1、树
树是一种很常见的分线性数据结构,公司的组织架构,行政区划结构等都是树形结构。树形结构里常见的有树和二叉树。
树的定义
树是n(n>=0)个结点的有限集。
在任意一棵非空树中:
(1)有且仅有一个特定的称为根(root)的结点
(2)当n>1时,其余结点可分为m(m>0)个互不相交的有限集,其中每一个集合本身又是一棵树,称为根的子树(递归的过程)

如上图所示:
图3-1是n=0的树;
图3-2是n=1只有一个根节点的树;
图3-3是一棵普通的树,B为根节点的树T1 = {B,E,F,J} 是A的子树,B为T1的根节点,同时也有自己的子树。
树的3种表示方法

如图所示的树有以下3中表示方法:
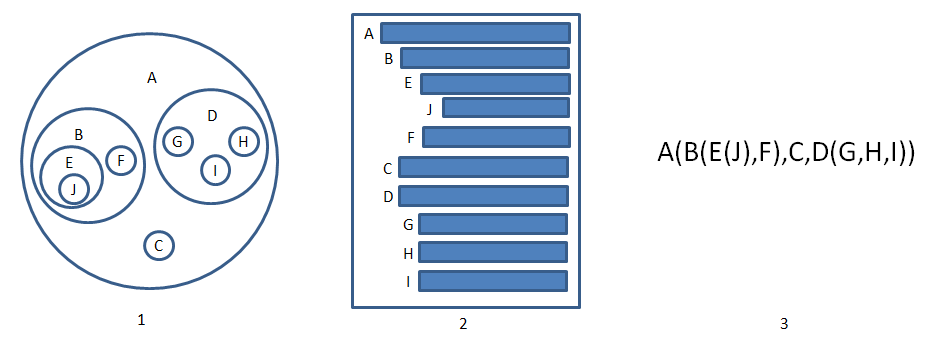
其中1是集合形式看起来很清晰;2是层级表示方式,类似书的目录;3是一种广义表的表示方法。
树的一些概念
结点:包含一个数据元素 及 若干指向其子树的分支。
例如结点B,包含了结点数据B 和 指向子树E和F的分支。
度:结点拥有的子树数称为结点的度。
例如:结点B包含了两个子树,度为2;结点D包含了3个子树,度为3.
叶子(终端结点):度为0的结点(没有子树的结点)
例如:J、F、C、G、H、I都是树的叶子。
分支结点(非终端结点):度不为0的结点(有子树的结点)。除了根节点外,分支结点也成为内部结点。
例如:A、B、E、D为分支结点;B、E、D为内部结点。
树的度:树内各个结点的度的最大值。
例如:A的度为3;B的度为2;D的度为3,其余结点度为0,所以树的度为3。
孩子:结点的子树称为结点的孩子,反过来,该节点称为孩子的双亲。
例如:结点A有B、C、D 3个孩子,A是B、C、D的双亲结点。
兄弟:同一双亲的孩子互为兄弟。
祖先:从根节点到某个结点(N)经历的所有结点称为该节点(N)的祖先;反之,以某结点(N)为根的任一结点都是该节点(N)的子孙。
堂兄弟:双亲结点在同一层的结点互为堂兄弟。
例如:E 和 G、H、I为堂兄弟。
结点的层次:结点的层次是从根节点开始,根为第一层,依次递增,所以上面树的结点A在第1层,J在第4层。如果结点在n层,其子树(如果有子树)就在第n+1层。
树的深度(高度):树种结点的最大层次称为树的深度(Depth)或高度。上面树的深度为4。
有序树:如果树中结点的各子树从左到右是有次序的(即不能互换),则次树是有序树;反之,则为无序树。
2、二叉树(Binary Tree)
二叉树是一种有限制的树,每个结点最多只有两颗子树(即二叉树中不存在度大于2的结点),并且二叉树的子树有左右之分,次序不能任意颠倒。
可以简单理解为:二叉树是一棵任意结点度不大于2的有序树。
二叉树有以下5中结构:

1:空二叉树;
2:只有根节点的二叉树;
3:右子树为空的二叉树;
4:左右子树均非空的二叉树;
5:左子树为空的二叉树
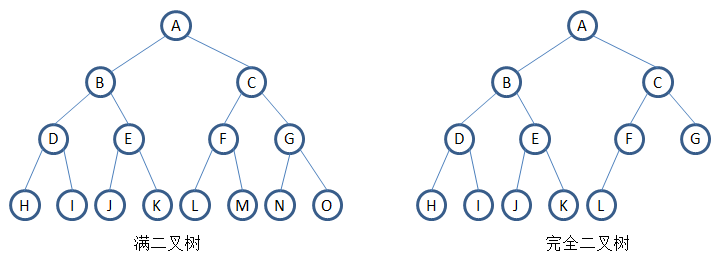
满二叉树:一棵深度为k且有2k - 1个结点的二叉树称为满二叉树。满二叉树上每一层的结点数都是最大节点数。
完全二叉树:深度为k的,有n个结点的二叉树,当且仅当其每一个节点都与深度为k的满二叉树中自上而下,从左往右编号完全相同的时候,就是完全二叉树。
注:完全二叉树是效率很高的数据结构,堆是一种完全二叉树或者近似完全二叉树,所以效率极高,像十分常用的排序算法、Dijkstra算法、Prim算法等都要用堆才能优化,二叉排序树的效率也要借助平衡性来提高,而平衡性基于完全二叉树。
二叉树的特性
(1)二叉树的第i层上至多有2i-1个结点(i >= 1);
(2)深度为k的二叉树至多有2k - 1个结点(k >= 1);
(3)对于任意一棵二叉树T,如果其终端节点数为n0,度为2的结点数为n2,则= n2 + 1
二叉树的存储结构
1、顺序存储结构
有以下3中二叉树:

按顺序存储的时候,用一组连续的存储空间从上至下,从左至右,将二叉树编号 i 的元素存储在对应1维数组的下标为 i-1 的位置,对应的存储结构为:

数组里元素为0的表示没有此结点,可以看出:顺序存储结构适合于完全二叉树,对于非完全二叉树比较浪费空间,图(3)只有四个结点对于最坏情况下,需要的空间却是最多的。
因此,在最坏情况下,一个深度为k且只有k个结点的单支树(树中不存在度为2的结点)需要的存储长度是2k - 1的一维数组。
2、链式存储结构
由二叉树的定义得知:二叉树的结点由一个数据元素 和 分别指向左子树、右子树的两个分支构成。有时候为了方便,也可以加个双亲结点的指针域,如下图所示:
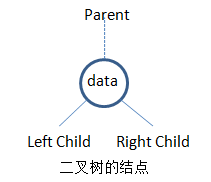
只含有左右子树的结点 和 含有左右子树和双亲指针的结点的数据结构:

只含有左右子树指针的链式结构称为二叉链表;含有左右子树指针和双亲结点指针的链式结构称为三叉链表。
如下2种结构的二叉树:
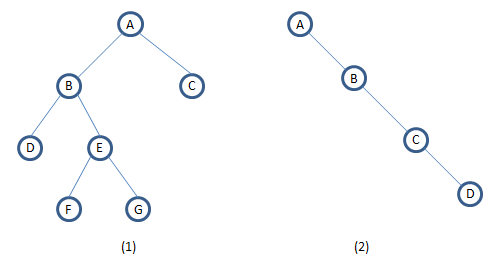
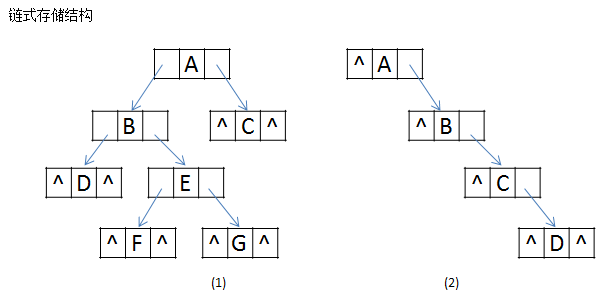
由存储结构可以得出:有n个结点的二叉链表中有n+1个空链域。
二叉链表和三叉链表比较
(1)二叉链表少存储了个parent指针,所以更节省内存。
(2)在二叉链表中查找某个元素的双亲结点需要从根节点遍历查询,而在三叉链表中可以直接通过parent指针拿到。
二叉链表和三叉链表各有优缺点,具体使用哪种存储结构需要根据实际情况来决定。
遍历二叉树
二叉树不像线性表结构只需要从前向后遍历即可访问每个元素,二叉树每个结点都可能有两个分支,所以遍历方式肯定不像线性表那么简单。二叉树是由若干个结点递归构成的,每个结点又由根节点、左子树和右子树3个基本单元组成,因此遍历二叉树就是依次遍历这三个部分,每个结点都按某种方法来遍历,遍历完所有结点即完成了对二叉树的遍历过程。假如限定先左后右,假如一棵二叉树不为空,则有以下3种方式:
先序遍历
(1)访问根节点;
(2)先序遍历左子树;
(3)先序遍历右子树。
中序遍历
(1)中序遍历左子树;
(2)访问根节点;
(3)中序遍历右子树。
后序遍历
(1)后序遍历左子树;
(2)后序遍历右子树;
(3)访问根节点。
按层次遍历
从上到下,从左往右,逐层遍历。
对于二叉树:
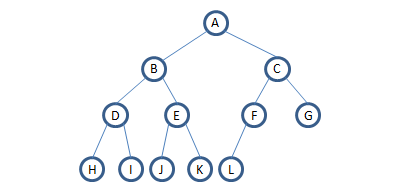
先序遍历(中左右):A->B->D->H->I->E->J->k->C->F->L->G
中序遍历(左中右):H->D->I->B->J->E->K->A->L->F->C->G
后续遍历(左右中):H->I->D->J->K->E->B->L->F->G->C->A按层遍历(上->下,左->右):A->B->C->D->E->F->G->H->I->J->K->L
用递归来实现前序、中序、后续遍历:


//前序 private void prePrint(Node node ) { if (node == null) return; System.out.print(node.getVal()); prePrint(node.getLeftChild()); prePrint(node.getRightChild()); } //中序 private void middlePrint(Node node) { if (node == null) return; middlePrint(node.getLeftChild()); System.out.print(node.getVal() + "->"); middlePrint(node.getRightChild()); } //后续 private void sufPrint(Node node) { if (node == null) return; sufPrint(node.getLeftChild()); sufPrint(node.getRightChild()); System.out.println(node.getVal()); }
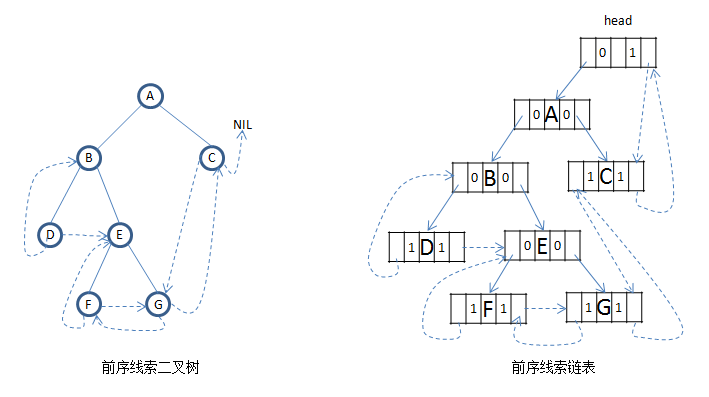
线索二叉树
遍历二叉树是以一定规则将二叉树中结点排列成一个线性序列,不同方法会得到不同序列方式,如先序序列、中序序列和后序序列。这实际上是对一个非线性结构进行线性化的操作,使每个节点(除了第一个和最后一个外)在这些线性序列中有且仅有一个直接前驱和直接后继。但是,当以二叉链表作为存储结构时候,只能找到左右孩子结点信息,不能直接得到结点在任一序列中的前驱和后继信息,这种信息只有在遍历的动态过程中才能得到。如何保持这种线性关系呢?
(1)如果在每个结点上增加两个指针域prefix 和 suffix,分别表示结点在任一次序遍历时候的前驱和后继,虽然可用实现,但是增加的两个指针域比较耗费空间;
(2)前面我们知道,在有n个结点的二叉链表中必定有n+1个空链域,如果用空链域来存储结点的前驱和后继就可以充分利用内存空间,所以只需要新增两个标识位lTag和rTag,用来区分什么时候指向孩子节点,什么时候指向前驱(后继),标识位是布尔类型的,比(1)里的指针更省空间。
如果结点有左子树,则其lchild指向其左孩子结点,否则让lchild域指向其前驱;若结点有右子树,则其rchild指向其右孩子,否则让rchild指向其后继。新增两个标识位,结点结构为:

