式,那么需要添加-r选项;
数字定址和正则定址
默认情况下 sed 会对每一行内容进行匹配、处理、输出,有时候我们不需要对所有内容进行操作,只需要修改一种一部分,比如 1-10 行,偶数行,或包括 hello 字符串的行。
这种情况下,就需要我们去定位特定的行来进行处理,而不是全部内容,这里把定位指定的行叫做 定址。
(一)数字定址
数字定址其实就是通过数字去指定要操作的行,有几种方式,每种方式都有不同的应用场景。
# 只将第4行中hello替换为A
$ sed '4s/hello/A/g' file.txt
# 将第2-4行中hello替换为A
$ sed '2,4s/hello/A/g' file.txt
# 从第2行开始,往下数4行,也就是2-6行
$ sed '2,+4s/hello/A/g' file.txt
# 将最后1行中hello替换为A
$ sed '$s/hello/A/g' file.txt
# 除了第1行,其它行将hello替换为A
$ sed '1!s/hello/A/g' file.txt
(二)正则定址
正则定址,是通过正则表达式的匹配来确定需要处理编辑哪些行,其它行就不需要处理
# 将匹配到hello的行执行删除操作,d 表示删除
$ sed '/hello/d' file.txt
# 删除空行,"^$" 表示空行
$ sed '/^$/d' file.txt
# 将匹配到以ts开头的行到以te开头的行之间所有行进行删除
$ sed '/^ts/,/^te/d' file.txt
(三)数字定址和正则定址混用
数字定址和正则定址可以配合使用
# 匹配从第1行到ts开头的行,把匹配的行执行删除
$ sed '1,/^ts/d' file.txt
基本子命令
(一)替换子命令s
子命令 s 为替换子命令,是平时 sed 使用最多的命令,因为支持正则表达式,功能很强大,基本可以替代 grep 的基本用法。
基本语法:
[address]s/pat/rep/flags
替换子命令基本用法
# 将每行的hello替换为HELLO,只替换匹配到的第一个
$ sed 's/hello/HELLO/' file.txt
# 将匹配到的hello全部替换为HELLO,g表示替换一行所有匹配到的
$ sed 's/hello/HELLO/g' file.txt
# 将第2次匹配到的hello替换
$ sed 's/hello/A/2' file.txt
# 将第2次后匹配到的所有都替换
$ sed 's/hello/A/2g' file.txt
# 在行首加#号
$ sed 's/^/#/g' file.txt
# 在行尾加东西
$ sed 's/$/xxx/g' file.txt
正则表达式的简单使用
# 使用扩展正则表达式,结果为:A
$ echo "hello 123 world" | sed -r 's/[a-z]+ [0-9]+ [a-z]+/A/'
# <b>This</b> is what <span style="x">I</span> meant
# 要求:去掉上述html文件中的tags
$ sed 's/<[^>]*>//g' file.txt
多个匹配
# 将1-3行的my替换为your,且3行以后的This替换为That
$ sed '1,3s/my/your/g; 3,$s/This/That/g' my.txt
# 等价于
$ sed -e '1,3s/my/your/g' -e '3,$s/This/That/g' my.txt
使用匹配到的变量
# 将匹配到的字符串前后加双引号,结果为:My "name" chopin
# "&"表示匹配到的整个结果集
$ echo "My name chopin" | sed 's/name/"&"/'
# 如下命令,结果为:hello=world,"1"和"2"表示圆括号匹配到的值
$ echo "hello,123,world" | sed 's/([^,]),.*,(.*)/1=2/'
其它几个常见用法
# 只将修改匹配到行内容打印出来,-n关闭了模式空间的打印模式
$ sed -n 's/i/A/p' file.txt
# 替换是忽略大小写,将大小写i替换为A
$ sed -n 's/i/A/i' file.txt
# 将替换后的内容另存为一个文件
$ sed -n 's/i/A/w b.txt' file.txt
$ sed -n 's/i/A/' file.txt > b.txt
注意,sed 修改匹配到的内容后,默认行为是不保存到原文件,直接输出修改后模式空间的内容,如果要修改原文件需要指定 -i 选项。
(二)追加行子命令a
子命令 a 表示在指定行下边插入指定的内容行;
# 将所有行下边都添加一行内容A
$ sed 'a A' file.txt
# 将文件中1-2行下边都添加一行内容A
$ sed '1,2a A' file.txt
(三)插入行子命令i
子命令 i 和 a 使用基本一样,只不过是在指定行上边插入指定的内容行
# 将文件中1-2行上边都添加一行内容A
$ sed '1,2i A'
(四)替换行子命令c
子命令 c 是表示把指定的行内容替换为自己需要的行内容
# 将文件所有行都分别替换为A
$ sed 'c A' file.txt
# 将文件中1-2行内容替换为A,注意:两行内容变成了一行A
$ sed '1,2c A' file.txt
# 将1-2行内容分别替换为A行内容
$ sed '1,2c A
A' file.txt
(五)删除行子命令d
子命令 d 表示删除指定的内容行,这个很容理解
# 将文件中1-3行内容删除
$ sed '1,3d' file.txt
# 将文件中This开头的行内容删除
$ sed '/^This/d' file.txt
(六)设置行号子命令=
子命令 =,可以将行号打印出来
# 将指定行上边显示行号
$ sed '1,2=' file.txt
# 可以将行号设置在行首
$ sed '=' file.txt | sed 'N;s/
/ /'
(七)子命令N
子命令 N,把下一行内容纳入当缓存区做匹配,注意的是第一行的
仍然保留
其实就是当前行的下一行内容也读进缓存区,一起做匹配和修改,举个例子吧
# 将偶数行内容合并到奇数行
$ sed 'N;s/
//' file.txt
哈哈,是不是很简单?
