CNN 大概是目前 CV 界最火爆的一款模型了,堪比当年的 SVM。从 2012 年到现在,CNN 已经广泛应用于CV的各个领域,从最初的 classification,到现在的semantic segmentation, object detection,instance segmentation,super resolution 甚至 optical flow 都能看的其身影。还真是,无所不能。
虽然 CNN 的应用可以说是遍地开花,但是细究起来,可以看到 CNN 的基本模型还是万变不离其宗,总是少不了最基础的一些模块,比如 convolution layer, pooling layer 和 fully connected layer,就是基于这些最基础的模块,结合具体的应用,构造了不同的网络结构,进而达到不同的目的。
今天,我们想探讨一下 CNN 网络里面几个基本的概念,掌握并且熟悉这些概念对于理解 CNN 模型有很大的帮助。
我们要理解的概念包括:
卷积的基本运算
receptive field (感受野)
feature maps
卷积的基本运算
先介绍第一个概念,卷积的运算,我们知道图像处理里面有很多的滤波操作,比如高斯滤波,拉普拉斯滤波,这些其实都是基于卷积的一种运算。
这里 表示一张图像,而 表示卷积核,或者滤波器。卷积简单来说就是对像素邻域的一种操作。这里,我们不讨论卷积的具体表示,我们讨论卷积运算前后图像的尺度变化,这个对于后面理解 receptive field 非常重要。一张 的图像,经过一个 卷积核运算,假设卷积运算时候的 stride 为 ,那么我们可以求得输出图像的尺寸为:
比如说,一个 的图像块和一个 的卷积核做卷积,最后输出的图像块的尺寸为 ,这里我们默认卷积核是逐个像素滑动的,即 stride 为 1,有的时候,我们希望输出图像的尺寸和输入图像的尺寸一样大,这里有不同的处理方式,比较常见的一种方式就是给输入图像的四边补 0,也就是所谓的 zero padding, 我们先把输入图像变大,这样输出图像就会和原来的图像一样大。结合 zero padding,我们可以求得输出图像的大小为:
Receptive Field
知道了卷积的运算规则,我们来看看 CNN 中的 receptive field 这个概念,receptive field 顾名思义,就是一个像素的感受范围,因为卷积都是基于邻域的操作,所以一般来说,每一层的像素,都是前一层的一个邻域通过卷积运算得到的,我们来看一个层级的 receptive field:
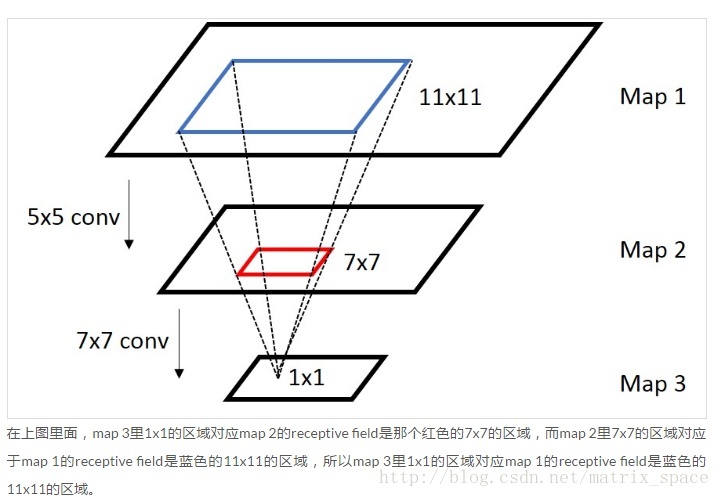
我们看到,最下面一层一个像素,对应的中间一层的 receptive field 是 的一个范围,因为卷积核是 ,而中间一层的每一个像素,对应最上面一层的 receptive filed 的范围是 ,那么,最下面一层的每一个像素,对应最上面一层的 receptive field 是多少呢?这里就要用到我们上面介绍的卷积运算的规则,我们可以把上面的卷积规则表示成更一般的表达式:
表示第 层的 feature map 的尺寸, 表示第 层的 feature map 的尺寸,那么我们可以反过来求出:
以上图作为参考,, 这里假设 stride , padding , 第二层到第三层的卷积核是 ,所以 , 我们可以求得 ,所以第二层的 receptive field 是 , 那么 ,所以第一层的 receptive field是 所以这就是我们计算每一层 receptive field 的公式,通过层层递推得到。
这是计算不同 layer 之间的 receptive field,有的时候,我们需要计算的是一种坐标映射关系,即 receptive filed 的中心点的坐标,这个坐标映射关系满足下面的关系:
在 Fast R-CNN, SPP-Net 等网络中,需要从 feature map 中找到对应的输入图像的 ROI,就是要用上面的表达式从后往前一层一层递推得到:
从上面可以看到,如果我们知道第 层中一个像素点的位置 ,我们可以计算出输入图像上对应的 receptive filed 的中心点的位置 , 这个最后可以总结成如下的表达式:
SPP-net 中,把 feature map 中的一个区域,映射到输入图像上的 ROI 的时候,做了一些处理,就是让每一层的 padding 都等于卷积核的半径,这样坐标最后只和 stride 有关。
Feature map
最后,我们说一下 feature map,这个可以说是 CNN 和传统的 MLP 的最大的不同,Feature map 中的神经元是共享权重系数的,feature map 中的每一个神经元对应的就是前一层的 feature map 中的某个邻域,反应的是这个邻域与卷积核做卷积之后的一种响应,因为这是一种局部的响应,所以 feature map 可以记录 feature ,也可以记录 location,响应的位置,利用这个特性,可以用来做 目标检测。
参考:
https://zhuanlan.zhihu.com/p/24780433 晓雷机器学习笔记
http://cs231n.stanford.edu/ CS231n: Convolutional Neural Networks for Visual Recognition
iccv2015_tutorial_convolutional_feature_maps_kaiminghe