其中:
lTag:0 lchild域指示结点的左孩子
1 lchild域指示结点的前驱
rTag:0 rchild域指示结点的右孩子
1 rchild域指示结点的后继
以这种结点结构构成的二叉链表作为二叉树的存储结构叫做线索链表,其中指向结点前驱和后继的指针叫做线索,加上线索的二叉树叫做线索二叉树,对二叉树以某种次序遍历使其变为线索二叉树的过程叫做线索化。
因为线索化的过程是将二叉链表中的空指针改为指向前驱或后继的线索,而且前驱或后继信息是在遍历过程中才有的,所以线索化即为改变二叉链表空指针的过程。
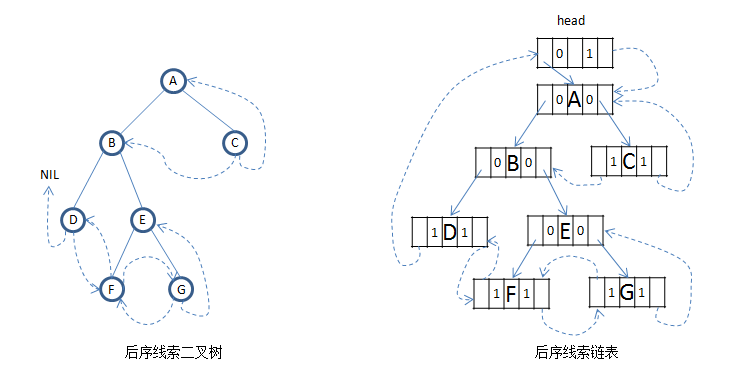
下面分别是前中后序对于的线索二叉树和线索二叉链表,如果给二叉链表增加一个head指针,那么在给定任意一个结点都可以遍历得到整棵树:

3、树和森林
树的3中常用链表结构
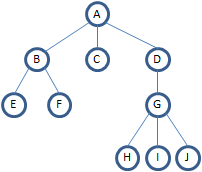
如上图所示的二叉树,有以下3中表示方法
图(a)双亲表示法
假设以一组连续空间存储树的结点,存储结点的同时附加存储指示双亲的结点在链表里的位置,有图可知,方便找每个结点的双亲,不太方便找孩子结点(需要遍历)。
图(b)、图(c)孩子表示法
图(b)由每个结点分别指向自己的子树,构成多重链表结构;图(c)在图(b)基础上增加了双亲节点。
图(d)孩子兄弟表示法
又称为二叉树表示法或二叉链表表示法。链表里每个结点的两个指针分别指向该节点的第一个孩子结点和下一个兄弟结点。
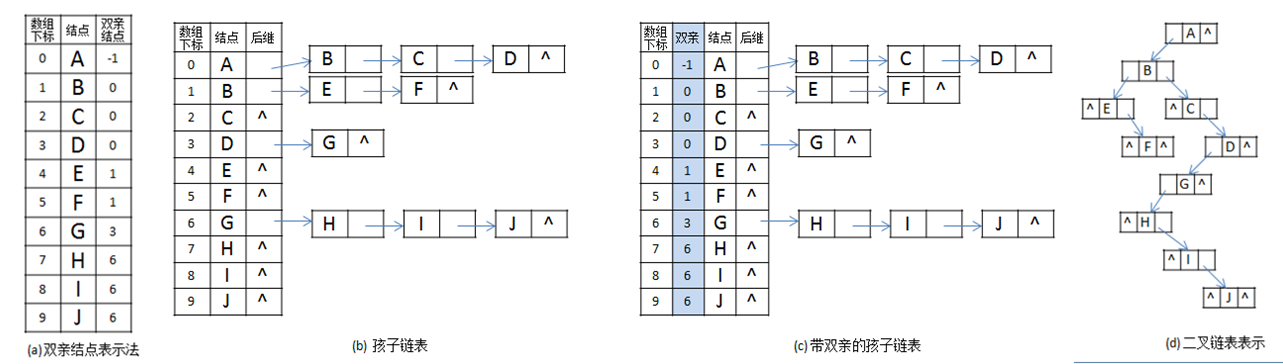
森林和二叉树的转换
前面知道二叉树可以用二叉链表表示,上小结提到树可以用二叉链表表示,所以就可以用二叉链表作为存储媒介将树与二叉树对应起来,也就是说对于一棵给定的树可以找到唯一的一棵二叉树与之对应,如下图所示:
由上节树的二叉链表表示法可以知道:任何一棵树对应的二叉树,其右子树肯定为空(由于根节点肯定没有兄弟结点)。
如果把第二棵树根节点看作第一棵树根节点的兄弟,那么第二颗树根节点就是第一棵树的右子树,以此类推可以将若干棵树构成一棵二叉树(即森林与二叉树对应关系),如下图所示:

树的遍历
由树的结构定义可以引出两种次序遍历方法:
先根(次序)遍历树:先访问树的根节点,然后依次先根遍历根的每颗子树
后根(次序)遍历树:先依次后根遍历每颗子树,然后访问根节点

对这棵树进行先根遍历:A B E F C D G
对这棵树进行后根遍历:E F B C G D A
森林的遍历
按照森林和树的定义,可以推出森林的两种遍历方法
先序遍历森林
如果森林非空,可以按下面规则遍历:
(1)访问森林中第一棵树的根节点
(2)先序遍历第一棵树中根节点的子树森林
(3)先序遍历除去第一棵树之后的树构成的森林
中序遍历森林
如果森林非空,可以按下面规则遍历:
(1)中序遍历森林中第一棵树的根节点的子树森林
(2)访问第一棵树的根节点
(3)中序遍历除去第一棵树之后的树构成的森林
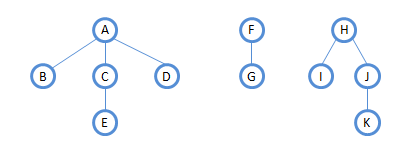
对上图森林进行遍历:
先序:A B C E D F G H I J K
中序:B E C D A G F I K J H
由森林转化成二叉树得知,对应的二叉树为
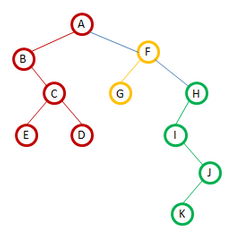
所以森林的先序和中序也就是转化成二叉树后,二叉树的先序和中序遍历。