论文原文:https://arxiv.org/pdf/1608.03981.pdf
笔记参考:【图像去噪】DnCNN论文详解
文章贡献:
- 针对高斯去噪提出了以一个端对端的可训练的深度神经网络。与现有的基于深度神经网络的直接估计潜在的干净图像的方法不同,该网络采用残差学习策略从噪声观测中去除潜在的干净图像。
- 文章发现,残差学习和批处理归一化对CNN的学习有很大的好处,它们不仅可以加快训练速度,而且可以提高去噪性能。对于具有一定噪声水平的高斯去噪,DnCNN在定量度量和视觉质量方面都优于最先进的方法。
- DnCNN可以很容易地扩展到处理一般的图像去噪任务。可以通过训练单一的DnCNN模型来进行高斯盲去噪,并在特定的噪声水平下取得比其他方法更好的性能。此外,它有希望解决三个常见的图像去噪任务,即盲高斯去噪,SISR(超分辨率)和JPEG去块。
网络:
在网络架构设计上,对VGG进行修改,使其适合图像去噪,并根据目前去噪方法中使用的有效patch大小来设置网络深度。
在模型学习中,采用了残差学习公式,并将其与批处理归一化相结合,实现了快速训练,提高了去噪性能。
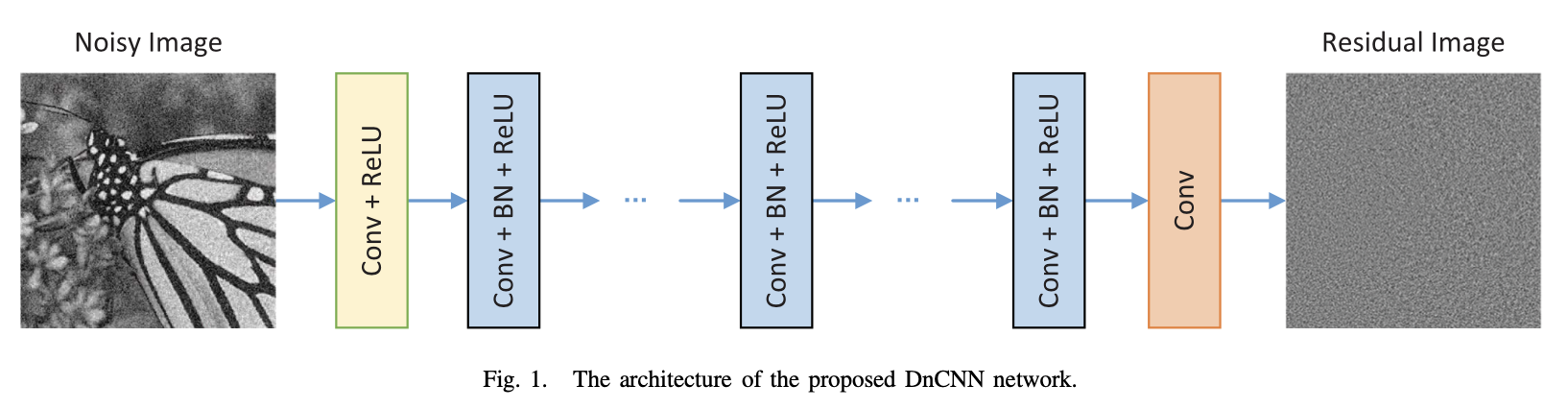
模型:
class DnCNN(nn.Module): def __init__(self, channels, num_of_layers=17): super(DnCNN, self).__init__() kernel_size = 3 padding = 1 features = 64 layers = [] layers.append(nn.Conv2d(in_channels=channels, out_channels=features, kernel_size=kernel_size, padding=padding, bias=False)) layers.append(nn.ReLU(inplace=True)) for _ in range(num_of_layers-2): layers.append(nn.Conv2d(in_channels=features, out_channels=features, kernel_size=kernel_size, padding=padding, bias=False)) layers.append(nn.BatchNorm2d(features)) layers.append(nn.ReLU(inplace=True)) layers.append(nn.Conv2d(in_channels=features, out_channels=channels, kernel_size=kernel_size, padding=padding, bias=False)) self.dncnn = nn.Sequential(*layers) def forward(self, x): out = self.dncnn(x) return out
第一部分:Conv(3 * 3 * c * 64)+ReLu (c代表图片通道数)
第二部分:Conv(3 * 3 * 64 * 64)+BN(batch normalization)+ReLu
第三部分:Conv(3 * 3 * 64)
每一层都zero padding,使得每一层的输入、输出尺寸保持一致。以此防止产生人工边界(boundary artifacts)。第二部分每一层在卷积与reLU之间都加了批量标准化(batch normalization、BN)。
批量标准化batch normalization:
SGD(随机梯度下降法)广泛应用于CNN的训练方法中,但是训练的性能却很大程度受内部协变量移位这一问题所影响。BN就是在每一层的非线性处理之前加入标准化、缩放、移位操作来减轻内部协变量的移位。可以给训练带来更快的速度,更好的表现,使网络对初始化变量的影响没有那么大。
内部协变量移位(internal covariate shift):深层神经网络在做非线性变换前的激活输入值,随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。
批量标准化(batch normalization):就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,即把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,所以输入的小变化才就会导致损失函数有较大的变化,意思就是让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
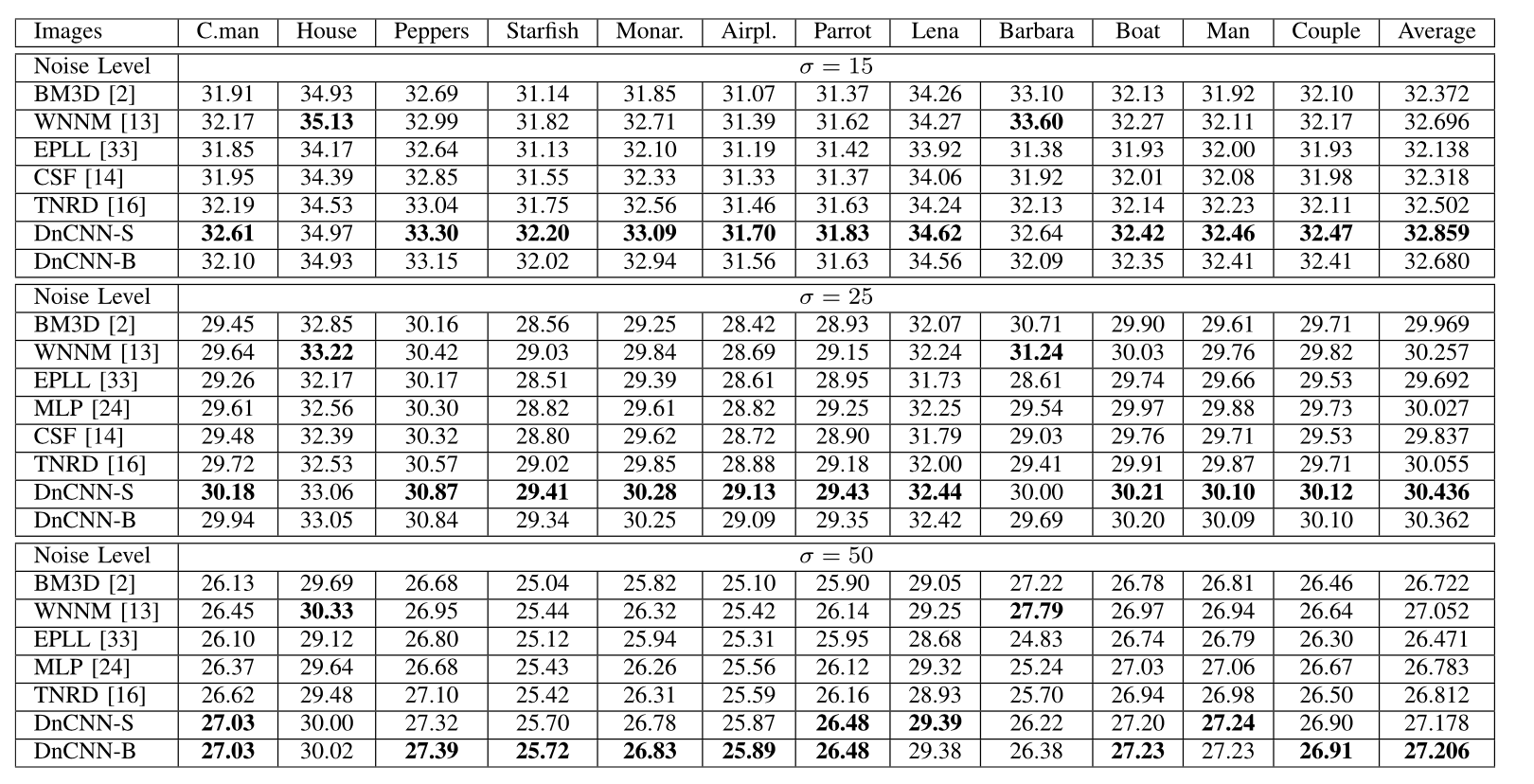
结果: