从算法的命名上来说,PReLU 是对 ReLU 的进一步限制,事实上 PReLU(Parametric Rectified Linear Unit),也即 PReLU 是增加了参数修正的 ReLU。
在功能范畴上,ReLU 、 PReLU 和 sigmoid 、 tanh 函数一样都是作为神经元的激励函数(activation function)。
1. ReLU 与 PReLU
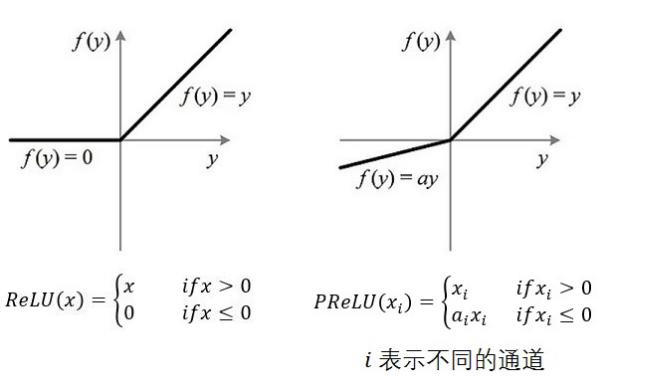
注意图中通道的概念,不通的通道对应不同的 $$
如果
2. 说明
PReLU 只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的,当不同 channels 使用相同的
ai 时,参数就更少了。BP 更新
ai 时,采用的是带动量的更新方式,如下图:Δai:=μΔai+ϵ∂ε∂ai 上式的两个系数分别是动量和学习率。
需要特别注意的是:更新
ai 时不施加权重衰减(L2正则化),因为这会把ai 很大程度上 push 到 0。事实上,即使不加正则化,试验中ai 也很少有超过1的。整个论文,
ai 被初始化为 0.25。
3. references
《Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification》