前言
在对数据有了大致的了解以后,就需要对获取到的数据进行一个预处理了。预处理的过程并不简单,大致来说分成缺失值处理,异常值处理,数据归约等等 (可根据实际情况对这些阶段进行科学的取舍)。
下面将对这几个阶段一个个讲解。(本文中测试数据集nhanes2来自包lattice)
缺失值处理
1. 首先要了解到数据集的缺失情况。
下面两行命令分别获取到缺失的字段数和完整样本数:

显然缺失字段个数为27,完整样本数为13。
2. 使用mice包的md.pattern函数来获取具体的缺失情况:

第一行第一列表示完整样本数(缺失/非缺失字段描述参考2-4列,1表示没缺失,0表示缺失);最后一列表示该种描述中缺失的字段数。
第二行至第五行情况类似。
最后一行中,2-4列表示对应的字段缺失数,最后一列表示总的字段缺失数。
3. 缺失值的处理:
a) 删除法

b) 插补法(均值插补为例)
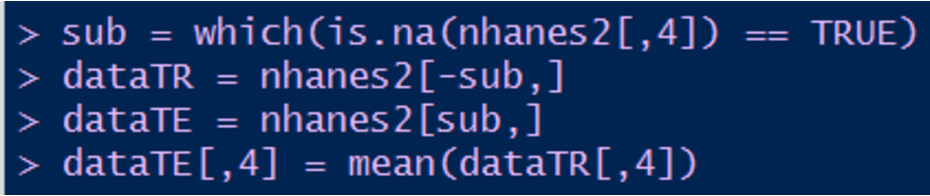
上述代码首先将数据分为有缺失字段样本集和无缺失字段样本集,然后将有缺失字段的样本集的第四个字段进行均值补全。其他字段的补全同理。
小结
R语言中提供的缺失值处理方案远不止于此。
在何种条件下选择何种插补策略是个很有挑战的问题,本文不展开探讨。