实战练习
掌握了上边的基础命令操作后,基本上可以满足平时 95% 的需求啦。sed 还有一些高级概念,比如:模式空间、保持空间、高级子命令、分支和测试等,平时使用概率非常小,本文就暂不讲解了,有需要的同学可以私信我一起交流学习哈。
学习了这么多基础用法后,只要你勤加练习,多实践,多使用,一定可以得心应手,极大提高的文本处理效率。下边我简单再给出一些比较实用的操作实践,希望对大家有帮助。
1. 删除文件每行的第二个字符
$ sed -r 's/(.)(.)(.*)$/13/' file.txt
2. 交换每行的第一个字符和第二个字符
$ sed -r ‘s/(.)(.)(.*)/213/’ file.txt
3. 删除文件中所有的数字
$ sed 's/[0-9]//g' file.txt
4. 用制表符替换文件中出现的所有空格
$ sed -r 's/ +/ /g' file.txt
5. 把所有大写字母用括号()括起来
$ sed -r 's/([A-Z])/(1)/g'
6. 隔行删除
$ sed '0~2{d}' file.txt
7. 删除所有空白行
$ sed '/^$/d' file.txt
好了,以上是 sed 命令常用的全部内容。想要熟练掌握,只有多实践,多练习正则表达式的使用,一旦熟练掌握后,相信在日后工作中一定会产生巨大作用的。
谢谢大家,我是肖邦,欢迎关注后续的精彩内容。
出处:https://www.cnblogs.com/liwei0526vip/p/14328029.html
=======================================================================================
