Spark2.1. http://dblab.xmu.edu.cn/blog/1689-2/
0+入门:Spark的安装和使用(Python版)
Spark2.1.0+入门:第一个Spark应用程序:WordCount(Python版)
http://dblab.xmu.edu.cn/blog/1692-2/#more-1692
应用:
启动
cd /usr/local/spark ./bin/pyspark
RDD
分布式对象集合,一个只读的分区记录集合。一种数据结构(相当于int、double等)
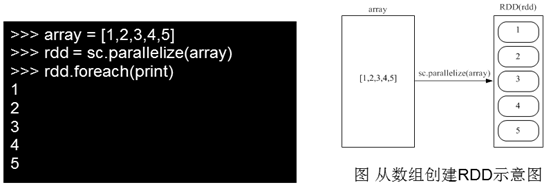
1.RDD创建
(1)从本地文件系统中加载数据创建RDD
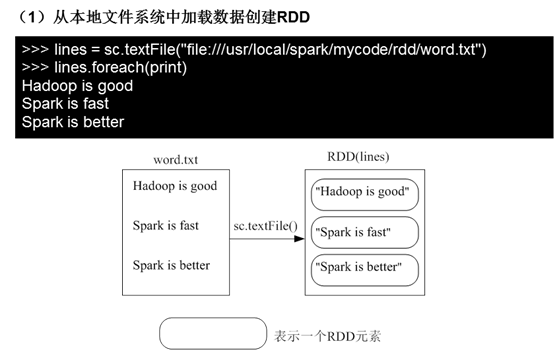
(2)从分布式文件系统HDFS中加载数据

(3)从其他RDD创建。
parallelize:https://blog.csdn.net/wyqwilliam/article/details/84330408
2.RDD操作
Spark API :https://www.csdn.net/gather_26/MtTaYg4sNDQ5MC1ibG9n.html
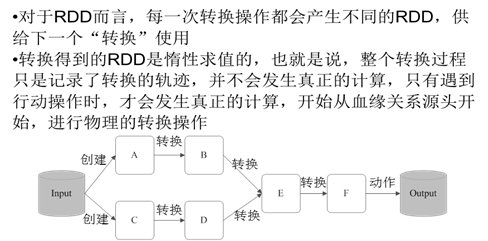
2.1转换操作

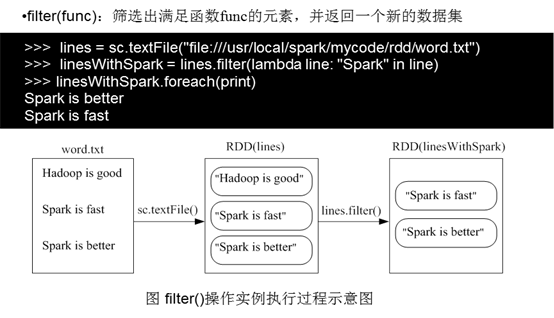
1)fileter(func)
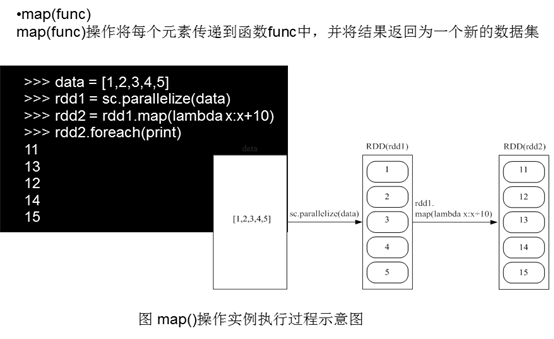
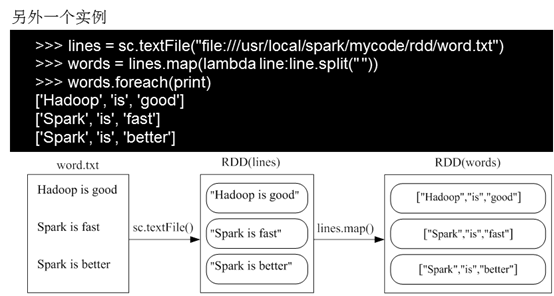
2)map(func)
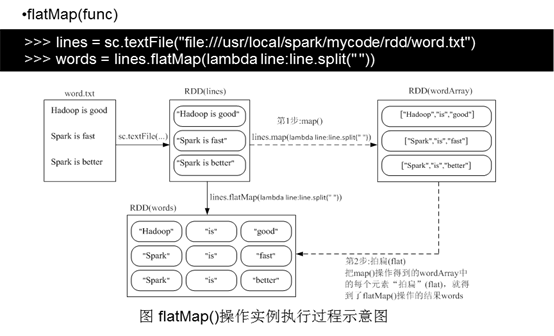
3)flatMap(func)
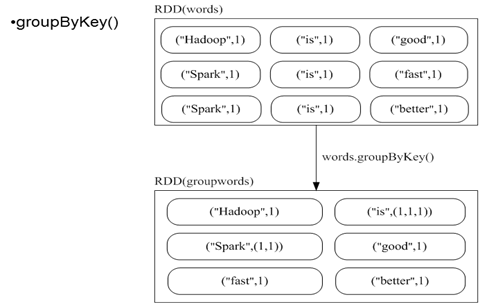
4)groupByKey()

5)reduceBykey(func)

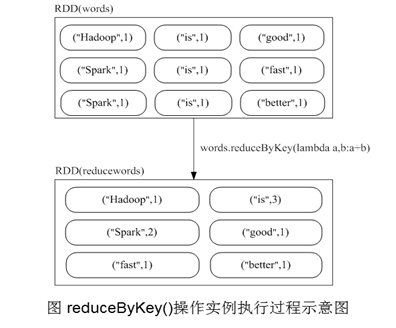
groupByKey也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作
reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义

6)keys()

7)values()

8)mapValues(func)

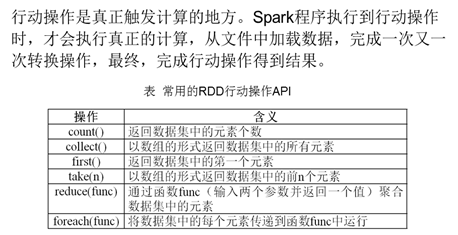
4.2行动操作




4.3惰性机制

持久化




分区


练习:
1给定一组键值对("spark",2),("hadoop",6),("hadoop",4),("spark",6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
2 有两个文件,file1.txt,file2.txt,字段含义如下orderid,userid,payment,productid。求top 5个payment值。
file1.txt
1,1768,50,155 2,1218, 600,211 3,2239,788,242 4,3101,28,599 5,4899,290,129 6,3110,54,1201 7,4436,259,877 8,2369,7890,27
file2.txt
100,4287,226,233 101,6562,489,124 102,1124,33,17 103,3267,159,179 104,4569,57,125 105,1438,37,116