简单介绍
Zookeeper是一个开源的分布式应用程序协调服务器,主要功能包括配置维护,域名服务,分布式同步,集群管理等
主要功能简介
一、配置维护
分布式系统中,很多服务都是部署在集群中的,就是多态服务器中部署着完全相同的应用,他们的配置文件也是必须相同的,下面有一个场景,就是当我们想要修改一个配置文件时,如果我们通过手动修改参与集群的所有机器上的应用配置文件时不仅麻烦而且极其容易出错,Zookeeper对配置文件的维护采用的事"发布 / 订阅模型",发布者将修改号的集群的配置文件发送到Zookeeper服务器的文件系统中,那么订阅者马上就会收到通知,并主动去同步Zookeeper里的配置文件,Zookeeper具有同步操作的原值性,确保参与集群的机器说读取的配置文件都能被正确的更新
二、域名服务
现在的项目都是包含多个工程这种款式的,而有些工程就是专门为其他工程提供服务的,一个项目中就会存在很多这种想其他工程提供服务的工程,而一个服务又可能存在多个提供者,服务的消费者消费起来就比较复杂,Zookeeper为每一个服务起了一个名称,将这些名称和对应提供服务的主机地址注册到Zookeeper中,形成一个服务映射表,服务消费者通过服务名称即可消费服务,服务的减少,添加,变更,只需修改Zookeeper中的服务映射表即可
阿里的Dubbo就是使用的Zookeeper作为服务域名服务器的
三、分布式同步
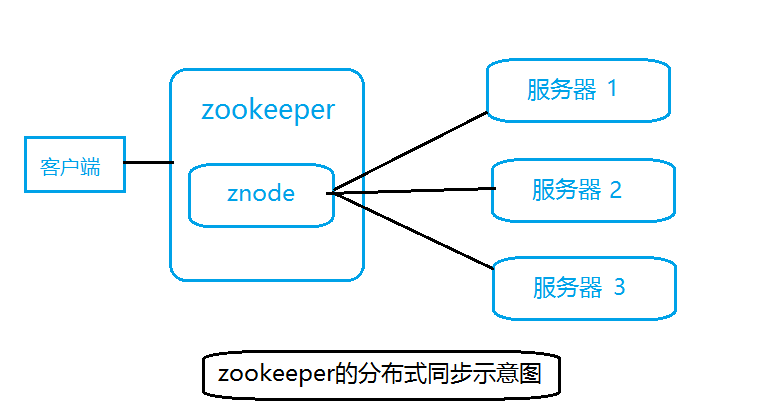
在分布式系统中,很多运算过程都是有分布式集群中若干服务器共同计算完成的,并且他们之间的运算还具有逻辑上的先后顺序,Zookeeper就可以协调这些服务间运算的过程,让这些服务都同时监听Zookeeper上的同一个znode,一旦起重工一个服务器的znode发生了改变,另一个相应服务器就能够收到通知,并作出相应处理
比如上面这张逻辑图,zookeeper可以协调他们三个的先后顺序
四、集群管理
集群中最麻烦即使节点故障管理,Zookeeper会让集群选出一个节点作为Master,监控所有的节点的健康状况,一个有节点故障,就会通知其他的节点,使集群中的其他节点对于任务的分配作出相应的调整,Zookeeper除了发现故障外,还具有对故障进行甄别的功能,如果故障节点是可以修复的,Zookeeper可以修复它,如果不能修复则会告诉系统管理元错误的原因让管理员定位故障点,
至于Master故障的话,Zookeeper内有选举算法,选取新的节点担任Master的职责对集群进行管理
Zookeeper的一致性要求
顺序一致性:
-
从同一个客户端发起的n多个事务请求,最终将会严格按照其发起请求的顺序被应用到Zookeeper中
原子性:
-
所有事务请求的结果在集群中所有的机器上的应用情况是一样的,也就是说要么整个集群中所有主机都成功应用某一个事务,要么就没有应用,不会出现集群中个别主机应用了该事物,个别主机没有应用的情况
单一视图:
-
无论客户端连接的是那一个Zookeeper服务器,其看到的服务端数据模型都是一致的
可靠性:
-
一旦一个服务端成功的应用了一个事务,并完成对客户端的响应,那么该事务所引起的服务端状态变更将会被一直保留下来,除非有另一个事务又对其做了变更
实时性:
-
这个实时性,指的是Zookeeper只能保证在一定的时间段内,客服端最终一定能够从服务器端读取到最新的数据状态,而不是一旦被应用,客服端就能够立即从服务端读取到这个事务变更后的最新数据状态
Zookeeper中的几个重要概念
Session
Session是指客户端会话,Zookeeper对外的服务端口默认为2181,客户端启动时,首先会与zk服务器建立一个TCP长连接,从第一次连接建立开始,客户端会话的生命周期也开始了,通过这个长连接,客户端能够通过心跳检测保持与服务器的有效回话,也能够想zk服务器发起请求并接受响应,同时还能通过该连接接受来自服务器的Watcher时间通知
Znode
zk的文件系统采用属性层次化的目录结构,每个目录都在zk中都叫做一个znode,每个znode都拥有一个唯一的路径标识,Znode可以包含数据和子Znode(零时节点不能有子Znode),Znode中的数据可以有多个版本,所以查询某路径下的数据需要带上版本号,客户端应用可以在Znode上设置监视器(Watcher)


Watcher机制
zk通过Watcher机制实现发布订阅模式,zk提供了分布式数据的发布订阅功能,一个发布者能够让多个订阅者同时监听某一个主题对象,当这个主题对象状态发生改变是,会通知所有订阅者,是他们能够作出相应的处理,ZK允许哭护短想服务器注册一个Watcher监听,当服务端的一些指定事件触发这个Watcher时,那么就会向指定的客户端发送一个事件通知,而这个事件通知则是通过TCP长连接的Session完成的
ACL:访问控制列表
ACL全称为Access Control List,用于控制资源的访问权限,是ZK数据安全的保障,ZK利用ACL策略控制Znode节点的访问权限,如果节点创建,节点数据读写,节点删除,读取子节点列表,设置节点权限等
在传统的文件系统中,ACL分为两个维度,组与权限,一个组可以包含多个权限,一个文件或者目录拥有了某个租的权限即又有了组里所有的权限,文件或子目录默认会继承父目录的ACL
在ZK中,Znode的ACL是没有继承关系的,每一个Znode的权限都是独立控制的,只有哭护短满足Znode设置的权限要求时,才能完成相应的操作,ZK的ACL分为三个维度,分别为: 授权策略scheme、用户id、用户权限permission。