神经网络中数据从数据层到最后输出层的流动过程其实就是数据从一种形态到另一种形态,从一个维度到另一个维度的变换过程,例如在Minst数据集训练中,就是把28*28维的图像数据经过变换,映射成0~9之间的一个数字。完成这种数据变换的一个重要工具就是激活函数。
一个典型的人工神经元的模型可以用下图表述:
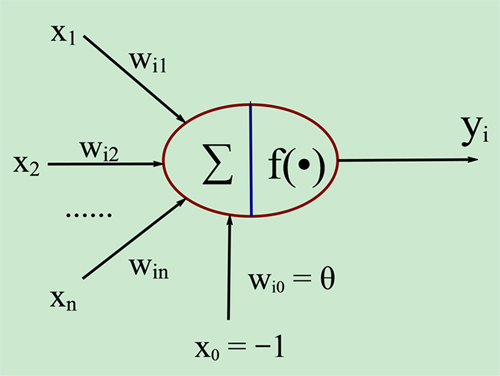
- 图中X1~Xn是神经元的输入信号;
- θ表示一个阈值,或称为偏置(bias),偏置的设置是为了正确分类样本,是模型中一个重要的参数;
- ∑表示各输入信号X乘以权重后的累加和,是一个线性变换;
- f(*)称为激活函数或激励函数(Activation Function),激活函数的主要作用是完成数据的非线性变换,解决线性模型的表达、分类能力不足的问题;
常见的激活函数
1. Sigmoid
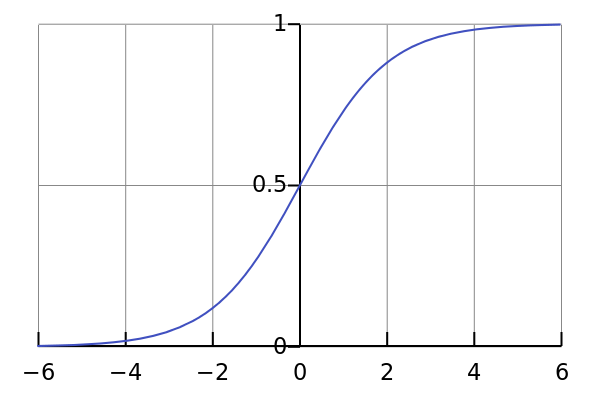
Sigmoid函数的特点是会把输出限定在0~1之间,如果是非常大的负数,输出就是0,如果是非常大的正数,输出就是1,这样使得数据在传递过程中不容易发散。
Sigmod有两个主要缺点,一是Sigmoid容易过饱和,丢失梯度。从Sigmoid的示意图上可以看到,神经元的活跃度在0和1处饱和,梯度接近于0,这样在反向传播时,很容易出现梯度消失的情况,导致训练无法完整;二是Sigmoid的输出均值不是0,基于这两个缺点,SIgmoid使用越来越少了。
2. tanh
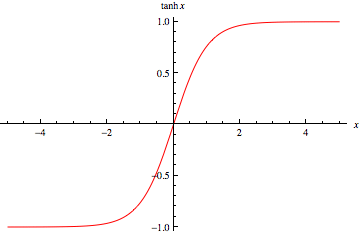
tanh是Sigmoid函数的变形,tanh的均值是0,在实际应用中有比Sigmoid更好的效果。
3. ReLU
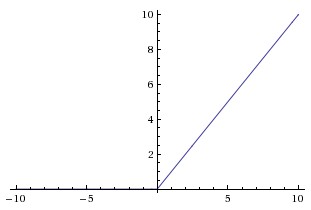
ReLU是近来比较流行的激活函数,当输入信号小于0时,输出为0;当输入信号大于0时,输出等于输入。
ReLU的优点:
1. ReLU是部分线性的,并且不会出现过饱和的现象,使用ReLU得到的随机梯度下降法(SGD)的收敛速度比Sigmodi和tanh都快。
2. ReLU只需要一个阈值就可以得到激活值,不需要像Sigmoid一样需要复杂的指数运算。
ReLU的缺点:
在训练的过程中,ReLU神经元比价脆弱容易失去作用。例如当ReLU神经元接收到一个非常大的的梯度数据流之后,这个神经元有可能再也不会对任何输入的数据有反映了,所以在训练的时候要设置一个较小的合适的学习率参数。
