tesseract是一个开源的OCR引擎,最初是由惠普公司开发用来作为其平板扫描仪的OCR引擎,2005年惠普将其开源出来,之后google接手负责维护。目前稳定的版本是3.0。4.0版本加入了基于LSTM的神经网络技术,中文字符识别准确率有所提高。
ubuntu下tesseract 4.0安装:
终端输入以下命令:
sudo add-apt-repository ppa:alex-p/tesseract-ocr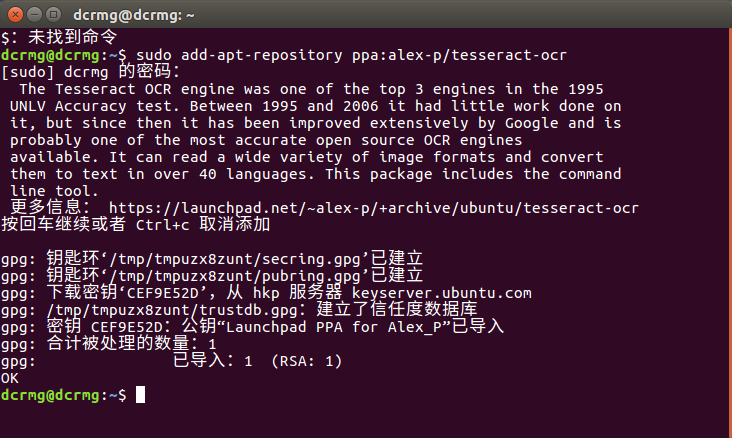
sudo apt-get update 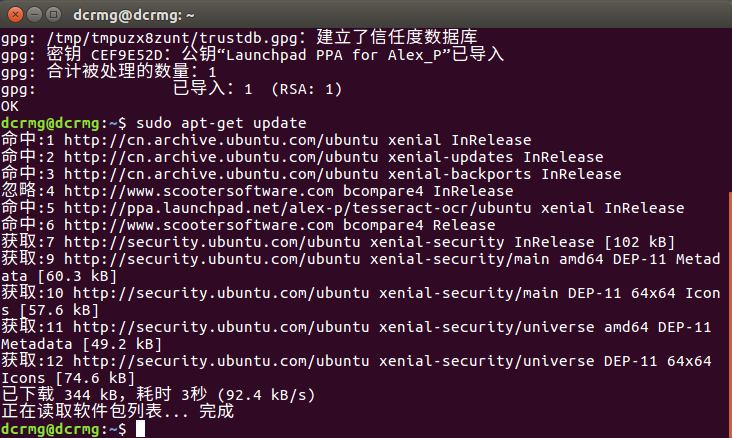
sudo apt-get install tesseract-ocr 测试安装是否成功,同时检查版本:
tesseract --version 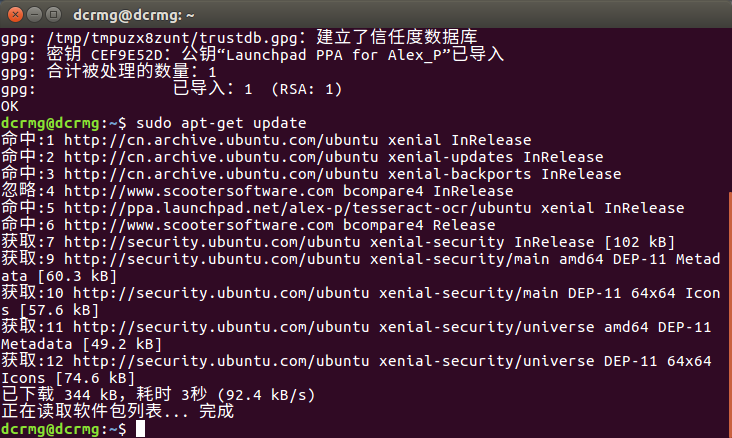
字库下载
tesseract支持60多种语言的识别不同,使用之前需要先下载对应语言的字库,下载地址:https://github.com/tesseract-ocr/tessdata
下载完成之后把.traineddata字库文件放到tessdata目录下,默认路径是/usr/share/tesseract-ocr /4.0/tessdata
中文OCR识别测试
在终端中使用tesseract格式:
tesseract xx.jpg result --psm 7执行之后生成结果记录在result里,--psm 7 指令表示内容是一行文本
更多tesseract使用指令可以查看help
tesseract --help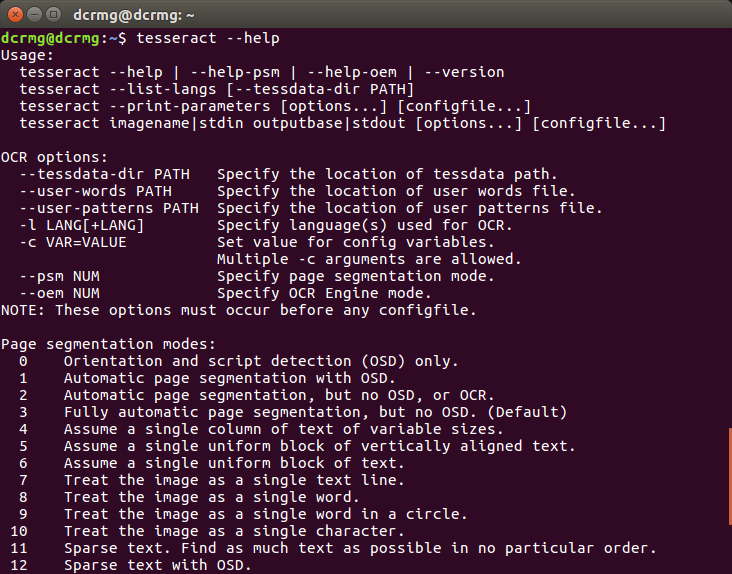
查看已安装字库
tesseract --list-langs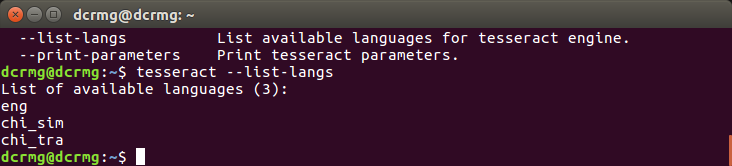
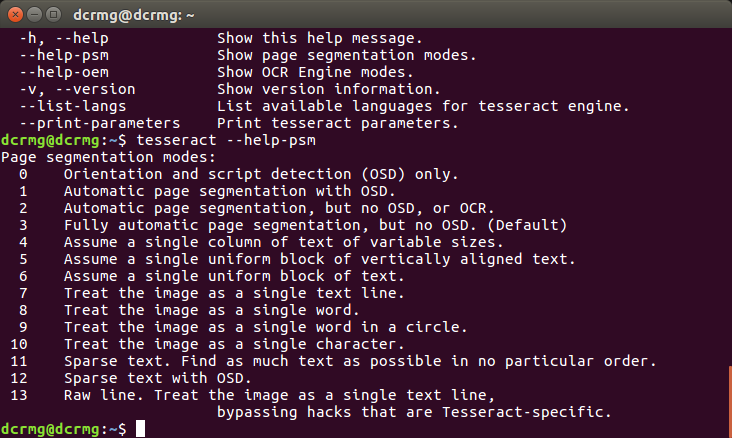
--psm命令
psm命令指明文本的模式,默认为3:
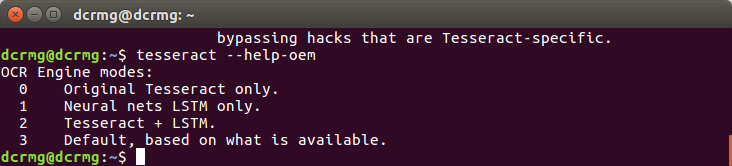
--oem命令
定义OCR引擎的模式: