前言
在前两篇中,主要讲了ER建模和关系建模。在具体分析如何用数据库管理软件RDBMS(Relational Database Management System)实现这些关系前,我想有必要思考下面这个问题:
为什么要这么麻烦?为什么又是ER建模又是关系建模的?
本篇的出发点就是回答这个问题。然而某种程度上,也是回答另一个本质性的问题:为什么要有数据库?
更新异常
数据库的四大操作:增,删,改,查中,除了查,其他三个都可归为更新操作。而总的来说,ER建模和关系建模的目的,就是为了避免因大量冗余数据导致的数据库更新异常。
接下来本文将使用一张旅游公司的数据表,来具体分析没有ER建模和关系建模将导致的问题。
该数据表将由以下这些列组成:
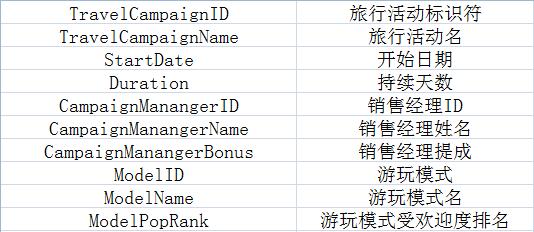
下面是该表内的一部分数据:

(字看不清的话请将图片下载到本地观看)
看到这张表的第一眼,就能发现有很多冗余数据存在,比如红框中的部分:

为什么信息冗余会导致更新异常呢?下面将对三种更新操作:插入,删除,修改可能出现的异常分别进行分析。
1. 插入异常(insertion anomaly)
这种异常是指当用户想要插入某一真实世界的实体数据时,还必须输入另一个真实世界中实体的数据。
举例来说,公司业务发展,新建了一个“家庭主妇团”的模式。但我要想往表里录入一个新的模式,还必须绑定地录入一个新的活动。
2. 删除异常(deletion anomaly)
这种异常是指当用户要删除某一真实世界的实体数据时,还必须删除另一个真实世界中实体的数据。
举例来说,假如删除下图红框中的记录:

(字看不清的话请将图片下载到本地观看)
就会导致把“老年人团”这种模式的相关数据也给清除掉了。
3. 修改异常(modification anomaly)
这种异常是指当用户要修改某个值的时候,同样的修改操作需要重复多次。
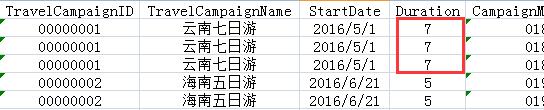
举例来说,假如公司为了吸引客户,决定多送一天,因而需要将”云南七日游“的持续时间改为8天。这时需要改动的地方就有三处了,如下图红框中所示:
函数依赖
上述的这些更新异常,都可通过规范化设计的方式避免。在详细介绍规范化设计之前,首先来讨论一个重要的概念:函数依赖(functional dependency)。
函数依赖,是指关系中每行记录的某一列(或几列)的值唯一决定该条记录另一列的值。总的来说,有以下几种函数依赖:
1. 平凡函数依赖(trivial functional dependency)
是指一个或多个属性确定它自己,或者它的子集。如本文样例数据集中TravelCampaignID,TravelCampaignName -> TravelCampaignID就是一个平凡函数依赖。
注:这种依赖在规范化中不会被用到。
2. 增广函数依赖(augmented functional dependency)
是指某个依赖式为真,则依赖式左侧,或者两侧同时增加某语句形成的一种依赖关系。如本文样例数据集中TravelCampaignID,ModleID -> TravelCampaignName。因为只需要TravelCampaignID就能够确定TravelCampaignName了。
注:这种依赖在规范化中不会被用到。
3. 等价函数依赖(equivalent functional dependency)
这种依赖关系是一对对的。比如若A->B和B->A都为真,那么A能推出来的,B同样也能推出来,因此A->B和B->A就被称作等价函数依赖。如本文样例数据集中TravelCampaignID-> TravelCampaignName和TravelCampaignName-> TravelCampaignID。
注:这种依赖只需保留一组依赖关系即可,但它不属于规范化的范畴。
4. 部分函数依赖(partial functional dependency)
是指关系的一列函数依赖于组合主码的一部分。显然这种依赖只有组合主码才存在。如本文样例数据中ModelID->ModelName,因为记录的复合主码(TravelCampaignID, ModelID)能确定记录的任何一列,ModelID只是该复合主码的一部分。
注:这种依赖关系属于规范化范畴。
5. 完全函数依赖(full key functional dependency)
是指复合主码函数确定关系中的其他列,并且复合主码的任意部分不能单独确定其他列。这个概念和上面的部分函数依赖显然是对立的。
注:这种依赖关系属于规范化范畴。
6. 传递函数依赖(transitive functional dependency)
是指非码列函数确定关系中的其他非码列。如本文样例数据中CampaignManangerID->CampaignManangerName显然就是一个传递函数依赖。
这六种函数依赖中只有后面三种和规范化设计有关。前面三种则因为对改进冗余信息并没有帮助,不纳入规范化过程中。
规范化
规范化设计能够有效的避免数据冗余导致的更新异常,它基于范式思想。一个关系是否满足某种范式通常要看它是否不包含某个函数依赖。
下面首先来看看这几个范式的定义:
1. 第一范式(1NF)
一个表如果每一行都是唯一,并且任何行都没有包含多个值的列,则它满足1NF。但对于关系表来说,真正的规范化过程从第二范式开始,因为关系表本身已经满足1NF了。
2. 第二范式(2NF)
一个表如果满足1NF,并且不包含部分函数依赖,则这个表满足2NF。
3. 第三范式(3NF)
一个表如果满足2NF,并且不包含传递函数依赖,则这个表满足3NF。
至于3NF以上的范式,则基于其他函数依赖,对于减少数据冗余消除异常没有多大帮助。这里就不再介绍了。
对样例数据进行第三范式规范化后,结果如下(红字列对应主码):
旅行活动表:

业务经理表:

游玩模式表:

旅行活动 - 游玩模式联系表:

现在请读者自行思考一下,更新异常解决了吗?答案是肯定的。但是也不能说100%的冗余信息都去除了,比如说外码的映射关系就重复了一次。
那么如果要对外码进行变更,有什么办法保证不异常呢?这部分内容将在第五篇讲解。
规范化的例外情况
并不是说所有的关系都必须满足3NF,没有那么绝对。有些时候可以考虑降到2NF。
比如说下面这个是某公司销售经理信息表:
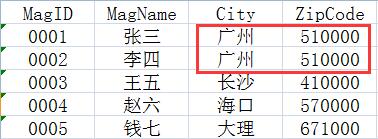
这张表并不满足3NF,因为邮编和城市之间存在了部分函数依赖,从而有信息冗余(见上图红框部分)。但由于该公司同一地区最多只有两名销售经理,因此冗余情况很少,规范化到3NF让表设计显得过于复杂化了。因此这种情况可以考虑不升级到3NF,让上层实现去解决冗余问题。
ER建模,关系建模与规范化设计
看到这里,它们之间的关系也就呼之欲出了。这些建模工作的作用,就是能够让设计的关系更容易满足规范化设计中的(第三)范式要求,从而减少数据冗余,消除更新异常。
在实际开发中,绝大部分情况还是按着ER建模->关系建模->物理模型建模来走。这样设计出来的表绝大部分满足第三范式,只有小部分地方需要调整一下,根据实际情况决定是选用3NF还是2NF,其中前者占大多数情况。
不按这个套路来,后果就是前文提到的那一堆更新异常。
小结
看完本文的分析,读者应该明白了前两篇所做的工作:ER建模和关系建模的根本意义所在,也应该体会到了关系数据库理论的价值。
接下来的一篇,将讲解如何具体在数据库管理软件RDBMS里创建这些表,以及如何对这些表进行增,删,改,查等操作。这些工作将使用到大名鼎鼎的SQL,它是目前最受数据分析师,数据挖掘工程师们欢迎的语言。
好吧,之一...^_^。