前言
很多地方我们都需要用到多标签分类,比如一张图片,上面有只蓝猫,另一张图片上面有一只黄狗,那么我们要识别的时候,就可以采用多标签分类这一思想了。任务一是识别出这个到底是猫还是狗?(类型)任务二是识别出这是蓝还是黄?(颜色)


网上看了几篇教程,有讲的非常好的,也有出bug飞上了天的(吐槽啊喂!)这里还是主要讲讲这篇:http://chuansong.me/n/494753151240。我自己已经测试了,可行,给薛大牛一个赞!但是遗憾的是这篇文章的内容严重不足啊(连lmdb生成的命令行格式都没有,还是我自己看代码琢磨了一下…)我就给这篇文章补充补充,给一些例子。
任务
我这里给出一个具体的任务咯,要求在以下图片中,识别出汽车品牌和车辆外形。汽车品牌分为:Benz/BMW/Audi 车辆外形分为:Sedan/SUV。这是一个只有72张图片的小数据库,包括了测试和训练集:

其中标注是这样的,Audi=0,BMW=1,Benz=2. Sedan =0, SUV=1。所以如果这辆车是奥迪的SUV,标注就是: xx.jpg 0 1。在数据库中,标注已经做好了。数据集的下载方式在文章的最后。
定义我们的网络结构
我们这里采用的是上述文章中薛大牛的方法,两个data层,一个data只放图片,另一个data放label,label通过slice layer切开。然后我们开始定义网络!修改AlexNet!这是我的网络:
name: "ZnNet"
layer {
name: "data"
type: "Data"
top: "data"
transform_param {
mirror: true
crop_size: 227
mean_file: "models/bvlc_alexnet/ZnCarTrainMean.binaryproto"
}
include {
phase: TRAIN
}
data_param {
source: "models/bvlc_alexnet/ZnCarTrainImage"
batch_size: 10
backend: LMDB
}
}
layer {
name: "labels"
type: "Data"
top: "labels"
include {
phase: TRAIN
}
data_param {
source: "models/bvlc_alexnet/ZnCarTrainLabel"
batch_size: 10
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
transform_param {
crop_size: 227
mean_file: "models/bvlc_alexnet/ZnCarTestMean.binaryproto"
}
include {
phase: TEST
}
data_param {
source: "models/bvlc_alexnet/ZnCarTestImage"
batch_size: 12
backend: LMDB
}
}
layer {
name: "labels"
type: "Data"
top: "labels"
include {
phase: TEST
}
data_param {
source: "models/bvlc_alexnet/ZnCarTestLabel"
batch_size: 12
backend: LMDB
}
}
layer {
name: "slice"
type: "Slice"
bottom: "labels"
top: "type" #汽车品牌
top: "surface" #车的外形
slice_param {
axis: 1
slice_point: 1
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "norm1"
type: "LRN"
bottom: "conv1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "norm1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "norm2"
type: "LRN"
bottom: "conv2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "norm2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8_type"
type: "InnerProduct"
bottom: "fc7"
top: "fc8_type"
param {
lr_mult: 5
decay_mult: 5
}
param {
lr_mult: 10
decay_mult: 0
}
inner_product_param {
num_output: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "fc8_surface"
type: "InnerProduct"
bottom: "fc7"
top: "fc8_surface"
param {
lr_mult: 5
decay_mult: 5
}
param {
lr_mult: 10
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy_type"
type: "Accuracy"
bottom: "fc8_type"
bottom: "type"
top: "accuracy_type"
include {
phase: TEST
}
}
layer {
name: "loss_type"
type: "SoftmaxWithLoss"
bottom: "fc8_type"
bottom: "type"
top: "loss_type"
loss_weight:0.5
}
layer {
name: "accuracy_surface"
type: "Accuracy"
bottom: "fc8_surface"
bottom: "surface"
top: "accuracy_surface"
include {
phase: TEST
}
}
layer {
name: "loss_surface"
type: "SoftmaxWithLoss"
bottom: "fc8_surface"
bottom: "surface"
top: "loss_surface"
loss_weight:0.5
}loss_weight是指的这一层的loss对整个网络反向传播时的贡献。我们这里两个loss,先各自设定0.5。在这里推荐大家一个网站:http://ethereon.github.io/netscope/#/editor输入自己的网络定义文件,输出直观的网络图。这样一来,我们就可以很直观的看啦:
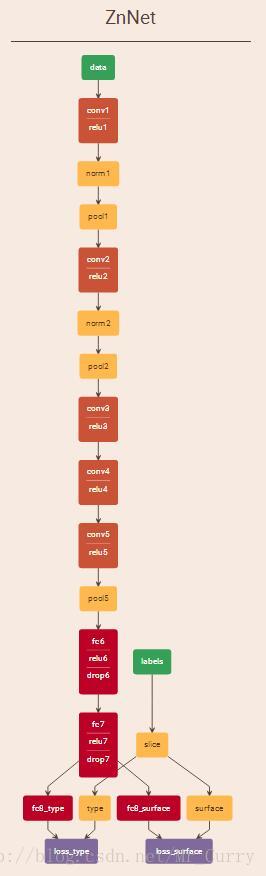
label被slice分成了两个层,各自对应相关的loss。(看起来还是很合理的对吧?)
做数据转换工具!
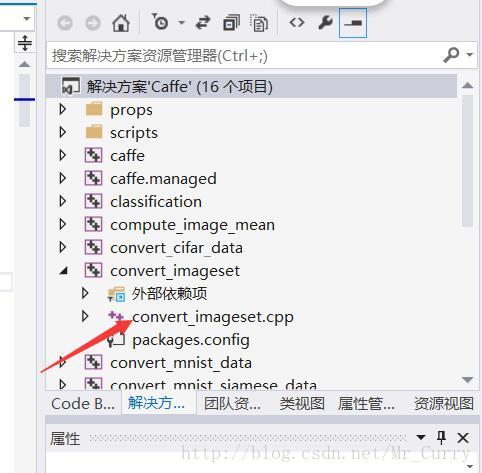
整个网络结构需要两类数据,一类是纯图片的lmdb,一类是包含两个标签的lmdb。首先我们需要修改caffe中的源码(相信我,很简单!)打开你编译caffe时候的工程,找到convert_imageset这个工程:
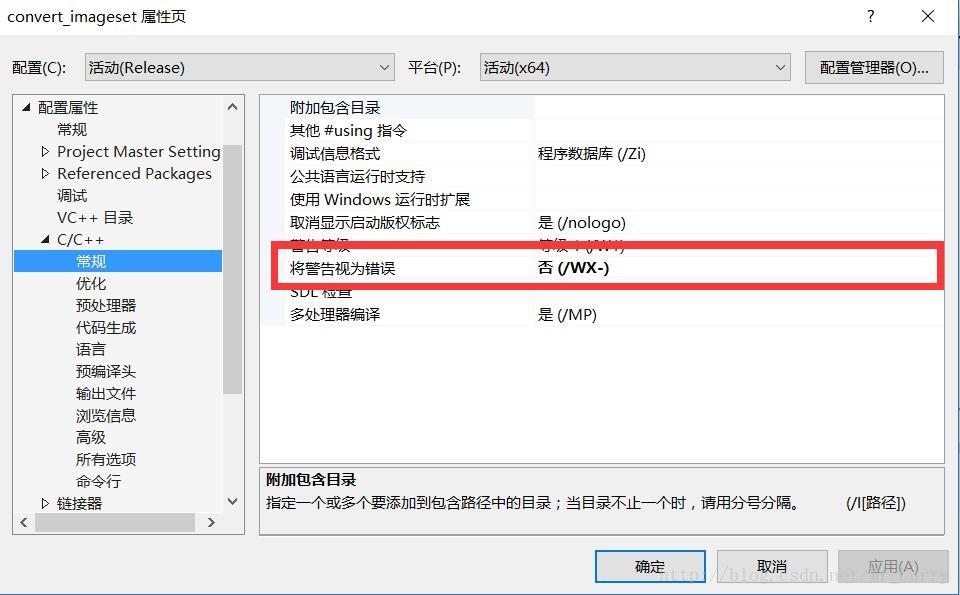
修改convert_imageset.cpp为convert_multilabel.cpp,内容如下,全部替代也可以:(见github:https://github.com/HolidayXue/CodeSnap/blob/master/convert_multilabel.cpp)然后重新编译这个convert_imageset这个project。你可能会遇到什么没有生成object的警告,在这里关掉即可:
完成后,我们会看到release文件夹下多了一个convert_multilabel的exe,这个就是我们的lmdb生成工具啦。
做图像和多标签数据!