4. Leaky-ReLU
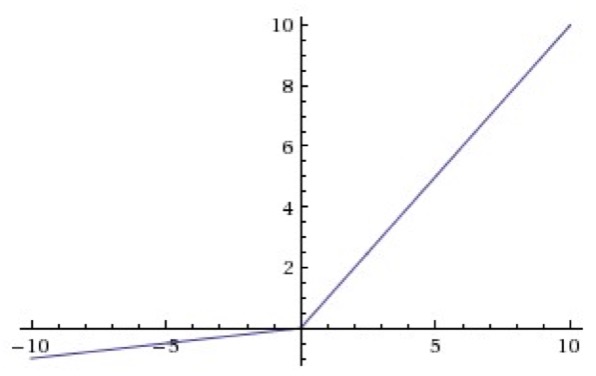
相比ReLU,Leaky-ReLU在输入为负数时引入了一个很小的常数,如0.01,这个小的常数修正了数据分布,保留了一些负轴的值,在Leaky-ReLU中,这个常数通常需要通过先验知识手动赋值。
5. Maxout
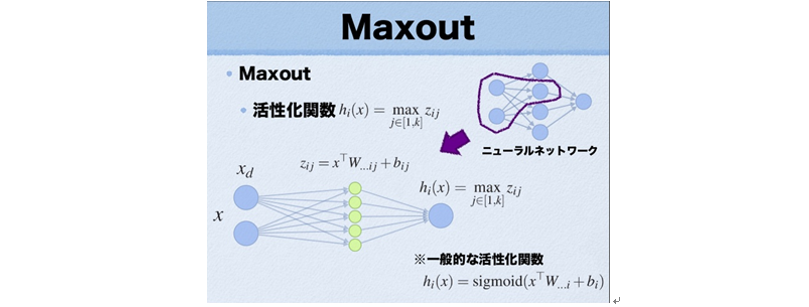
Maxout是在2013年才提出的,是一种激发函数形式,一般情况下如果采用Sigmoid函数的话,在前向传播过程中,隐含层节点的输出表达式为:

其中W一般是二维的,这里表示取出的是第i列,下标i前的省略号表示对应第i列中的所有行。而在Maxout激发函数中,在每一个隐含层和输入层之间又隐式的添加了一个“隐含层”,这个“隐隐含层”的激活函数是按常规的Sigmoid函数来计算的,而Maxout神经元的激活函数是取得所有这些“隐隐含层”中的最大值,如上图所示。
Maxout的激活函数表示为:
f(x)=max(wT1x+b1,wT2x+
b2)
可以看到,ReLU 和 Leaky ReLU 都是它的一个变形(比如,w1,b1=0 的时候,就是 ReLU)。
Maxout的拟合能力是非常强的,它可以拟合任意的的凸函数,优点是计算简单,不会过饱和,同时又没有ReLU的缺点(容易死掉),但Maxout的缺点是过程参数相当于多了一倍。
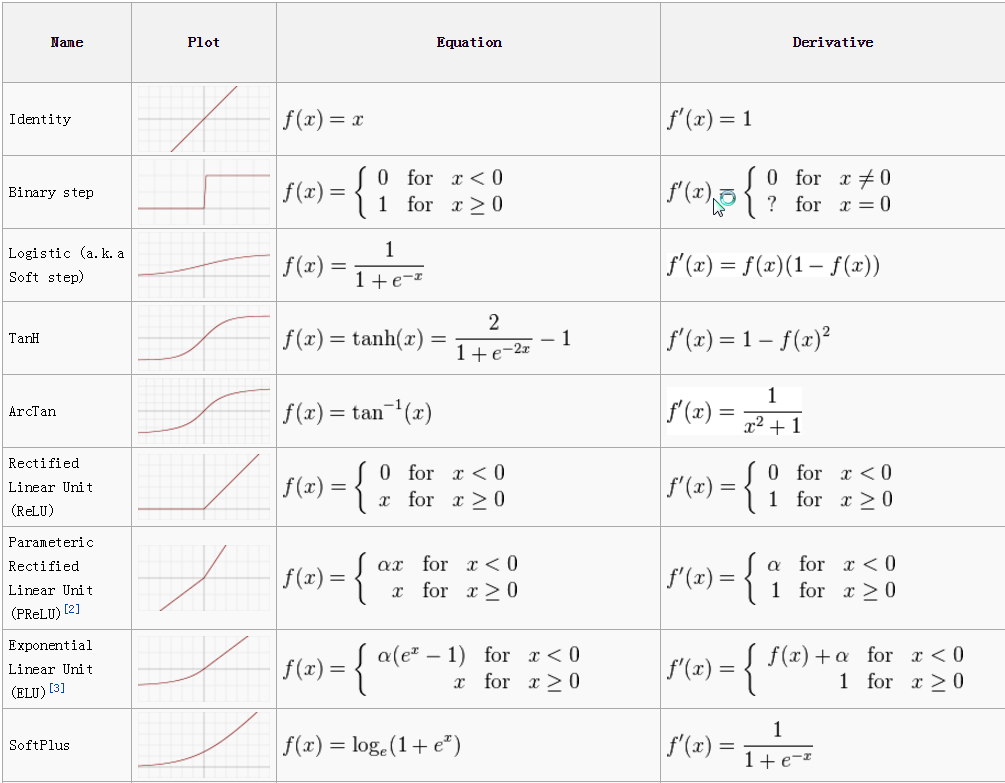
其他一些激活函数列表:
假设神经元的输入是一个4维的向量 X,其中的值为0或者1,并且只取4中样本:
- x1=[1,0,0,0]
- x2=[0,1,0,0]
- x3=[0,0,1,0]
- x4=[0,0,0,1]
对这一组样本,采用一个很小的随机数来模拟生成20000个样本,同时,将神经元的4个输出值映射到[0,1],即4个分类分别是[0.25,0.5,0.75,1]。
代码实现如下:
#include <iostream>
#include <vector>
using namespace std;
vector<vector<double>> inputData;
vector<double> weight;
double actual_output; //网络的实际输出
vector<double> input;
//生成numofSample个样本,一共分为numofLable类,每个样本的标签是当前样本的下标i%numofLable
