sequence to sequence模型是一类End-to-End的算法框架,也就是从序列到序列的转换模型框架,应用在机器翻译,自动应答等场景。
Seq2Seq一般是通过Encoder-Decoder(编码-解码)框架实现,Encoder和Decoder部分可以是任意的文字,语音,图像,视频数据,模型可以采用CNN、RNN、LSTM、GRU、BLSTM等等。所以基于Encoder-Decoder,我们可以设计出各种各样的应用算法。
与Seq2Seq框架相对的还有一个CTC,CTC主要是利用序列局部的信息,查找与序列相对的另外一个具有一对一对应关系(强相关,具有唯一性)的序列,比较适用于语音识别、OCR等场景。
而Seq2Seq更善于利用更长范围的序列全局的信息,并且综合序列上下文判断,推断出与序列相对应的另一种表述序列(非强相关,不具有唯一性),比较适用于机器翻译、文章主旨提取等场景。
从范围上来说,CTC是狭义的,Seq2Seq是广义的,从结果上来说,CTC是强制的一对一对应关系,Seq2Seq是具有弱约束的多对多对应关系。
经典的Encoder-Decoder框架:
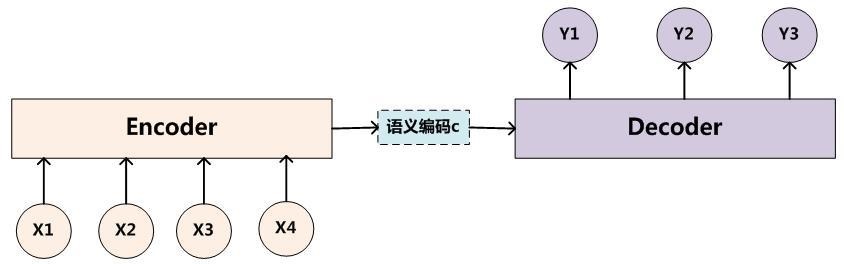
左侧Encoder编码将输入序列转化成一个固定长度的向量编码,右侧Decoder解码将之前生成的固定向量再转化成输出序列,编解码部分可以采用CNN、RNN、LSTM、GRU、BLSTM等实现。
Encoder-Decoder模型可以预测任意的序列对应关系,但同时也有一个很大的问题就是从编码到解码的准确率很大程度上依赖于一个固定长度的语义向量c,输入序列到语义向量c的压缩过程中存在信息的丢失,并且在稍微长一点的序列上,前边的输入信息很容易被后边的输入信息覆盖,也就是说编码后的语义向量c已经存在偏差了,解码准确率自然会受到影响。其次在解码的时候,每个时刻的输出在解码过程中用到的上下文向量是相同的,没有做区分,也就是说预测结果中每一个词的的时候所使用的预测向量都是相同的, 这也会给解码带来问题。
为了解决这样的问题,在Seq2Seq模型加入了注意力机制(attention mechanism),在预测每个时刻的输出时用到的上下文是跟当前输出有关系的上下文,而不是统一只用相同的一个。这样在预测结果中的每个词汇的时候,每个语义向量c中的元素具有不同的权重,可以更有针对性的预测结果。
图示如下,增加了一个“注意力范围”,表示接下来输出词时候要重点关注输入序列中的哪些部分,然后根据关注的区域来产生下一个输出:
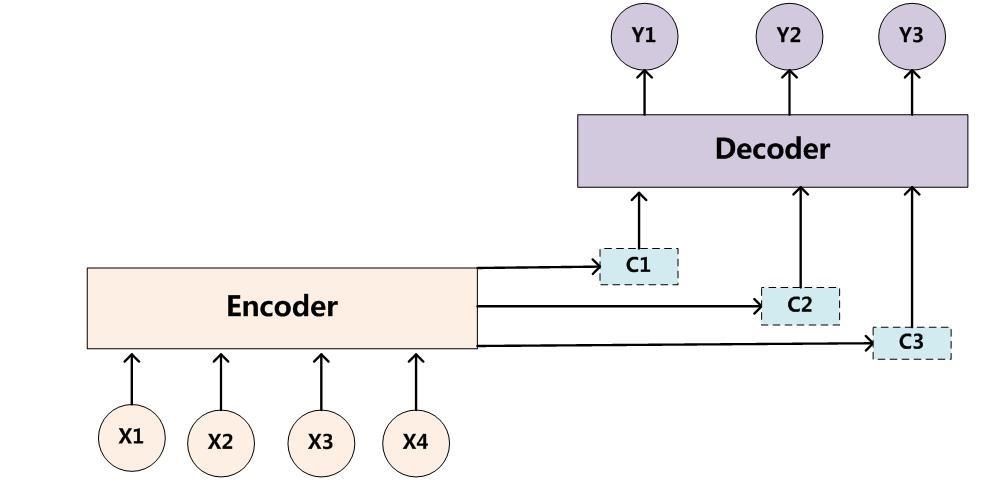
attention模型最大的不同在于Encoder将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行输出预测,这样,在产生每一个输出的时候,都能找到当前输入对应的应该重点关注的序列信息,也就是说,每一个输出单词在计算的时候,参考的语义编码向量c都是不一样的,所以说它们的注意力焦点是不一样的。