下载我的(或者自己做也可以)数据集,用命令行命令:
convert_multilabel.exe --resize_height=227 --resize_width=227 ZnCarTrain/ ZnCarTrain/Label.txt ZnCarTrainImage ZnCarTrainLabel 2几个参数我解释一下。–resize_height=227 –resize_width=227 代表将图像缩放到227*227,ZnCar/是目录,ZnCarTrain/Label.txt是你的标注所在的地方,ZnCarTrainImage和ZnCarTrainLabel是要生成的lmdb文件夹,最后一个2代表着你这里有两类标签。(如果有更多标签需要分类的话,这里要改,slice layer和前面的loss都需要改哦~)
然后还要做均值文件:
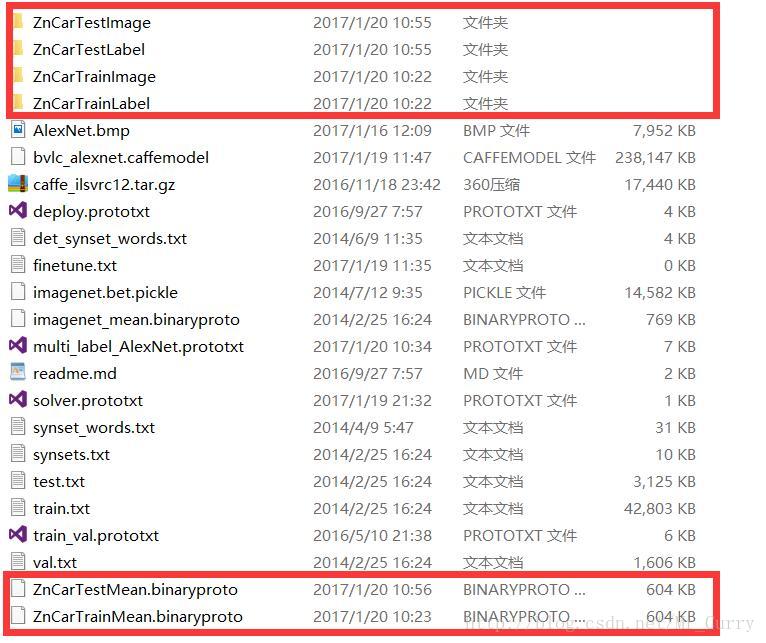
compute_image_mean.exe convert_data_train image_mean.binaryproto
pause总之最后应该有六个东西,如图:
数据制作完毕。
微调AlexNet!