我们知道 Linux 三剑客,它们分别是:grep、sed、awk。在前边已经讲过 grep 和 sed,没看过的同学可以直接点击阅读,今天要分享的是更为强大的 awk。
sed 可以实现非交互式的字符串替换,grep 能够实现有效的过滤功能。与两者相比,awk 是一款强大的文本分析工具,在对数据分析并生成报告时,显得尤为强悍。

awk 强大的功能,是一般 Linux 命令无法比拟的。在本文中,我不会告诉你 awk 也是一种编程语言,免得会吓到你。我们只需把它当做 Linux 下一款强大的文本分析工具即可。
这篇文章,我仍然秉持着 实用、实践 原则,提供大量的示例,但不会面面俱到。通过本文可以帮助你,快速将 awk 运用起来,这些东西足够应付工作中大多数应用场景。
场景
学习具体使用前,先来看下 awk 能干些什么事情:
1. 能够将给定的文本内容,按照我们期望的格式输出显示,打印成报表。
2. 分析处理系统日志,快速地分析挖掘我们关心的数据,并生成统计信息;
3. 方便地用来统计数据,比如网站的访问量,访问的 IP 量等;
4. 通过各种工具的组合,快速地汇总分析系统的运行信息,让你对系统的运行了如指掌;
5. 强大的脚本语言表达能力,支持循环、条件、数组等语法,助你分析更加复杂的数据;
……
当然 awk 不仅能做这些事情,当你将它的用法融汇贯通时,可以随心所欲的按照你的意愿,来进行高效的数据分析和统计。
不过我们需要知道,awk 不是万能的,它比较擅长处理格式化的文本,比如 日志、csv 格式数据等;
原理
我们先来简单了解 awk 基本工作原理,通过下边的图文讲述,希望你能了解 awk 到底是如何工作的。
awk 基本命令格式
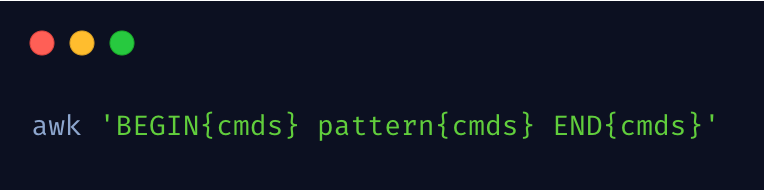
