一、基础数据类型补充内容
1、字符串
s1 = 'taobao jD shopping'
print(s1.capitalize()) #首字母大写,其余小写
print(s1.swapcase()) #大小写翻转
print(s1.title()) #每个单词的首字毒大写
ret2 = s1.center(30,"*") # 内同居中,总长度,空白处填充
print(ret2)
s1 = 'taobao jD shopping'
ret3 = s1.find('D') #find:通过元素找索引,找到第一个就返回,找不到返回-1
print(ret3)
ret4 = s1.index('d')
print(ret4) ## 返回的找到的元素的索引,找不到报错。
2、元组
python中元组有一个特性,元组中如果只含有一个元素且没有逗号,则该元组不是元组,与改元素数据类型一致,如果有逗号,那么它是元组。
tu = (1)
print(tu,type(tu)) # 1 <class 'int'>
tu1 = ('alex')
print(tu1,type(tu1)) # 'alex' <class 'str'>
tu2 = ([1, 2, 3])
print(tu2,type(tu2)) # [1, 2, 3] <class 'list'>
tu = (1,)
print(tu,type(tu)) # (1,) <class 'tuple'>
tu1 = ('alex',)
print(tu1,type(tu1)) # ('alex',) <class 'tuple'>
tu2 = ([1, 2, 3],)
print(tu2,type(tu2)) # ([1, 2, 3],) <class 'tuple'>
元组也有一些其他的方法:
index:通过元素找索引(可切片),找到第一个元素就返回,找不到该元素即报错。
tu = ('太白', [1, 2, 3, ], 'WuSir', '女神')
print(tu.index('太白')) #0
print(tu.index('aaa')) #ValueError: tuple.index(x): x not in tuple
count: 获取某元素在列表中出现的次数
tu = ('太白', [1, 2, 3, ], '太白','WuSir', '太白','女神')
print(tu.count('太白'))
3、列表
列表的其他操作方法:
count(数)(方法统计某个元素在列表中出现的次数)
a = ["q","w","q","r","t","y"]
print(a.count("q"))
index(方法用于从列表中找出某个值第一个匹配项的索引位置)
a = ["q","w","r","t","y"]
print(a.index("r"))
sort (方法用于在原位置对列表进行排序)。
reverse (方法将列表中的元素反向存放)。
a = [2,1,3,4,5]
a.sort()# 他没有返回值,所以只能打印a
print(a)
a.reverse()#他也没有返回值,所以只能打印a
print(a)
列表也可以相加与整数相乘
l1 = [1, 2, 3]
l2 = [4, 5, 6]
print(l1 + l2) # [1, 2, 3, 4, 5, 6]
print(l1 * 3) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
循环列表,改变列表大小的问题
有列表l1, l1 = [11, 22, 33, 44, 55],请把索引为奇数对应的元素删除(不能一个一个删除,此l1只是举个例子,里面的元素不定)。
l1 = [11,22,33,44,55,66,77,88,99]
del l1[1::2]
print(l1)
l1 = [11,22,33,44,55,66,77,88,99]
for i in range(len(l1)-1,-1,-1):
if i %2 == 1:
l1.pop(i)
print(l1)
l1 = [11,22,33,44,55,66,77,88,99]
new_l1 = []
for i in range(len(l1)):
if i %2 == 0 :
new_l1.append(l1[i])
print(new_l1)
4、dict字典
#popitem 3.5版本之前,popitem为随机删除,3.6之后为删除最后一个,有返回值
dic = {'name': '太白', 'age': 18}
ret = dic.popitem()
print(ret,dic) # ('age', 18) {'name': '太白'}
# update
dic = {'name': '太白', 'age': 18}
dic.update(sex='男', height=175)
print(dic) # {'name': '太白', 'age': 18, 'sex': '男', 'height': 175}
dic = {'name': '太白', 'age': 18}
dic.update([(1, 'a'),(2, 'b'),(3, 'c'),(4, 'd')])
print(dic) # {'name': '太白', 'age': 18, 1: 'a', 2: 'b', 3: 'c', 4: 'd'}
dic1 = {"name":"jin","age":18,"sex":"male"}
dic2 = {"name":"alex","weight":75}
dic1.update(dic2)
print(dic1) # {'name': 'alex', 'age': 18, 'sex': 'male', 'weight': 75}
print(dic2) # {'name': 'alex', 'weight': 75}
fromkeys:创建一个字典:字典的所有键来自一个可迭代对象,字典的值使用同一个值。
dic = dict.fromkeys('abcd','太白')
print(dic) # {'a': '太白', 'b': '太白', 'c': '太白', 'd': '太白'}
dic = dict.fromkeys([1, 2, 3],'太白')
print(dic) # {1: '太白', 2: '太白', 3: '太白'}
# 这里有一个坑,就是如果通过fromkeys得到的字典的值为可变的数据类型,那么你的小心了。
dic = dict.fromkeys([1, 2, 3], [])
dic[1].append(666)
print(id(dic[1]),id(dic[2]),id(dic[3])) # {1: [666], 2: [666], 3: [666]}
print(dic) # {1: [666], 2: [666], 3: [666]}
循环字典,改变字典大小的问题
dic = {'k1':'太白','k2':'barry','k3': '白白', 'age': 18} 请将字典中所有键带k元素的键值对删除。
dic = {'k1':'太白','k2':'barry','k3': '白白', 'age': 18}
dic2= dic.keys()
dic3 = list(dic2)
for i in dic3:
if i.find('k') != -1:
del dic[i]
print(dic)
输出结果:
{'age': 18}
dic = {'k1': '太白', 'k2': 'barry', 'k3': '白白', 'age': 18}
for i in list(dic.keys()):
if 'k' in i:
del dic[i]
print(dic)
输出结果:
{'age': 18}
二. 数据类型间的转换问题
int bool str 三者转换
# int ---> bool
i = 100
print(bool(i)) # True # 非零即True
i1 = 0
print(bool(i1)) # False 零即False
# bool ---> int
t = True
print(int(t)) # 1 True --> 1
t = False
print(int(t)) # 0 False --> 0
# int ---> str
i1 = 100
print(str(i1)) # '100'
# str ---> int # 全部由数字组成的字符串才可以转化成数字
s1 = '90'
print(int(s1)) # 90
# str ---> bool
s1 = '太白'
s2 = ''
print(bool(s1)) # True 非空即True
print(bool(s2)) # False
# bool ---> str
t1 = True
print(str(True)) # 'True'
str list 两者转换
# str ---> list
s1 = 'alex 太白 武大'
print(s1.split()) # ['alex', '太白', '武大']
# list ---> str # 前提 list 里面所有的元素必须是字符串类型才可以
l1 = ['alex', '太白', '武大']
print(' '.join(l1)) # 'alex 太白 武大'
list set 两者转换
# list ---> set
s1 = [1, 2, 3]
print(set(s1))
# set ---> list
set1 = {1, 2, 3, 3,}
print(list(set1)) # [1, 2, 3]
str bytes 两者转换
# str ---> bytes
s1 = '太白'
print(s1.encode('utf-8')) # b'xe5xa4xaaxe7x99xbd'
# bytes ---> str
b = b'xe5xa4xaaxe7x99xbd'
print(b.decode('utf-8')) # '太白'
所有数据都可以转化成bool值
转化成bool值为False的数据类型有:
'', 0, (), {}, [], set(), None
三.基础数据类型的总结
按存储空间的占用分(从低到高)
- 数字
- 字符串
- 集合:无序,即无序存索引相关信息
- 元组:有序,需要存索引相关信息,不可变
- 列表:有序,需要存索引相关信息,可变,需要处理数据的增删改
- 字典:有序,需要存key与value映射的相关信息,可变,需要处理数据的增删改(3.6之后有序)
按存值个数区分
| 标量/原子类型 | 数字,字符串 |
|---|---|
| 容器类型 | 列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典 |
|---|---|
| 不可变 | 数字,字符串,元组,布尔值 |
按访问顺序区分
| 直接访问 | 数字 |
|---|---|
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) | 字典 |
四. 编码的进阶
编码即是密码本,编码记录的就是二进制与文字之间的对应关系,现存的编码本有:
ASCII码:包含英文字母,数字,特殊字符与01010101对应关系。
a 01000001 一个字符一个字节表示。
GBK:只包含本国文字(以及英文字母,数字,特殊字符)与0101010对应关系。
a 01000001 ascii码中的字符:一个字符一个字节表示。
中 01001001 01000010 中文:一个字符两个字节表示。
Unicode:包含全世界所有的文字与二进制0101001的对应关系。
a 01000001 01000010 01000011 00000001
b 01000001 01000010 01100011 00000001
中 01001001 01000010 01100011 00000001
UTF-8:包含全世界所有的文字与二进制0101001的对应关系(最少用8位一个字节表示一个字符)。
a 01000001 ascii码中的字符:一个字符一个字节表示。
To 01000001 01000010 (欧洲文字:葡萄牙,西班牙等)一个字符两个字节表示。
中 01001001 01000010 01100011 亚洲文字;一个字符三个字节表示。
1、不同的密码本之间不能互相识别
2、数据在内存中全是以Unicode编码的,但是当你的数据用于网络传输或者存储到硬盘中,必须以非Unicode编码(utf-8,gbk等等)
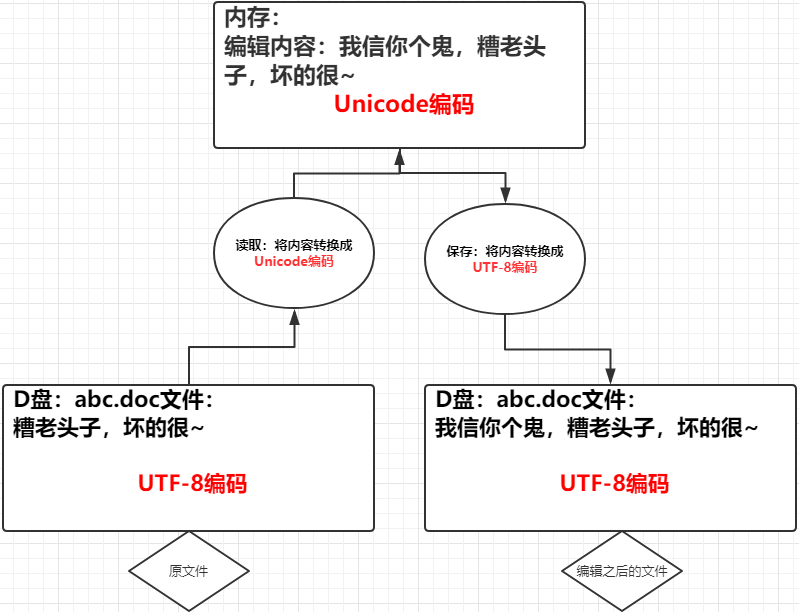
3、bytes数据类型
英文
- str :'hello'
内存中的编码方式:Unicode
表现形式:'hello'
- bytes:
内存中的编码方式:非Unicode
表现形式; b'hello'
b = b'hello' #如果在字符串前加b,它就变为一个bytes类型的数据
print(b,type(b)) #b'hello' <class 'bytes'>
b = b'hello'
print(b.upper(),type(b)) #b'HELLO' <class 'bytes'>
中文
- str :'中国'
内存中的编码方式:Unicode
表现形式:'中国'
- bytes:
内存中的编码方式:非Unicode
表现形式; b'xe4xb8xadxe5x9bxbd'
转换
- str -------> bytes
# encode称作编码:将 str 转化成 bytes类型
s1 = '中国'
b1 = s1.encode('utf-8') # 转化成utf-8的bytes类型
print(s1) # 中国
print(b1) # b'xe4xb8xadxe5x9bxbd'
s1 = '中国'
b1 = s1.encode('gbk') # 转化成gbk的bytes类型
print(s1) # 中国
print(b1) # b'xd6xd0xb9xfa'
- bytes ----->str
# decode称作解码, 将 bytes 转化成 str类型
b1 = b'xe4xb8xadxe5x9bxbd'
s1 = b1.decode('utf-8')
print(s1) # 中国
# decode称作解码, 将 bytes 转化成 str类型
b1 = b'xd6xd0xb9xfa'
s1 = b1.decode('gbk')
print(s1) # 中国
注:用什么编码(gbk,utf-8等)转过来的,必须要用相同的编码转回去。
- gbk ------>utf-8
gbk编码的bytes如何转化成utf-8编码的bytes
不同编码之间,不能直接互相识别。
Unicode是万码之源,先用gbk转为Unicode,转从Unicode转换为utf-8
b1 = b'xe4xb8xadxe5x9bxbd' # 这是utf-8编码bytes类型的中国
b2 = b'xd6xd0xb9xfa' # 这是gbk编码bytes类型的中国
b2 = b'xd6xd0xb9xfa' # 这是gbk编码bytes类型的中国
s = b2.decode('gbk')
print(s)
s1 = s.encode('utf-8')
print(s1)
输出结果:b'xe4xb8xadxe5x9bxbd'