网上下载一个bvlc_alexnet.caffemodel的权重文件。然后就是finetune了,参数的话得好好改改solver.prototxt里面,比如base_lr调小一点啦,迭代max_iter不要太多啦等等。此外也可以把两个fc8层的学习率适当提升一些,因为在finetune的时候训练好的权重只对原来没变的层有作用,这个新层就相当于是随机初始化的参数。
我这是用cpu训练的,很慢。(早知道就把显卡带回来了):
试一试我们的模型
我们做一个deploy文件:
name: "ZnNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 227 dim: 227 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "norm1"
type: "LRN"
bottom: "conv1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "norm1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "norm2"
type: "LRN"
bottom: "conv2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "norm2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8_type"
type: "InnerProduct"
bottom: "fc7"
top: "fc8_type"
param {
lr_mult: 5
decay_mult: 5
}
param {
lr_mult: 10
decay_mult: 0
}
inner_product_param {
num_output: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "fc8_surface"
type: "InnerProduct"
bottom: "fc7"
top: "fc8_surface"
param {
lr_mult: 5
decay_mult: 5
}
param {
lr_mult: 10
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "prob_type"
type: "Softmax"
bottom: "fc8_type"
top: "prob_type"
loss_weight:0.5
}
layer {
name: "prob_surface"
type: "Softmax"
bottom: "fc8_surface"
top: "prob_surface"
loss_weight:0.5
}
然后这里还需要修改classification.cpp文件,因为Caffe自带的只支持单样本。我自己做了一个修改版本的,主要是修改了命令行和输出网络的部分,这个cpp只支持两标签,主要是用着方便,如果你需要更多的标签可以自己修改。编译步骤同convert_multilabel.cpp的编译。底下的代码直接就可以替换原来的cpp。
convert_multilabel.cpp:
#include <caffe/caffe.hpp>
#ifdef USE_OPENCV
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#endif // USE_OPENCV
#include <algorithm>
#include <iosfwd>
#include <memory>
#include <string>
#include <utility>
#include <vector>
#ifdef USE_OPENCV
using namespace caffe; // NOLINT(build/namespaces)
using std::string;
/* Pair (label, confidence) representing a prediction. */
// change: 2 classify — (label1, confidence1) (label2, confidence2)
typedef std::pair<string, float> Prediction;
class Classifier {
public:
Classifier(const string& model_file,
const string& trained_file,
const string& mean_file,
const vector<string>& label_files);
std::vector<vector<Prediction>> Classify(const cv::Mat& img, int N = 5);
private:
void SetMean(const string& mean_file);
std::vector<vector<float>> Predict(const cv::Mat& img);
void WrapInputLayer(std::vector<cv::Mat>* input_channels);
void Preprocess(const cv::Mat& img,
std::vector<cv::Mat>* input_channels);
private:
shared_ptr<Net<float> > net_;
cv::Size input_geometry_;
int num_channels_;
cv::Mat mean_;
std::vector<vector<string>> labels_; //multi
};
Classifier::Classifier(const string& model_file,
const string& trained_file,
const string& mean_file,
const vector<string>& label_file) {
#ifdef CPU_ONLY
Caffe::set_mode(Caffe::CPU);
#else
Caffe::set_mode(Caffe::GPU);
#endif
/* Load the network. */
net_.reset(new Net<float>(model_file, TEST));
net_->CopyTrainedLayersFrom(trained_file);
CHECK_EQ(net_->num_inputs(), 1) << "Network should have exactly one input.";
//CHECK_EQ(net_->num_outputs(), 1) << "Network should have exactly one output.";
Blob<float>* input_layer = net_->input_blobs()[0];
num_channels_ = input_layer->channels();
CHECK(num_channels_ == 3 || num_channels_ == 1)
<< "Input layer should have 1 or 3 channels.";
input_geometry_ = cv::Size(input_layer->width(), input_layer->height());
/* Load the binaryproto mean file. */
SetMean(mean_file);
/* Load labels. */
//2 labels should read
string line;
for (int i = 0; i < label_file.size(); i++)
{
std::ifstream labels(label_file[i].c_str());
CHECK(labels) << "Unable to open labels file " << label_file[i];
vector<string> label_array;
while (std::getline(labels, line))
{
label_array.push_back(line);
}
Blob<float>* output_layer = net_->output_blobs()[i];
CHECK_EQ(label_array.size(), output_layer->channels())