void getSamplesData(int numofSamples, int numofLable)
{
const int iterations = numofSamples; // 样本数量
for (int i = 0; i < iterations; i++)
{
int index = i % numofLable;
vector<double> dvect(numofLable, 0);
dvect[index] = 1;
for (size_t i = 0; i != dvect.size(); i++)
{
dvect[i] += (5e-3*rand() / RAND_MAX - 2.5e-3);
}
inputData.push_back(dvect);
}
}
//初始化初始权重,包括4个节点和1个偏置,随机设置为0~0.05之间的一个值
void intialWeight()
{
cout << "初始化权重为:" << endl;
// 4个连结和一个偏置w0
for (int i = 0; i != 5; i++)
{
weight.push_back(0.05*rand() / RAND_MAX);
cout << weight[i] << endl;
}
}
//前向计算,输入时数据层的4维的训练数据,actual_output是网络当前的输出
void cmtForward(const vector<double>& inVect)
{
double dsum = weight[4];//先把偏置加上
for (size_t i = 0; i != inVect.size(); i++)
{
dsum += (inVect[i] * weight[i]);
}
actual_output = 1 / (1 + exp(-1 * dsum)); // S函数的非线性变换
//actual_output = 2 * (1 / (1 + exp(-2 * dsum))) - 1; //T函数的非线性变换
//dsum > 0 ? actual_output = dsum : actual_output = 0; //R函数的非线性变换
}
//权重调整,相当于后向计算,输入时训练数据和期望的输出
void updataWeight(const vector<double>& inVect, const double true_output)
{
double learnRate = 0.05; // 权重更新参数
for (size_t i = 0; i != weight.size() - 1; i++)
{
weight[i] += (learnRate*(true_output - actual_output)*actual_output*(1 - actual_output)*inVect[i]);
}
// w0单独计算
weight[4] += (learnRate*(true_output - actual_output)*actual_output*(1 - actual_output) * 1);
}
void main()
{
getSamplesData(20000, 4); //生成20000个数据,分为4类
intialWeight(); //初始化权重,随机生成5个0~0.05之间的数值
//执行20000次迭代
for (int i = 0; i < 20000; i++)
{
input = inputData[i];
double lable = (double)(i % 4) / 4 + 0.25; //数据标签转换到0~1
cmtForward(input); //前向传播计算
updataWeight(input, lable); //权重调整
if (i % 111 == 0)
{
cout << "当前执行第 " << i << " 次迭代" << endl;
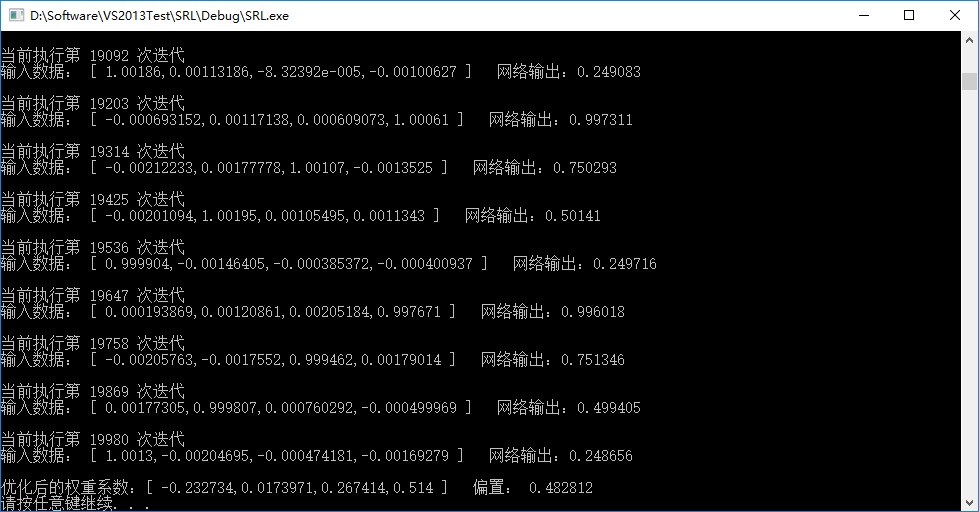
cout << "输入数据: [ " << input[0] << "," << input[1] << "," << input[2] << "," << input[3]
<< " ]" << " " << "网络输出:" << actual_output << endl << endl;
}
}
cout << "优化后的权重系数:[ " << weight[0] << "," << weight[1] << "," << weight[2] << "," <<
weight[3] << " ]" << " 偏置: " << weight[4] << endl;
system("pause");
}在前向计算cmtForward函数中,使用S函数,注释掉的分别是T函数和R函数。
S函数的迭代实现结果:
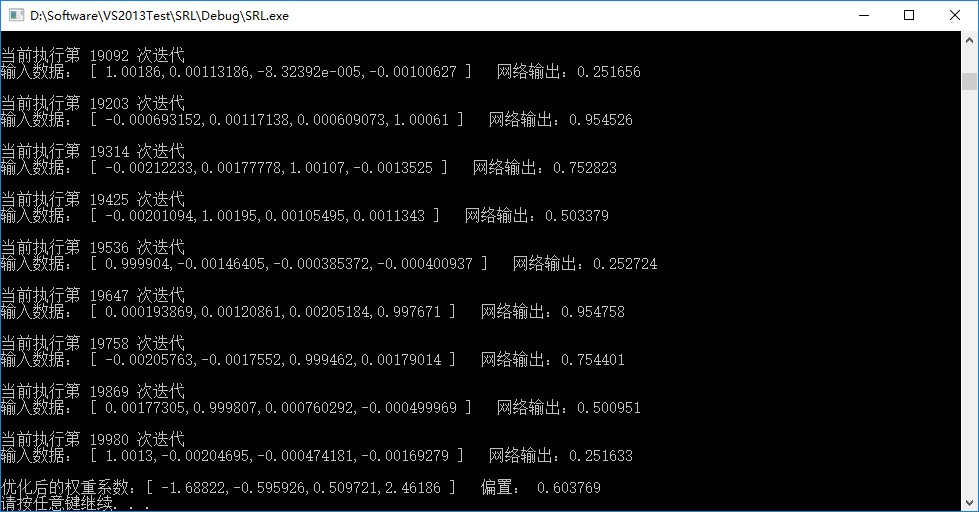
T函数的迭代实现结果:
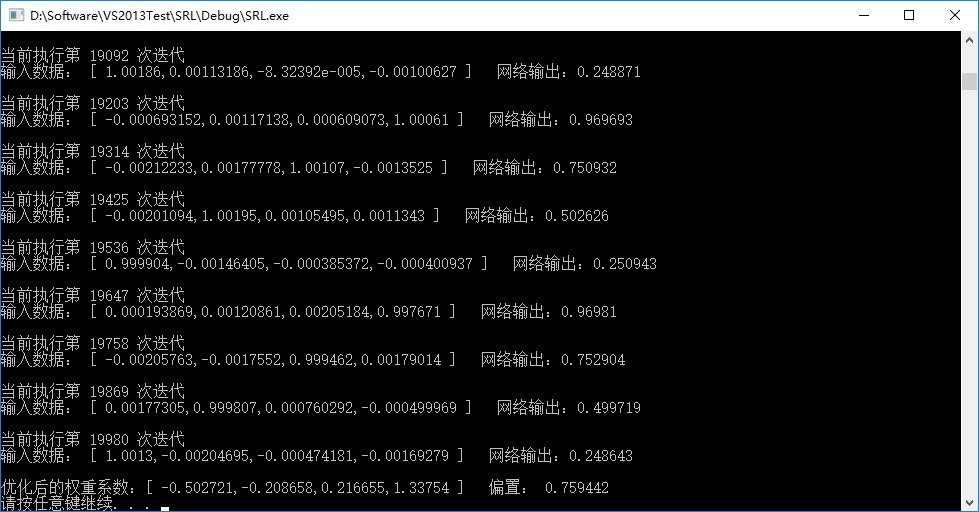
R函数的迭代实现结果: