延续上一篇的话题继续,顺便放上一篇的传送门:点这里。
集群的必要性
consul本身就是管理集群的,现在还需要给consul搞个集群,这是为啥?因为consul单点也容易挂啊!万一管理集群的consul挂掉了,那么相当于上下游应用都变成了瞎子,看不到也调不到。所以集群的必要性不用我说了吧?
Server & Client
生产环境下,可以选择上面两种模式,下面我就简称S端、C端。说说它俩有啥不一样:
S端:
1、数量不宜过多,一般推荐3、5个,要求是奇数。
2、持久化保存节点数据。
3、多个S端之间是主从关系(Leader/Follower),Leader要额外负责监控各节点的健康并且同步给Follower。
C端:
1、数量没限制。
2、不保存节点数据。
相同点就是S端、C端都可以注册、查询。
Leader & Follower
这模式我简称主从好了,它只针对S端。Leader是根据Raft算法自动选举得出的,不用手动指定,所有的Follower接到信息以后,都要提交给Leader,然后Leader同步给其他的Follower。并且Leader要一直发心跳给所有的Follower证明“我还活着”,否则其他的Follower之间就要再选举出一个新的Leader了。这就导致S端最好不要扩展太多,否则你会怀疑人生。至于为什么要求S端数量是奇数,其实很好理解,偶数容易影响选举结果导致效率变低,比如两票对两票,谁来当Leader?其实去了解一下Raft算法就知道这里的主从怎么运行的,什么原理。我上个神器:戳这里,不用谢我。
S端
老规矩,还是用docker。先跑三个起来:
docker run -d --restart=always --name=server1 -e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt":true}' -p 8300:8300 -p 8301:8301 -p 8301:8301/udp -p 8302:8302/udp -p 8302:8302 -p 8400:8400 -p 8500:8500 -p 8600:8600 -h server1 consul agent -server -bind=0.0.0.0 -bootstrap-expect=3 -node=server1 -data-dir=/tmp/data-dir -client 0.0.0.0 -ui
docker run -d --restart=always --name=server2 -e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt":true}' -p 9300:8300 -p 9301:8301 -p 9301:8301/udp -p 9302:8302/udp -p 9302:8302 -p 9400:8400 -p 9500:8500 -p 9600:8600 -h server2 consul agent -server -bind=0.0.0.0 -join=你服务器的IP -node=server2 -data-dir=/tmp/data-dir -client 0.0.0.0 -ui
docker run -d --restart=always --name=server3 -e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt":true}' -p 10300:8300 -p 10301:8301 -p 10301:8301/udp -p 10302:8302/udp -p 10302:8302 -p 10400:8400 -p 10500:8500 -p 10600:8600 -h server3 consul agent -server -bind=0.0.0.0 -join=你服务器的IP -node=server3 -data-dir=/tmp/data-dir -client 0.0.0.0 -ui
bootstrap-expect:集群所需S端的最小数量,低于这个数量无法选举出leader。
join:加入到哪个集群,需要目标服务器放通tcp8301端口,否则会出现这种情况

可以语句查看主从关系:
docker exec -t server1 consul operator raft list-peers

也可以直接进入页面查看主从关系,结果一样:
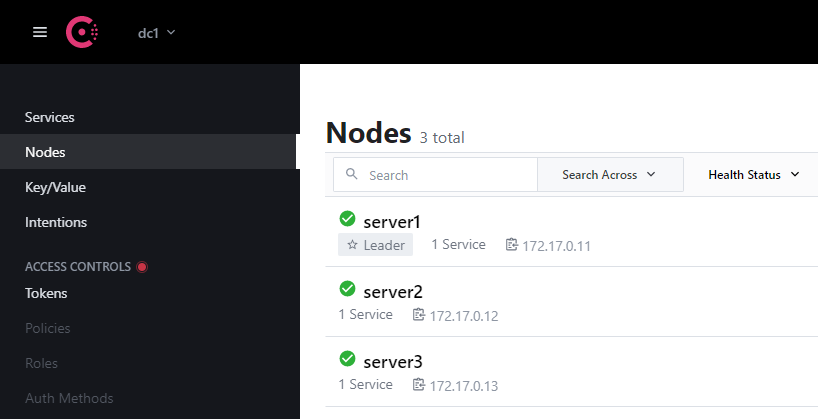
把现在的leader干掉的话,会自动选举一个新的leader出来:
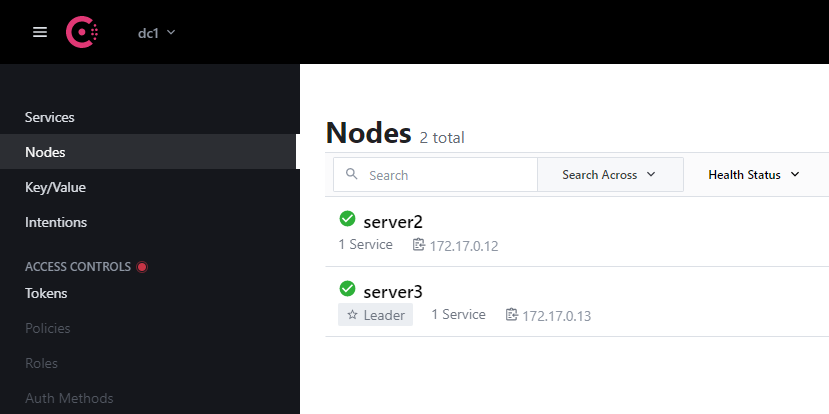
server3成为了新的leader,而且只要它不挂,leader身份是不会转移的。比如我把server1启动以后,leader没有转移过去:

OK,现在S端已经是集群了,而且它们之间的数据都是互通共存的。验证一下:
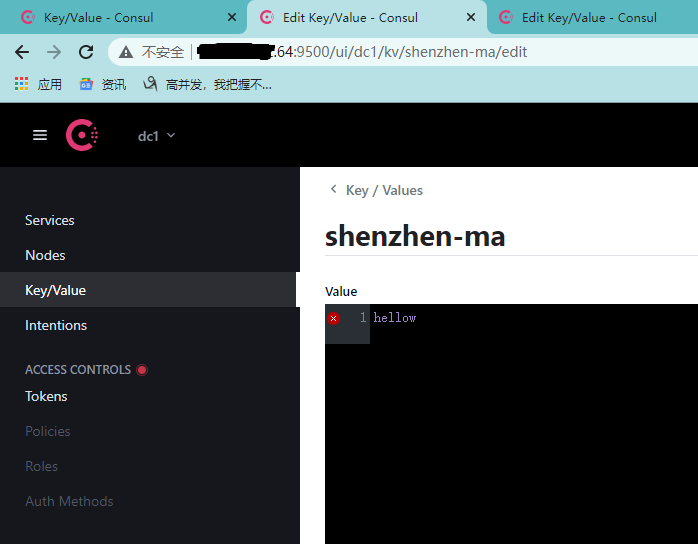
server1新增键值,key=shenzhenma,value=hellow:

server2查看:
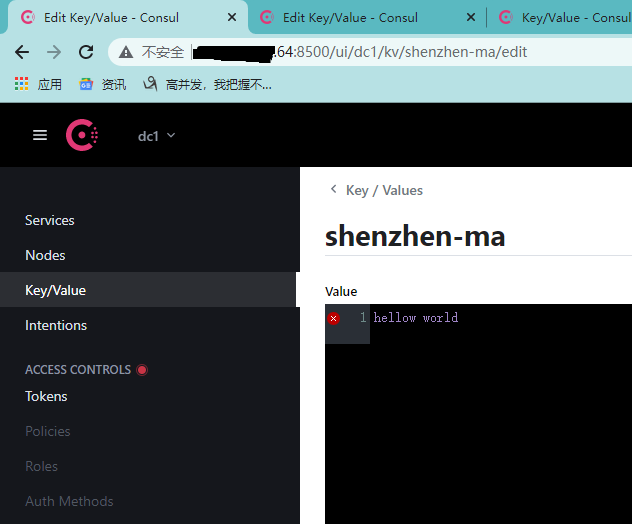
server3修改value=hellow world以后,server1查看:
C端
现在再来启动客户端:
docker run -d --restart=always --name=client1 -e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt":true}' -p 11300:8300 -p 11301:8301 -p 11301:8301/udp -p 11302:8302/udp -p 11302:8302 -p 11400:8400 -p 11500:8500 -p 11600:8600 -h client1 consul agent -bind=0.0.0.0 -retry-join=你服务器的IP -node=client1 -data-dir=/tmp/data-dir -client 0.0.0.0 -ui
想要多个客户端的话,改一下端口和名字就可以了,我这里跑了3个,如图:
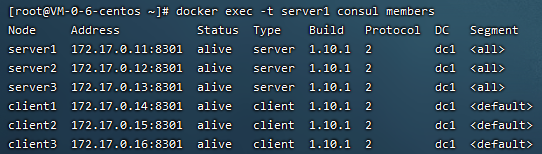
和刚才的3个S端一起,这6个都是一体的,数据都会自动同步,任意节点注册修改数据都会在其他节点看到。
入口统一
我把集群弄好了,但是现在的集群还没有发挥作用。前几篇文章有讲服务注册,consul注册的时候需要一个固定的地址。集群有很多节点,每一个IP端口都不一样,如果下端只和其中一个节点产生联系,万一这个节点挂了,下端就失去consul的支持了,集群的作用也没发挥出来。所以给下端一个统一的入口是必要的,这里用Nginx的Upstream模式实现,修改下配置文件就行了:
upstream myconsul {
server 42.XX.XX.64:8500;
server 42.XX.XX.64:9500;
server 42.XX.XX.64:10500;
server 42.XX.XX.64:11500;
server 42.XX.XX.64:12500;
server 42.XX.XX.64:13500;
}
server{
listen 88;
server_name localhost;
location / {
proxy_pass http://myconsul;
}
}
配置文件修改好重启一下,进去看看能不能访问:

OK,下端注册服务时,统一用这个地址就可以了。跑两个试试(下端代码就不发了,前面几篇文章有):
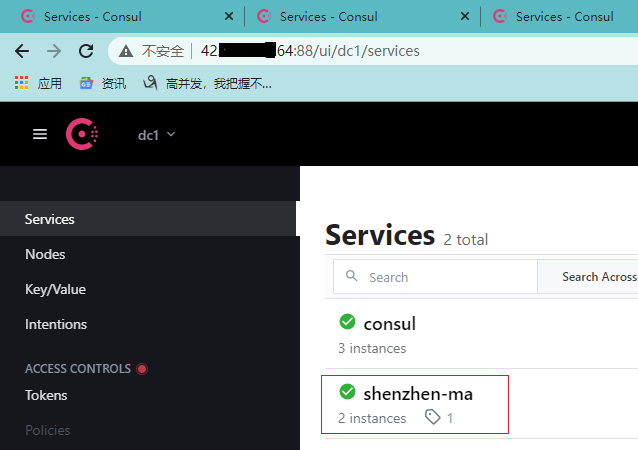
成功了!切换到其他consul节点看下能否正确展示:
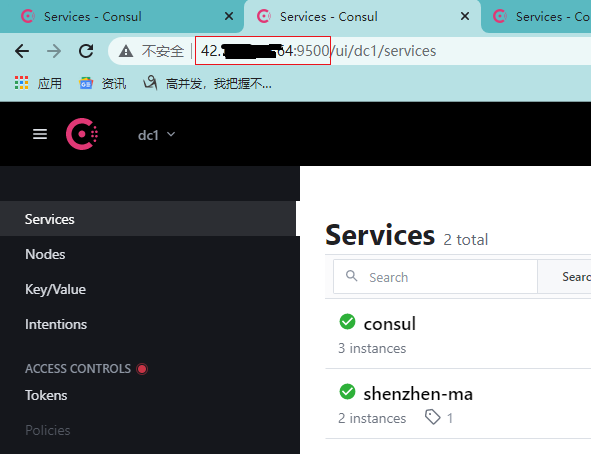
很显然是OK的。基于我之前为服务配置的健康检查,最后来看下服务状态变化会不会同步给其他节点,比如我停掉其中一个:
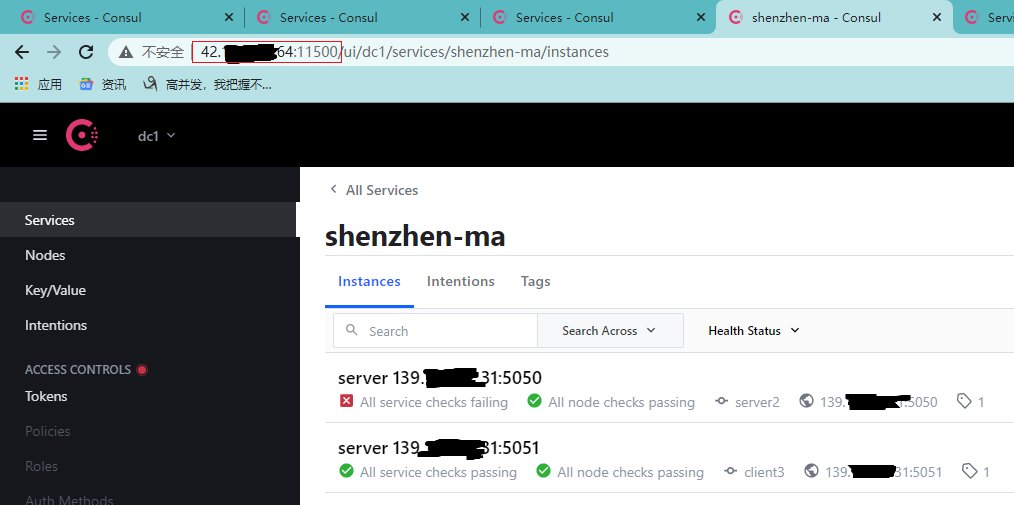
变更的状态也很快同步到了其他节点。到这里为止,consul的集群就已经实现了,东西还是有点多的,如果实践遇到麻烦,欢迎讨论。