<< "Number of labels is different from the output layer dimension.";
labels_.push_back(label_array);
}
}
static bool PairCompare(const std::pair<float, int>& lhs,
const std::pair<float, int>& rhs) {
return lhs.first > rhs.first;
}
/* Return the indices of the top N values of vector v. */
static std::vector<int> Argmax(const std::vector<float>& v, int N) {
std::vector<std::pair<float, int> > pairs;
for (size_t i = 0; i < v.size(); ++i)
pairs.push_back(std::make_pair(v[i], static_cast<int>(i)));
std::partial_sort(pairs.begin(), pairs.begin() + N, pairs.end(), PairCompare);
std::vector<int> result;
for (int i = 0; i < N; ++i)
result.push_back(pairs[i].second);
return result;
}
/* Return the top N predictions. */
std::vector<vector<Prediction>> Classifier::Classify(const cv::Mat& img, int N) {
auto output = Predict(img);
int N1 = std::min<int>(labels_[0].size(), N);
int N2 = std::min<int>(labels_[1].size(), N);
std::vector<int> maxN1 = Argmax(output[0], N1);
std::vector<int> maxN2 = Argmax(output[1], N2);
std::vector<Prediction> predictions1;
std::vector<Prediction> predictions2;
for (int i = 0; i < N1; ++i) {
int idx = maxN1[i];
predictions1.push_back(std::make_pair(labels_[0][idx], output[0][idx]));
}
for (int i = 0; i < N2; ++i) {
int idx = maxN2[i];
predictions2.push_back(std::make_pair(labels_[1][idx], output[1][idx]));
}
vector<vector<Prediction>> predictions;
predictions.push_back(predictions1);
predictions.push_back(predictions2);
return predictions;
}
/* Load the mean file in binaryproto format. */
void Classifier::SetMean(const string& mean_file) {
BlobProto blob_proto;
ReadProtoFromBinaryFileOrDie(mean_file.c_str(), &blob_proto);
/* Convert from BlobProto to Blob<float> */
Blob<float> mean_blob;
mean_blob.FromProto(blob_proto);
CHECK_EQ(mean_blob.channels(), num_channels_)
<< "Number of channels of mean file doesn't match input layer.";
/* The format of the mean file is planar 32-bit float BGR or grayscale. */
std::vector<cv::Mat> channels;
float* data = mean_blob.mutable_cpu_data();
for (int i = 0; i < num_channels_; ++i) {
/* Extract an individual channel. */
cv::Mat channel(mean_blob.height(), mean_blob.width(), CV_32FC1, data);
channels.push_back(channel);
data += mean_blob.height() * mean_blob.width();
}
/* Merge the separate channels into a single image. */
cv::Mat mean;
cv::merge(channels, mean);
/* Compute the global mean pixel value and create a mean image
* filled with this value. */
cv::Scalar channel_mean = cv::mean(mean);
mean_ = cv::Mat(input_geometry_, mean.type(), channel_mean);
}
std::vector<vector<float>> Classifier::Predict(const cv::Mat& img) {
Blob<float>* input_layer = net_->input_blobs()[0];
input_layer->Reshape(1, num_channels_,
input_geometry_.height, input_geometry_.width);
/* Forward dimension change to all layers. */
net_->Reshape();
std::vector<cv::Mat> input_channels;
WrapInputLayer(&input_channels);
Preprocess(img, &input_channels);
net_->Forward();
/* Copy the output layer to a std::vector */
Blob<float>* output_layer1 = net_->output_blobs()[0];
Blob<float>* output_layer2 = net_->output_blobs()[1];
const float* begin1 = output_layer1->cpu_data();
const float* end1 = begin1+ output_layer1->channels();
const float* begin2 = output_layer2->cpu_data();
const float* end2 = begin2 + output_layer2->channels();
std::vector<float> prob1(begin1, end1);
std::vector<float> prob2(begin2, end2);
vector<vector<float>> prob_matrix;
prob_matrix.push_back(prob1);
prob_matrix.push_back(prob2);
return prob_matrix;
}
/* Wrap the input layer of the network in separate cv::Mat objects
* (one per channel). This way we save one memcpy operation and we
* don't need to rely on cudaMemcpy2D. The last preprocessing
* operation will write the separate channels directly to the input
