前言
在MapReduce程序中,待处理的数据最开始是放在HDFS上的,这点无异议。
接下来,数据被会被送往一个个Map节点中去,这也无异议。
下面问题来了:数据在被Map节点处理完后,再何去何从呢?
这就是本文探讨的话题。
Shuffle
在Map进行完计算后,将会让数据经过一个名为Shuffle的过程交给Reduce节点;
然后Reduce节点在收到了数据并完成了自己的计算后,会将结果输出到Hdfs。
那么,什么是Shuffle阶段,它具体做什么事情?
需要知道,这可是Hadoop最为核心的所在,也是号称“奇迹出现的地方“ = =#
Shuffle具体分析
首先,给出官方对于Shuffle流程的示意图:
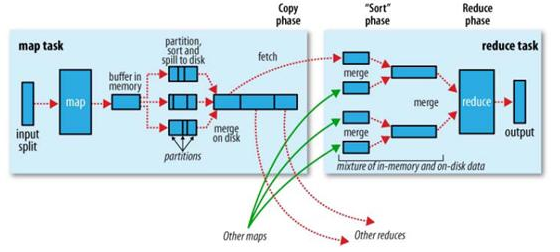
Shuffle过程植入于Map端和Reduce端两边
1. Map端工作:
a. 分区:根据键值对的Key值,选定键值对所属的Partition区间(与Reduce节点对应)。
b. 排序:对各分区内的键值对根据键进行排序。
c. 分割:Map端的结果先是存放在缓冲区内的,如果超出,自然就要执行分割的处理,将一部分数据发往硬盘。
d. 合并:对于要发送往同一个节点的键值对,我们需要对它进行合并。(这一步很可能针对硬盘,对于海量数据处理,缓冲区溢出是很正常的事情)
2. Reduce端工作:
a. Copy:以HTTP的方式从指定的Map端拉数据,注意是Map端的本地磁盘。
b. 合并:一个Reduce节点有可能从多个Map节点获取数据,获取到之后
c. 排序:对各分区内的键值对根据键进行排序。和Map端操作一样。
小结
对于这部分的内容,以后有机会做Hadoop性能方面的工作时,会继续学习研究。