结合下图来详细说明 awk 工作原理
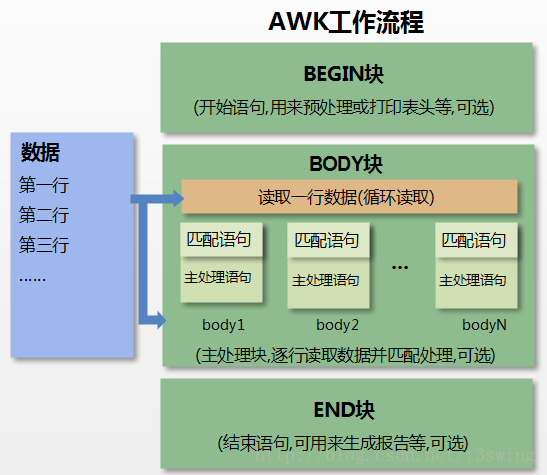
- 首先,执行关键字
BEGIN标识的{}中的命令; - 完成
BEGIN大括号中命令的后,开始执行body命令; - 逐行读取数据,默认读到
- 将记录按照指定的分隔符划分为 字段,其实就是列的概念;
- 循环执行
body块中的命令,每读取一行,执行一次body,最终完成body执行; - 最后,执行
END命令,通常会在END中输出最后的结果;
awk 是输入驱动的,有多少输入行,就会执行多少次 body 命令。
我们在下边的示例学习中,要时刻记着:记录 (Record) 就是行,字段 (Field) 就是列,BEGIN 是预处理阶段,body 是 awk 真正工作的阶段,END 是最后处理阶段。
实战 - 入门
从下边内容开始,我们直接进入到实战。为了方便举例,我先把如下信息保存到 file.txt
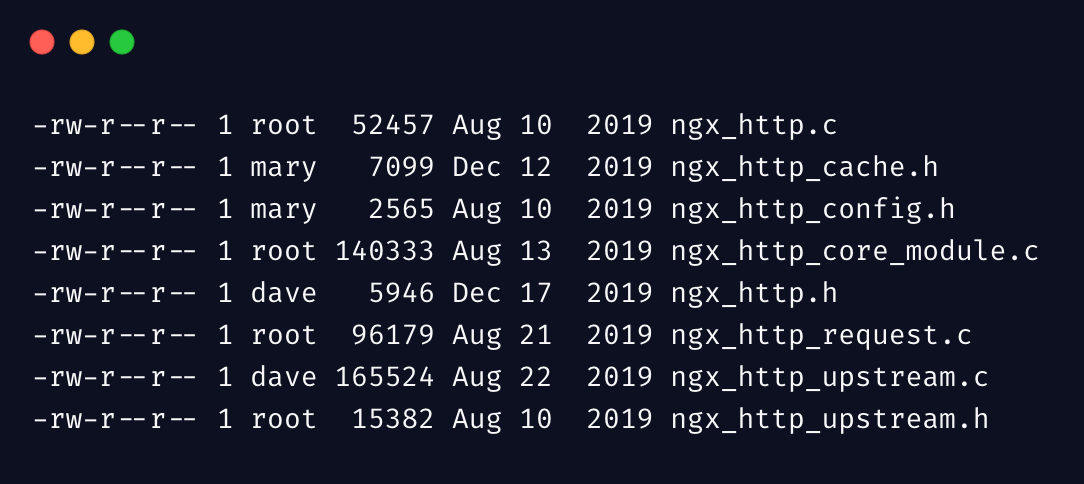
好了,我们先来一个最简单最常用的 awk 示例,输出第 1、4、8 列:
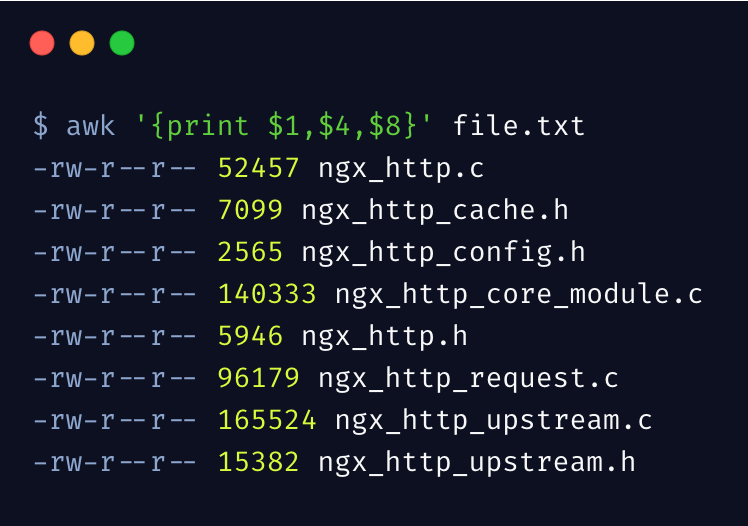
大括号里边的就是 awk 语句,只能被单引号包含,其中,$1..$N表示第几列,$0 表示整个行内容
再来看下 awk 比较实用的功能 格式化输出。和 C 语言的 printf 格式输出是一毛一样,我个人特别喜欢这种格式化方式,而不是 C++ 中的流的方式。
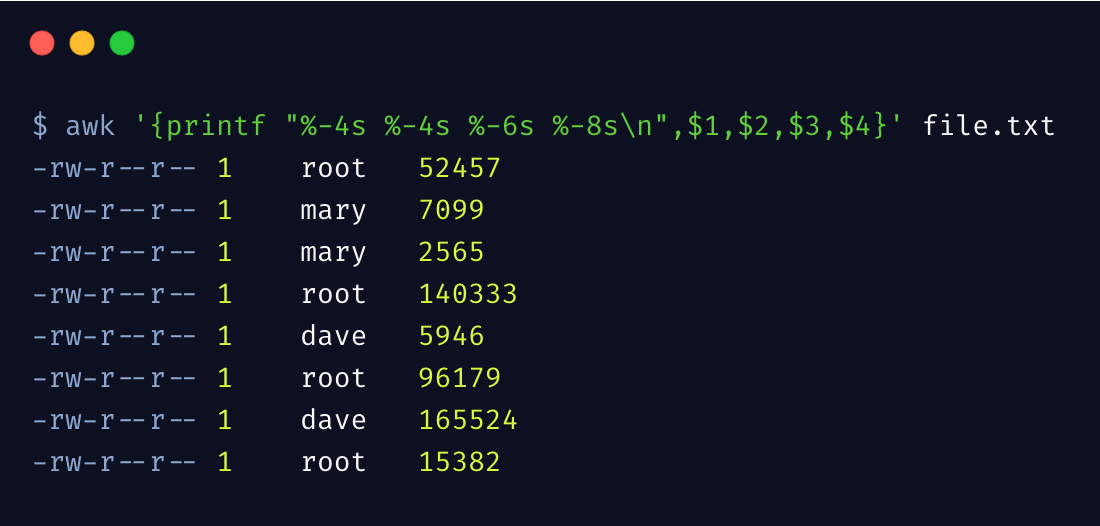
%s 表示字符串占位符,-4表示列宽度为 4,且左对齐,我们还可以根据需要,列出更复杂的格式来,这里先不详细举例了。
实战 - 进阶
(一)过滤记录
有些数据可能不是你想要的,可以根据需要进行过滤
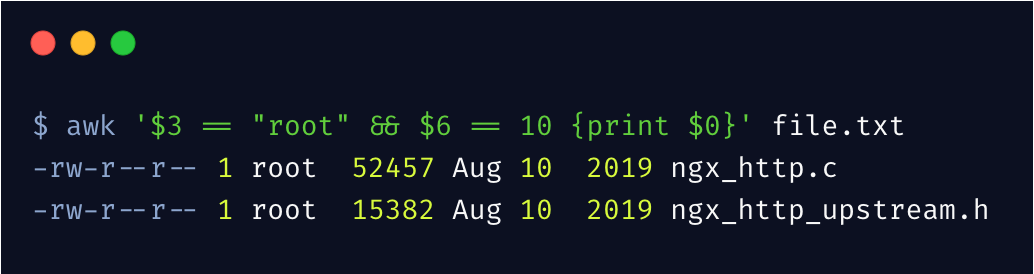
上边的过滤条件为,第 3 列为 root 且第 6 列为 10 的行,才会被输出。
awk 支持各种比较运算符号 !=、>、<、>=、<=,其中 $0 表示整行的所有内容。
(二)内置变量
awk 内置了一些变量,更方便我们对数据的处理
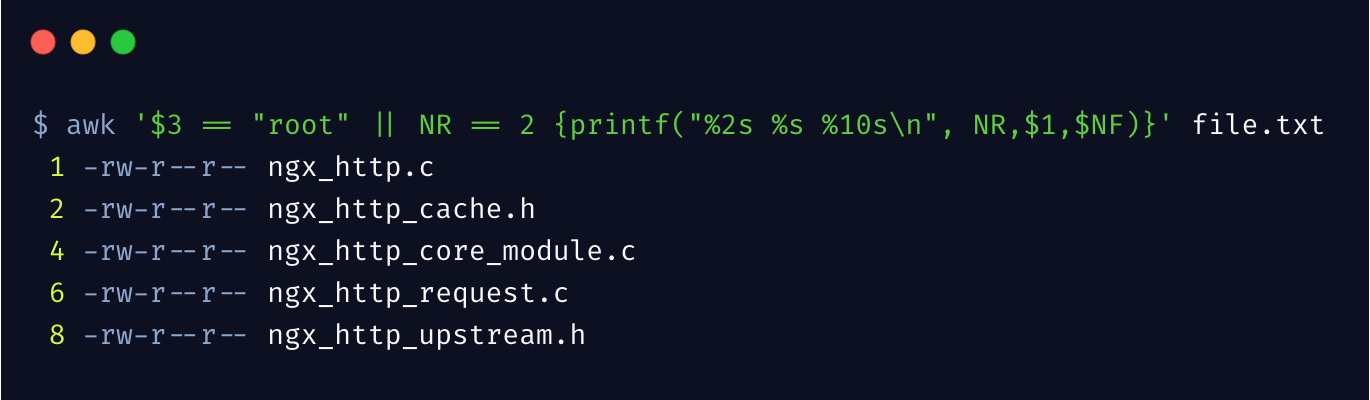
过滤第 3 列为 root 用户,以及第 2 行内容,且打印时输出行号。NR 表示当前第几行,NF表示当前行有几列。
(三)指定分隔符
我们的数据,不总是以空格为分隔符,我们可以通过 FS 变量指定分隔符。
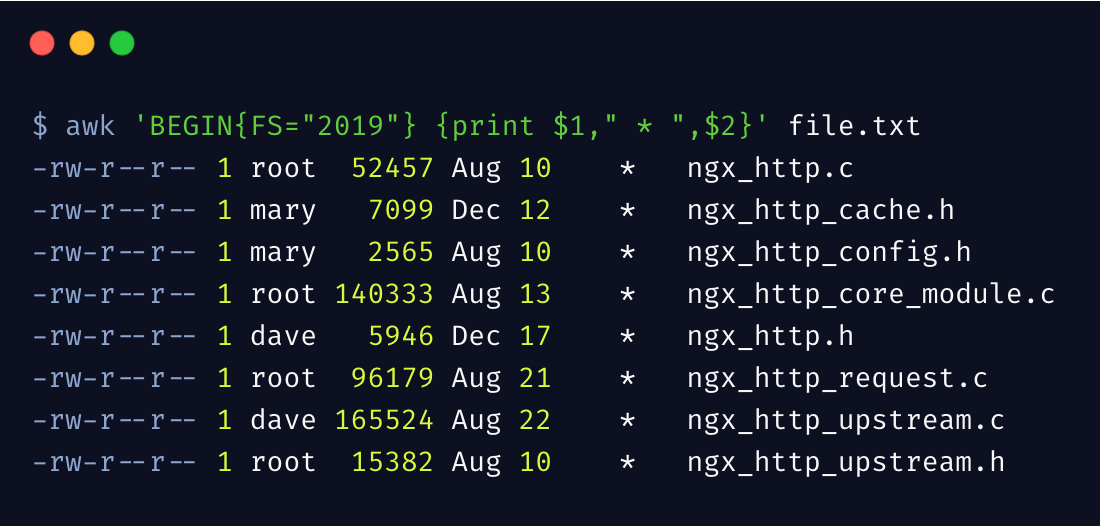
我们指定分隔符为 2019,这样就将行内容分割为了两部分,将 2019 替换成了 *
上边的命令也可以通过 -F 选项指定分割符
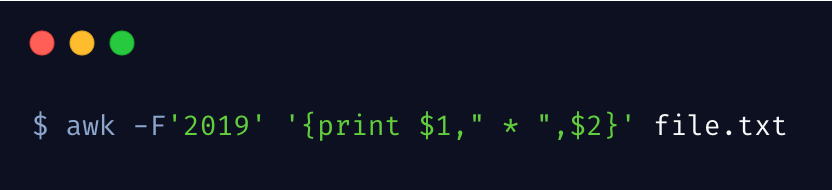
如果你需要指定多个分隔符,可以这样做 -F '[;:]'。相信聪明的你,一定能够理解并融会贯通的。
同样,awk 可以指定输出时的分隔符,通过 OFS 变量来设置
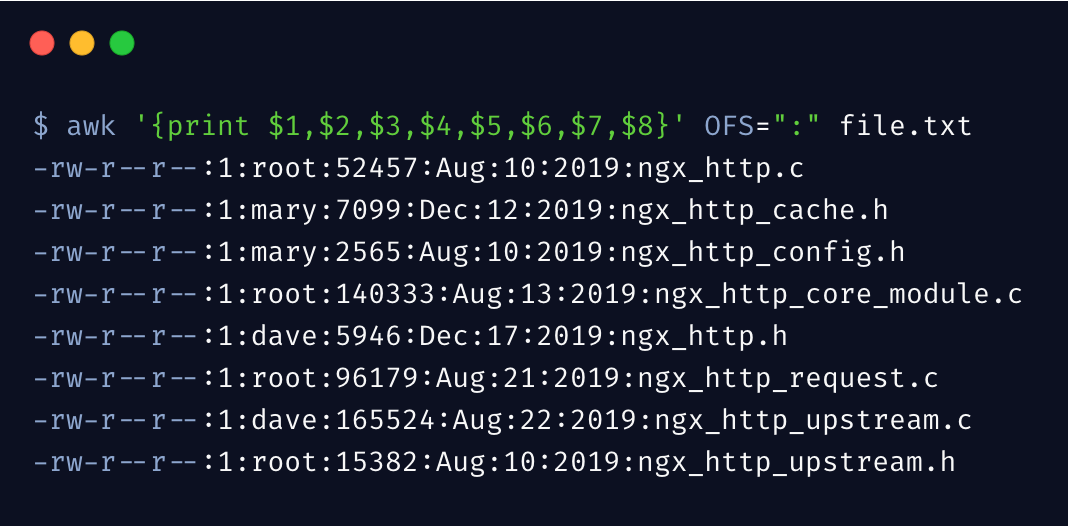
输出时,各字段用 OFS 指定的符号进行了分隔。
实战 - 高级
(一)条件匹配
列出 root 用户的所有文件,以及第一行文件
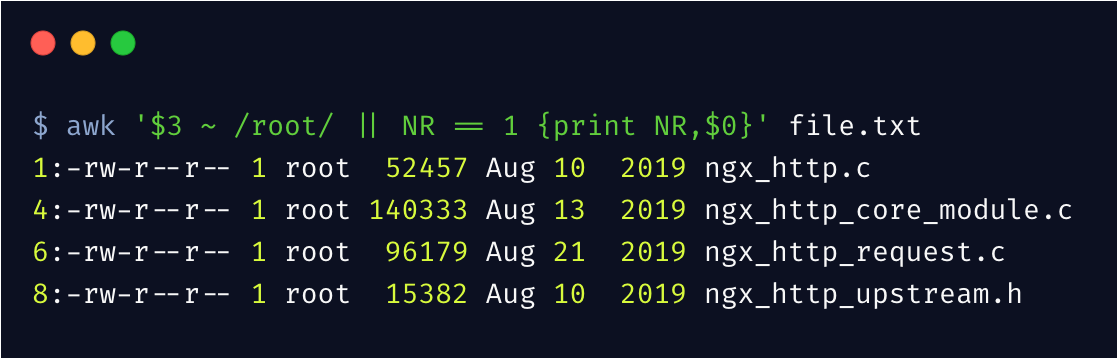
上边匹配第三列中包含 root 的行,~ 其实就是正则表达式的匹配。
同样,awk 可以像 grep 一样匹配某一行,就像这样
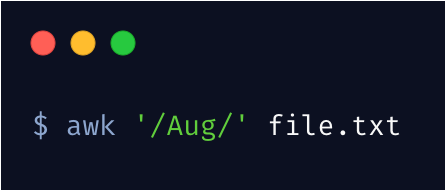
另外,可以这样 /Aug|Dec/ 匹配多个关键词。
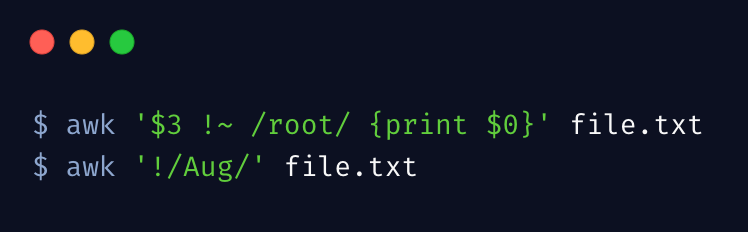
模式取反可以使用 ! 符号
(二)拆分文件
我们来做一件有意思的事情,可以将文本信息拆分为多个文件,下边命令按照月份(第5列)将文件信息拆分为多个文件
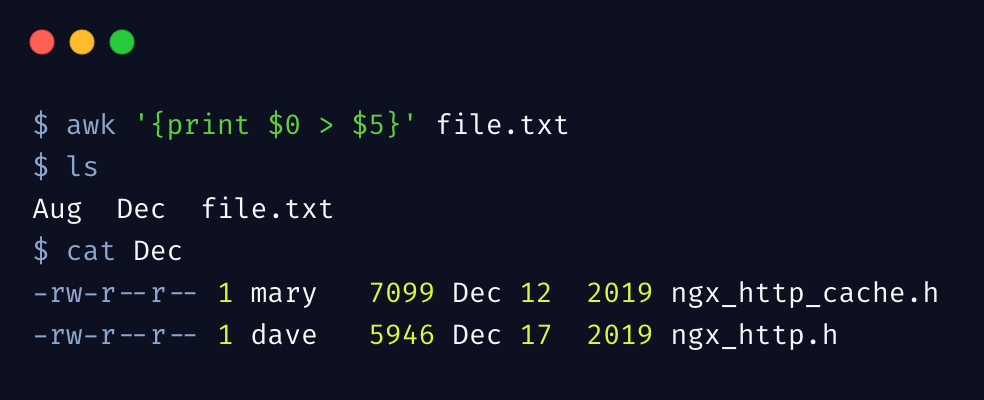
awk 支持重定向符号 >,直接将每行内容重定向到月份命名的文件了,当然你也可以把指定的列输出到文件
(三)if 语句
复杂的条件判断,可以使用 awk 的 if 语句,awk 的强大正因为它是个脚本解释器,拥有一般脚本语言的编程能力,下边示例通过稍微复杂的条件进行拆分文件
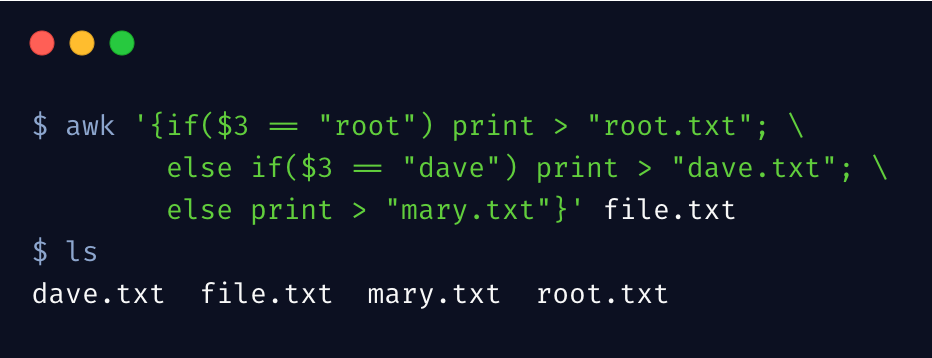
要注意,if 语句是在大括号里边的。
(四)统计
统计当前目录下,所有 *.c、*.h 文件所占用空间大小总和

第 5 列表示文件大小,每读取一行就会将该文件大小计算到 sum 变量中,在最后 END 阶段打印出 sum,也就是所有文件的大小总和。
再来看一个例子,统计每个用户的进程占用了多少内存,注意取值的是 RSS 那一列
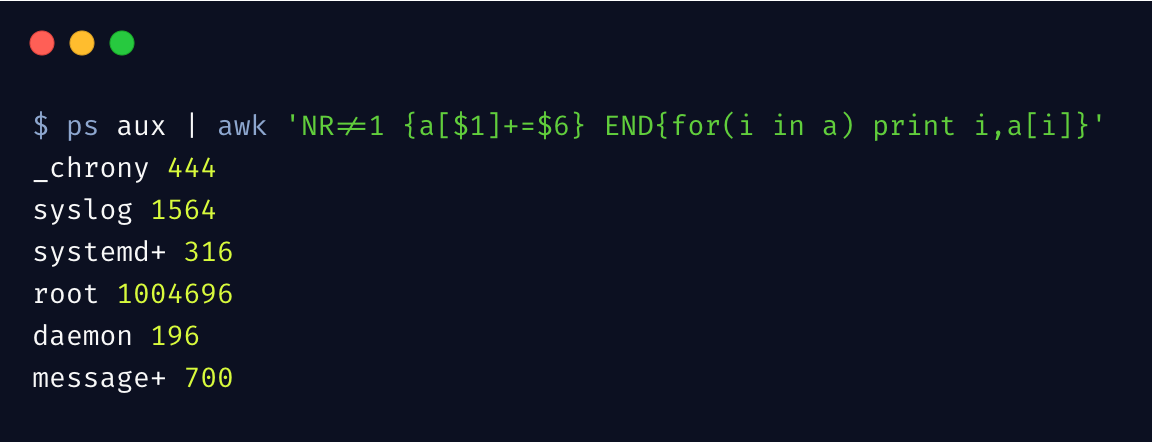
这里用到了 数组 和 for 循环,值得一提的是,awk 的数组可以理解为字典或 Map,key 可以是数值和字符串,这种数据类型在平时很常用。
(五)字符串
通过下边简单示例,展示 awk 对字符串操作的支持
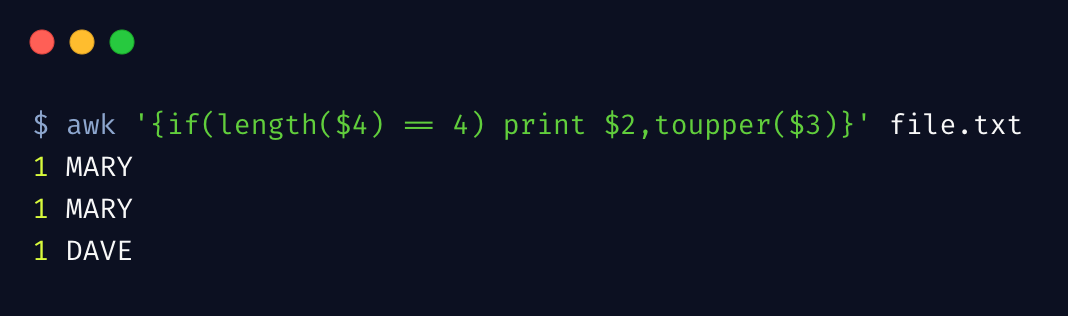
awk 内置支持一系列的字符串函数,length 计算字符串长度,toupper 函数转换字符串为大写。
实战 - 技巧
为了从整体上理解 awk 工作机制,我们再来看一个综合的示例,假设有一个学生成绩单:
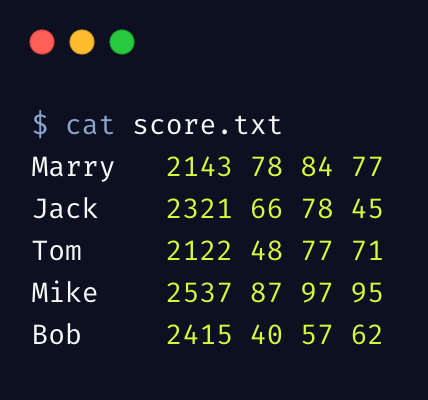
由于此示例程序稍显复杂,在命令行上不易读,另外呢,也想通过此案例介绍另外一种 awk 的执行方式,我们的 awk 脚本如下:

执行 awk 结果如下
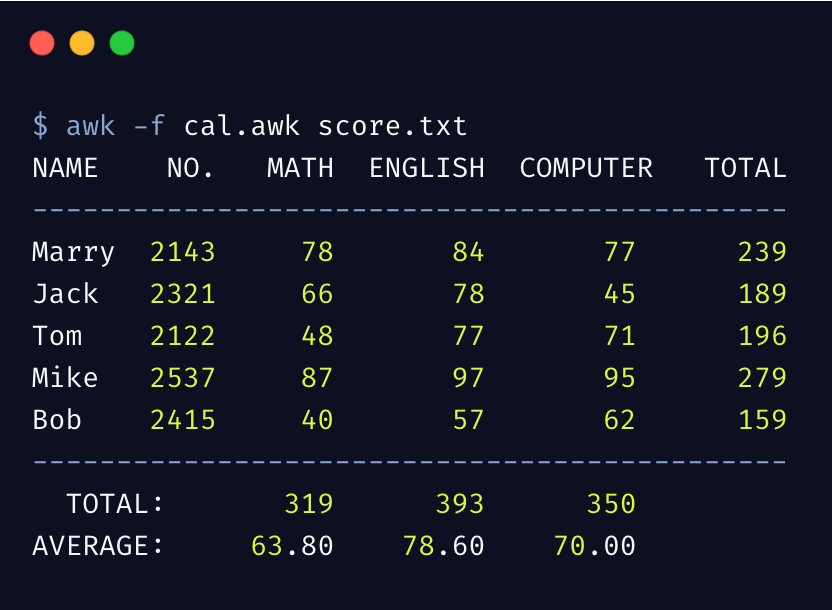
我们可以将复杂的 awk 语句写入脚本文件 cal.awk,然后通过 -f 选项指定从脚本文件执行。
- 在
BEGIN阶段,我们初始化了相关变量,并打印了表头的格式 - 在
body阶段,我们读取每一行数据,计算该学科和该同学的总成绩 - 在
END阶段,我们先打印了表尾的格式,并打印总成绩,以及计算了平均值
这个简单示例,完整的体现了 awk 的工作机制和原理,希望通过此示例能够帮你真正理解 awk 是如何工作的。
总结归纳
通过上述的示例,我们学习到了 awk 的工作原理,下边我们来总结下几个概念和常用的知识点。
(一)内置变量
1. 每一行内容记录,叫做记录,英文名称 Record
2. 每行中通过分隔符隔开的每一列,叫做字段,英文名称 Field
明确这几个概念后,我们来总结几个重要的内置变量:
NR:表示当前的行数;NF:表示当前的列数;RS:行分隔符,默认是换行;FS:列分隔符,默认是空格和制表符;OFS:输出列分隔符,用于打印时分割字段,默认为空格ORS:输出行分隔符,用于打印时分割记录,默认为换行符
(二)输出格式
awk 提供 printf 函数进行格式化输出功能,具体的使用方式和 C 语法基本一致。
基本用法
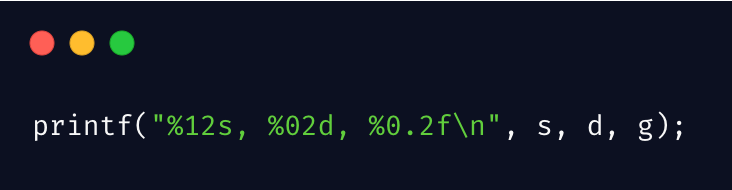
常用的格式化方式:
%d十进制有符号整数%u十进制无符号整数%f浮点数%s字符串%c单个字符%e指数形式的浮点数%x%X无符号以十六进制表示的整数%0无符号以八进制表示的整数%g自动选择合适的表示法
(三)编程语句
awk 不仅是一个 Linux 命令行工具,它其实是一门脚本语言,支持程序设计语言所有的控制结构,它支持:
- 条件语句
- 循环语句
- 数组
- 函数
(四)常用函数
awk 内置了大量的有用函数功能,也支持自定义函数,允许你编写自己的函数来扩展内置函数。
这里只简单罗列一些比较常用的字符串函数:
index(s, t)返回子串 t 在 s 中的位置length(s)返回字符串 s 的长度split(s, a, sep)分割字符串,并将分割后的各字段存放在数组 a 中substr(s, p, n)根据参数,返回子串tolower(s)将字符串转换为小写toupper(s)将字符串转换为大写
这里只简单总结一些常用的字符串功能函数,具体使用方法,还需要你参照前边的示例程序,举一反三,运用到实际问题中。
本次分享就到这里了,谢谢大家的阅读,我是肖邦。关注我的公众号「编程修养」,大量的干货文章等你来!
出处:https://www.cnblogs.com/liwei0526vip/p/14540570.html
=======================================================================================