* layer. */
void Classifier::WrapInputLayer(std::vector<cv::Mat>* input_channels) {
Blob<float>* input_layer = net_->input_blobs()[0];
int width = input_layer->width();
int height = input_layer->height();
float* input_data = input_layer->mutable_cpu_data();
for (int i = 0; i < input_layer->channels(); ++i) {
cv::Mat channel(height, width, CV_32FC1, input_data);
input_channels->push_back(channel);
input_data += width * height;
}
}
void Classifier::Preprocess(const cv::Mat& img,
std::vector<cv::Mat>* input_channels) {
/* Convert the input image to the input image format of the network. */
cv::Mat sample;
if (img.channels() == 3 && num_channels_ == 1)
cv::cvtColor(img, sample, cv::COLOR_BGR2GRAY);
else if (img.channels() == 4 && num_channels_ == 1)
cv::cvtColor(img, sample, cv::COLOR_BGRA2GRAY);
else if (img.channels() == 4 && num_channels_ == 3)
cv::cvtColor(img, sample, cv::COLOR_BGRA2BGR);
else if (img.channels() == 1 && num_channels_ == 3)
cv::cvtColor(img, sample, cv::COLOR_GRAY2BGR);
else
sample = img;
cv::Mat sample_resized;
if (sample.size() != input_geometry_)
cv::resize(sample, sample_resized, input_geometry_);
else
sample_resized = sample;
cv::Mat sample_float;
if (num_channels_ == 3)
sample_resized.convertTo(sample_float, CV_32FC3);
else
sample_resized.convertTo(sample_float, CV_32FC1);
cv::Mat sample_normalized;
cv::subtract(sample_float, mean_, sample_normalized);
/* This operation will write the separate BGR planes directly to the
* input layer of the network because it is wrapped by the cv::Mat
* objects in input_channels. */
cv::split(sample_normalized, *input_channels);
CHECK(reinterpret_cast<float*>(input_channels->at(0).data)
== net_->input_blobs()[0]->cpu_data())
<< "Input channels are not wrapping the input layer of the network.";
}
int main(int argc, char** argv) {
if (argc != 7) {
std::cerr << "Usage: " << argv[0]
<< " deploy.prototxt network.caffemodel"
<< " mean.binaryproto label1.txt label2.txt img.jpg" << std::endl;
return 1;
}
::google::InitGoogleLogging(argv[0]);
string model_file = argv[1];
string trained_file = argv[2];
string mean_file = argv[3];
string label_file1 = argv[4];
string label_file2 = argv[5];
vector<string> label_file;
label_file.push_back(label_file1);
label_file.push_back(label_file2);
std::cout << "the labels' channel:"<<label_file.size() << std::endl;
Classifier classifier(model_file, trained_file, mean_file, label_file);
string file = argv[6];
std::cout << "---------- Prediction for "
<< file << " ----------" << std::endl;
cv::Mat img = cv::imread(file, -1);
CHECK(!img.empty()) << "Unable to decode image " << file;
auto predictions = classifier.Classify(img);
std::cout << "have runed classifier.Classify" << std::endl;
/* Print the top N predictions. */
std::cout << "---------- Surface------------" << std::endl;
for (size_t i = 0; i < predictions[0].size(); ++i) {
Prediction p = predictions[0][i];
std::cout << std::fixed << std::setprecision(4) << p.second << " - ""
<< p.first << """ << std::endl;
}
std::cout << " ---------- Type------------" << std::endl;
for (size_t i = 0; i < predictions[1].size(); ++i) {
Prediction p = predictions[1][i];
std::cout << std::fixed << std::setprecision(4) << p.second << " - ""
<< p.first << """ << std::endl;
}
}
#else
int main(int argc, char** argv) {
LOG(FATAL) << "This example requires OpenCV; compile with USE_OPENCV.";
}
#endif // USE_OPENCV
结果
写两个标注文件:
label1.txt:
Sedan
SUV
label2.txt:
Audi
BMW
Benz我修改后的classification.exe 分类的命令行:
classification.exe deploy.prototxt network.caffemodel mean.binaryproto label1.txt label2.txt img.jpg

本项目的Github网址:https://github.com/ChenJoya/Caffe_MultiLabel_Classification
数据集:http://download.csdn.net/detail/mr_curry/9742578
求星星~~