前言
本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路。
模型架构
在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角色:一个是JobTracker,一个是TaskTracker,前者用于管理和调度工作,后者用于执行工作。
一般来说,一个Hadoop集群由一个JobTracker和N个TaskTracker构成。
执行流程
每次计算任务都可以分为两个阶段,Map阶段和Reduce阶段。
其中,Map阶段接收一组键值对模式<key, Value>的输入并产生同样是键值对模式<key, Value>的中间输出;
Reduce阶段负责接收Map产生的中间输出<key, Value>,然后对这个结果进行处理并输出结果。
这里举个很简单的例子,有一个程序用来统计文本中各个单词出现的个数,那么每个Map任务可以负责提取出文本中的所有单词并产生n个<word, 1>这样的输出;
而Reduce任务可以负责对这些中间输出做出处理,转换成<word, n> 这样的输出。
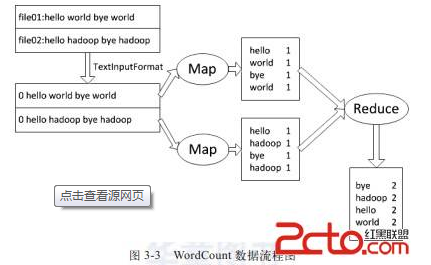
多说一句,Map产生的中间输出是直接放在本地磁盘,job完成后就会删除了。而Reduce产生的最终结果才会存放在Hdfs上。
编码框架说明
编码涉及到一些细节,建议结合具体代码进行分析,这里只给出一个框架性的说明。推荐阅读经典的wordcount程序。
1. 导入Hadoop开发需要用到的一些包
2. 定义一个需要用到分布式计算的类
3. 在此类中添加Map类,并使该类继承Mapper抽象类,然后实现该抽象类中的map方法。
4. 在此类中添加Reduce类,并使该类继承Reducer抽象类,然后实现该抽象类中的reduce方法。
5. 在类中定义一个成员函数并做如下操作:
a. 定义一个Job对象负责job调度
b. 往a中定义的job对象中注入2中定义的分布式类 (setJarByClass)
c. 定义分布式任务的名字 (setJobName)
d. 往a中定义的job对象中注入输出的key和value的类型 (setOutPutKeyClass,setOutPutKeyClass)
e. 往a中定义的job对象中注入3和4中定义的Map,Reduce类
f. 往a中定义的job对象中注入数据切分格式类 (setInputFormat,setOutputFormat)
g. 往a中定义的job对象中注入输出的路径地址 (setInputPaths,setOutputPath)
h. 启动计算任务 (waitForCompletion)
i. 返回布尔类型的执行结果
6. 在主函数中调用上述方法 (命令行方式)
运行方法
1. 执行以下格式的命令以编译分布式计算类
1 javac -classpath "hadoop目录下的core.jar" -d "结果输出目录" "分布式类文件名"
2. 执行以下格式的命令将该类打包成jar
1 jar -cvf "结果文件名(后缀.jar)" -C "目标目录" "结果输出目录"
3. 执行以下格式的命令将输入文件存入HDFS文件系统 (该命令将在HDFS上创建一个名为input的目录并将用户目录下input目录内前缀为file的文件导入进去):
1 dfs -mkdir input 2 dfs -put ~/input/file0* input
4. 执行以下格式的命令启动hadoop程序 (下面的参数一和二一般分别指输入和输出目录)
1 jar "分布式类jar包" "分布式类名" 参数一,参数二......
MapReduce的数据流和控制流
下面来讨论一下Hadoop程序的数据流和控制流的关系,首先请看下图:
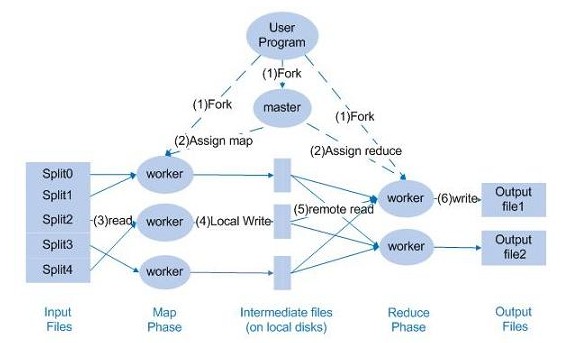
首先,由Master,也即JobTracker负责分派任务到下面的各个worker,也即TaskTracker。
某个worker在执行的时候,会返回进度报告,master负责记录进度的进行状况。
若某个worker失败,那么master会分派这个执行失败的任务给新的worker。
程序优化技巧
MapReduce程序的优化主要集中在两个方面:一个是运算性能方面的优化;另一个是IO操作方面的优化。
具体体现在以下的几个环节之上:
1. 任务调度
a. 尽量选择空闲节点进行计算
b. 尽量把任务分配给InputSplit所在机器
2. 数据预处理与InputSplit的大小
尽量处理少量的大数据;而不是大量的小数据。因此可以在处理前对数据进行一次预处理,将数据进行合并。
如果自己懒得合并,可以参考使用CombineFileInputFormat函数。具体用法请查阅相关函数手册。
3. Map和Reduce任务的数量
Map任务槽中任务的数量需要参考Map的运行时间,而Reduce任务的数量则只需要参考Map槽中的任务数,一般是0.95或1.75倍。
4. 使用Combine函数
该函数用于合并本地的数据,可以大大减少网络消耗。具体请参考函数手册。
5. 压缩
可以对一些中间数据进行压缩处理,达到减少网络消耗的目的。
6. 自定义comparator
可以自定义数据类型实现更复杂的目的。
小结
本文大致讲解了Hadoop的编程模型MapReduce,并大致介绍了如何在这个框架下进行简单的程序开发。
更复杂的框架剖析以及Hadoop高级程序开发,将在以后的文章中进行细致的探讨。