在GPU并行编程中,一般情况下,各个处理器都需要了解其他处理器的执行状态,在各个并行副本之间进行通信和协作,这涉及到不同线程间的通信机制和并行执行线程的同步机制。
共享内存“__share__”
CUDA中的线程协作主要是通过共享内存实现的。使用关键字“__share__”声明共享变量,将使这个变量驻留在共享内存中,该变量具有以下特征:
- 位于线程块的共享存储器空间中
- 与线程块具有相同的生命周期
- 仅可通过块内的所有线程访问
对于GPU上启动的每个线程块,CUDA C编译器都将创建该变量的一个副本。 线程块中的每个线程都共享这块内存,但线程却无法看到也不能修改其他线程块的变量副本。 这就使得一个线程块中的多个线程能够在计算上进行通信和协作。而且,共享内存缓冲区驻留在物理GPU上,在访问共享内存时的延迟要远远低于访问普通缓冲区的延迟,使得共享内存的访问非常高效。
线程同步机制“__syncthreads()”
关键字“__share__”只是声明了共享变量,位于同一个线程块中的不同线程都可以访问该变量,如果没有同步机制,将会发生竞态条件 (Race Condition),导致错误的运行结果。
CUDA确保同步的方法是调用“__syncthreads()”。__syncthreads()将确保线程块中的每个线程都执行完 __syncthreads()前面的语句后,才会执行下一条语句。
以下是CUDA和OpenCV的应用中,绘制一幅图像,Grid的尺寸大小是60*60,Block的尺寸大小是10*10,在各个线程块内声明了一个共享变量sharedMem:
#include "cuda_runtime.h"
#include <highgui.hpp>
using namespace cv;
#define DIM 600 //图像长宽
#define PI 3.1415926535897932f
__global__ void kernel(unsigned char *ptr)
{
// map from blockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
__shared__ float sharedMem[16][16];
const float period = 128.0f;
sharedMem[threadIdx.x][threadIdx.y] =
255 * (sinf(x*2.0f*PI / period) + 1.0f) *
(sinf(y*2.0f*PI / period) + 1.0f) / 4.0f;
__syncthreads();
ptr[offset * 3 + 0] = 0;
ptr[offset * 3 + 1] = sharedMem[15 - threadIdx.x][15 - threadIdx.y];
ptr[offset * 3 + 2] = 0;
}
// globals needed by the update routine
struct DataBlock
{
unsigned char *dev_bitmap;
};
int main(void)
{
DataBlock data;
cudaError_t error;
Mat image = Mat(DIM, DIM, CV_8UC3, Scalar::all(0));
data.dev_bitmap = image.data;
unsigned char *dev_bitmap;
error = cudaMalloc((void**)&dev_bitmap, 3 * image.cols*image.rows);
data.dev_bitmap = dev_bitmap;
dim3 grid(DIM / 10, DIM / 10);
dim3 block(10, 10);
//DIM*DIM个线程块
kernel << <grid, block >> > (dev_bitmap);
error = cudaMemcpy(image.data, dev_bitmap,
3 * image.cols*image.rows,
cudaMemcpyDeviceToHost);
error = cudaFree(dev_bitmap);
imshow("__share__ and __syncthreads()", image);
waitKey();
}如果线程间不加入__syncthreads()同步机制,同一线程块内不同线程访问sharedMem,获取的结果可能是不一样的,生成的图像如下,有散乱的杂点:
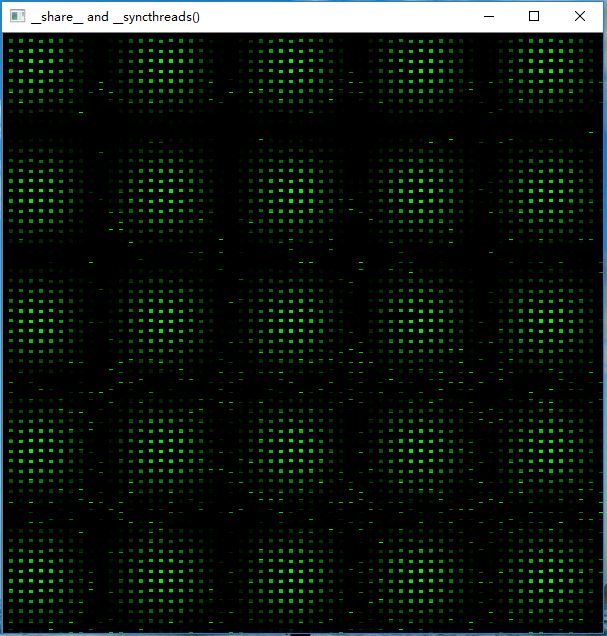
加入__syncthreads()同步机制,保证了同一线程块中不同的线程都执行完成__syncthreads()这个集合点之前的部分之后,才继续往下执行,所以不同的线程访问sharedMem获取的结果是一致的,图像无杂散点,是一个规律的排布:
