好,首先我们根据这张集合体系图来慢慢分析。大到顶层接口,小到具体实现类。
首先,我想说为什么要用集合?简单的说:数组长度固定,且是同种数据类型。不能满足需求。所以我们引入集合(容器)来存储任意数据类型的可变大小的数据。
来了解下数组:
数组有静态、动态之分。但是其长度都是固定的,并且其内部只能存储同一种数据类型的数据。除非是Object类型的数组,它可以存储任意类型的数据。
数组的存储方式?数据存储结构分为顺序存储、链接存储、索引存储、散列存储。
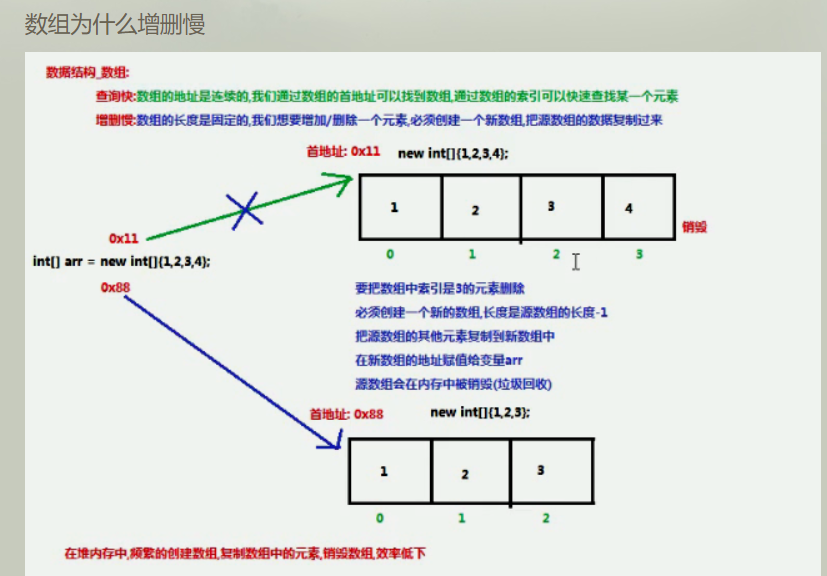
数组是基于顺序存储方式。数组就是在内存中开辟一块连续的、大小相同的空间,用来存储数据。
数组查询速度快:因为基于索引查询。但是增删慢。为什么增删慢呢?因为数组的元素是连续的(索引是连续的)。如果要增删元素时,会发生索引位置的移动,且是重新创建了一个新数组。所以增删慢。

java集合体系结构中主要按两种接口分类:
1.Collection
2. Map
//查看jdk1.8源码
首先分析Collection,它是一个接口,同时它继承了顶级Iterable接口,为什么要继承这个接口呢?主要是使用接口中特有
方法,可以通过iterator迭代器遍历整个集合。在jdk1.8中,Iterable接口中有forEach方法、spliterator()方法。
同时,List接口继承了Collection接口.List是存取有序可重复且有索引的,同时允许元素为null。这里所说的有序是元素的存取顺序。而Set是无序不可重复无索引。但是Set的无序我们一般是指HashSet,因为它不能保证元素的存取顺序和自然排序。而LinkedHashSet:保证元素的添加顺序。TreeSet:保证元素的自然排序。可能知道的人很容易理解,不知道的人不理解就很难记忆。通过代码,也可以清楚看到是否有序,是否重复的特性。由于篇幅,演示代码省略。接下来我们逐一分析接口下的实现类都有什么特性?
List接口下的实现类
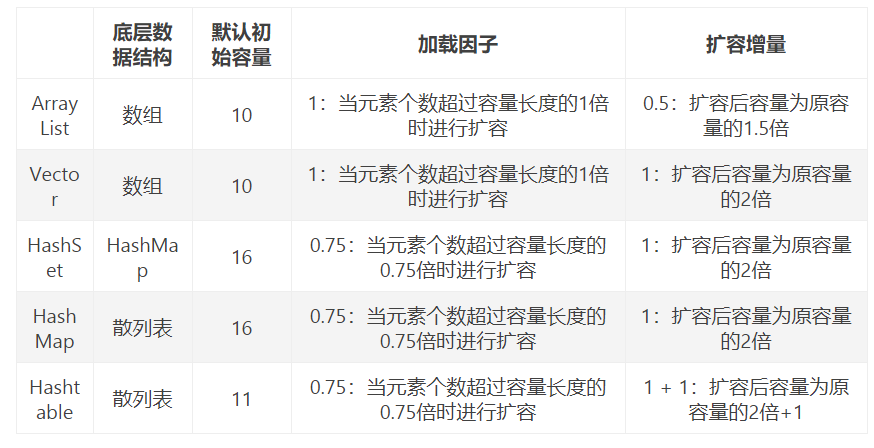
ArrayList:底层是使用了Object数组实现的,查询速度快,增删慢。非同步的(线程不安全类),因此效率高。数组默认容量是10,当长度不够时自动增长0.5倍,也就是原数组的1.5倍。
使用场景:频繁查询时,增删较少时。
LinkedList:底层结构是双向链表,不需要在内存中开辟一段连续的内存空间。而是每个元素有一个下一元素地址]这样的内存结构。增加时只需要改变两个节点之间的引用关系即可。来组成一个新的节点。删除时只要删除两个节点的引用即可。而查询时,必须从头部开始查询。所以效率慢。查询慢,增删快。同时它是非同步的(线程不安全类)。https://blog.csdn.net/qq_35120695/article/details/56573865
Vector: 底层也是基于动态数组实现。线程安全类,但是效率低,基本不使用。
Set接口下的实现类
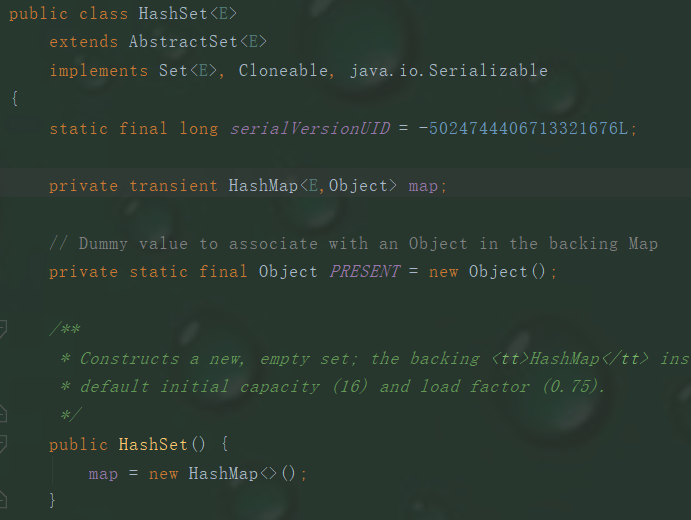
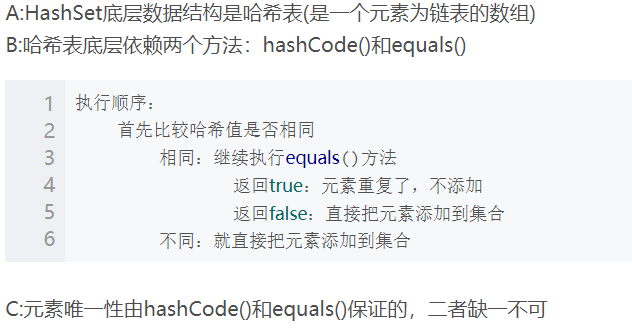
HashSet:底层数据结构是哈希表,而jdk1.8中哈希表底层采用数组+链表+红黑树。其实现set接口,底层使用HashMap来保存所有元素。特点:无序不可重复。线程不安全。其是如何保证去重原理的呢?
从源码中我们可以看出:
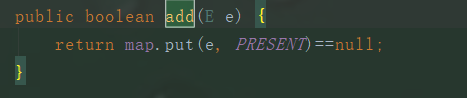
它的add()方法实际上调用的是HashMap中的put()方法,把要添加进HashSet中的元素当做key存入,而value则是一个固定值:一个Object类对象。
先用hashCode()方法获得传入元素的哈希值,在集合中查找是否包含哈希值相同的元素,如果相同,则继续进行比较它们地址值,一般地址值都是不相同的,所以最后会用equals()方法比较对象内的属性值。
比较结果全为false就存入,如果比较结果有true则不存。
TreeSet:底层使用TreeMap来进行存储,而TreeMap底层基于红黑树数据结构,规则是左小右大。有序不可重复。有序指对元素进行自然排序。同时支持定制排序。线程不安全类。
红黑树规则补充:
红黑树:也可以叫二叉树
规则:左节点小于等于父节点,右节点大于父节点。
为了保证树的左右平衡,红黑树采用节点标色的方式,将节点标记为红色或黑色。根节点(没有父节点)为黑色。
每个叶子节点都是null值且是黑色。
如果一个节点为红色,则它的子节点必须是黑色
新插入节点的颜色为红色
左旋,右旋、颜色反转操作保持树平衡
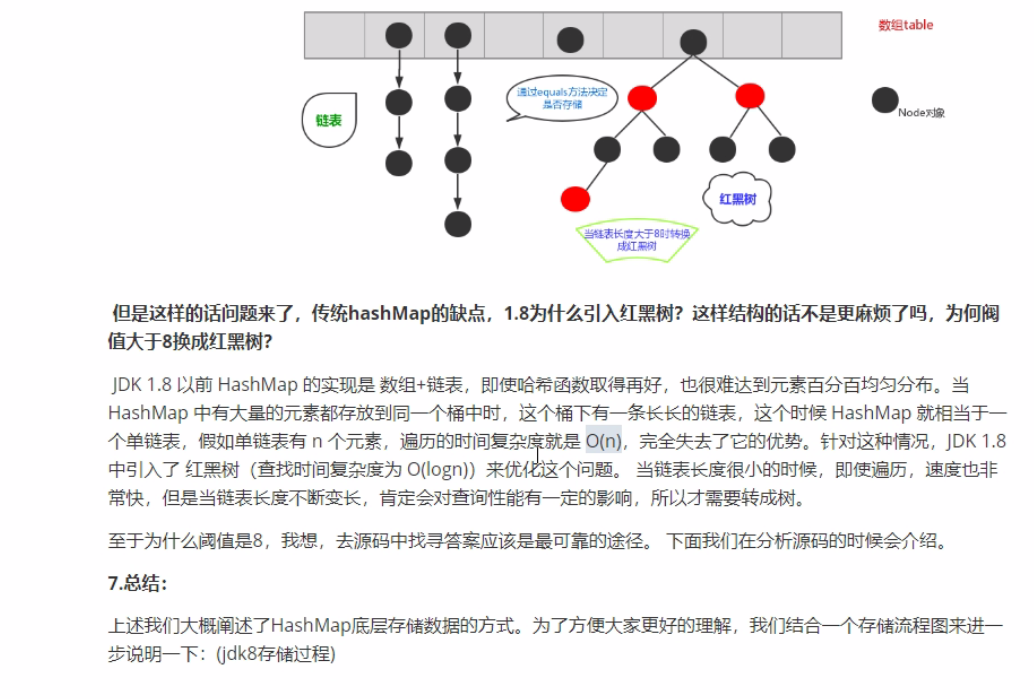
jdk1.8中加入红黑树目的就是解决链表的查询效率低的问题。
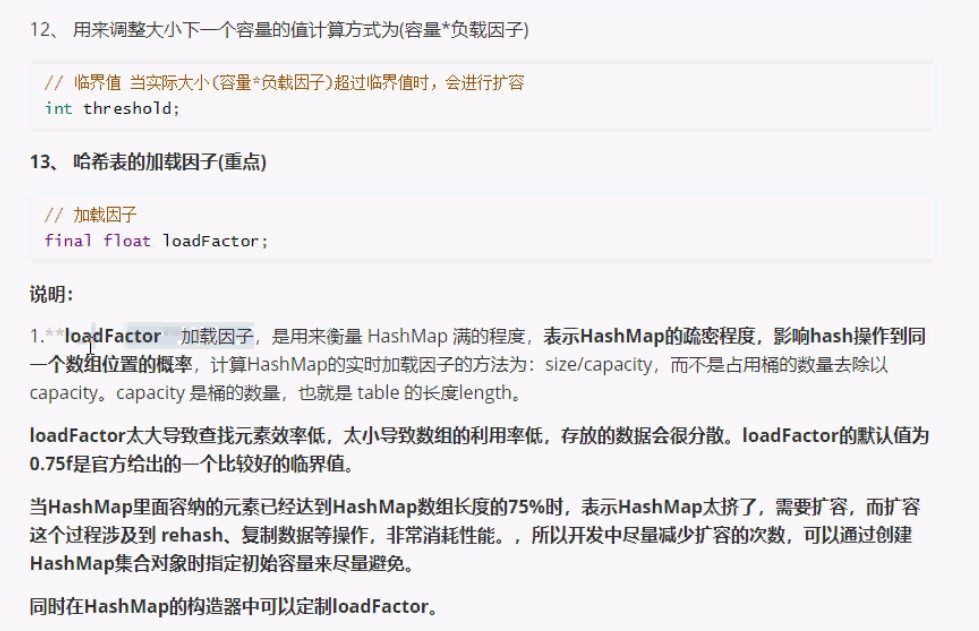
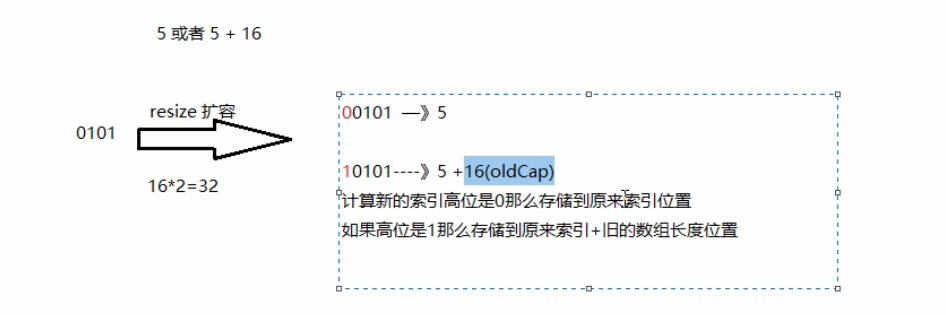
HashMap默认容量是16,源码显示1<<4,就是1向左移动4为,即为16.
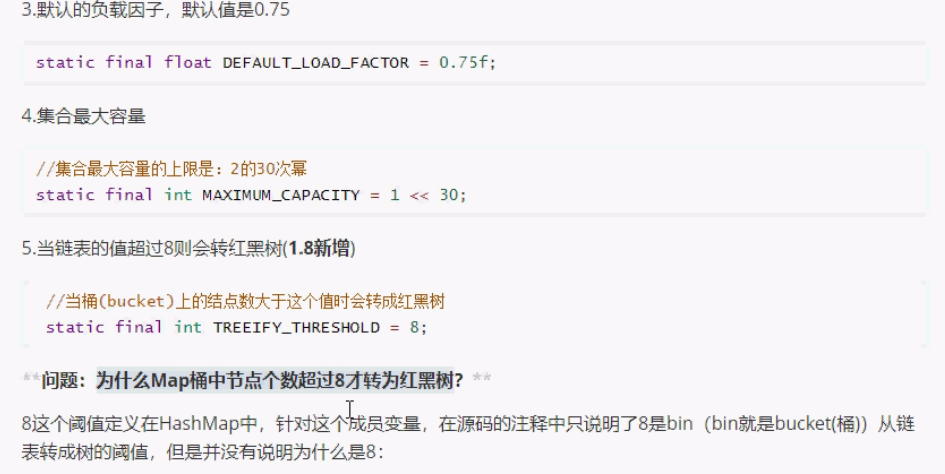
当链表长度>8时,则将链表转为红黑树。
当红黑树内数量<6时,将红黑树转为链表
TreeSet注意事项:
1、往TreeSet添加元素的时候,如果元素本身具备了自然顺序的特性,那么就按照元素本身的自然顺序特性进行存储;
2、如果元素本身不具备自然 顺序的特性,那么该元素所属的类必须要实现Comparable接口,并重写compareTo()
方法,把元素的比较规则定义在compareTo()方法上;
3、如果比较元素的时候,compareTo()方法返回的是0,那么该元素就被视为重复元素,不允许添加;
LinkedHashSet:底层是哈希表和链表。其继承了HashSet,实现set接口。
由链表保证元素的有序(存取顺序)。由哈希表保证元素的唯一(不重复)。内部是通过 LinkedHashMap 来实现的。
Map接口下的实现类
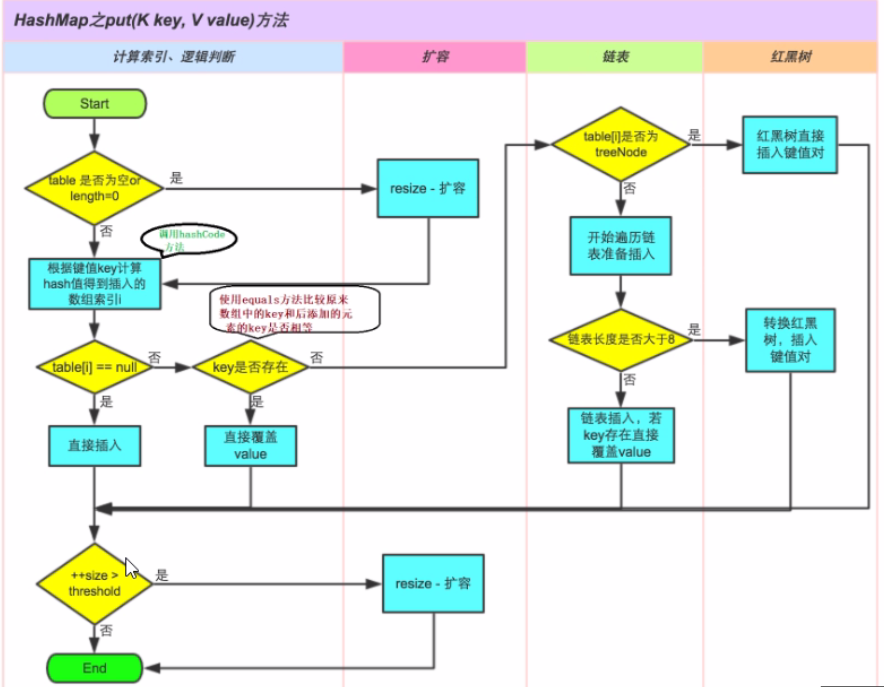
HashMap:首先看源码分析,它继承了AbstractMap类,基于哈希表的Map接口实现。是以key-value存储形式。主要用来存放键值对。它是非同步(线程不安全)的。它的key-value都可以为null,且映射是无序的。
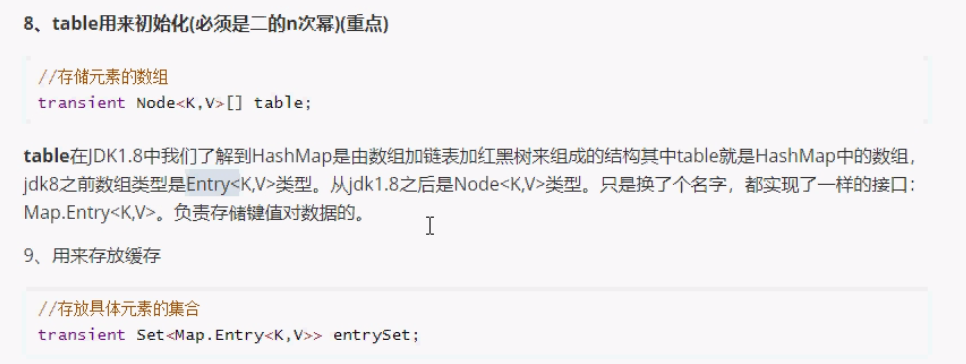
jdk1.8之前,HashMap由数组+链表组成。数组是主体,链表则是主要为了解决哈希冲突(两个对象通过hashcode方法计算的哈希码值一致导致数组索引值相同)而存在的。
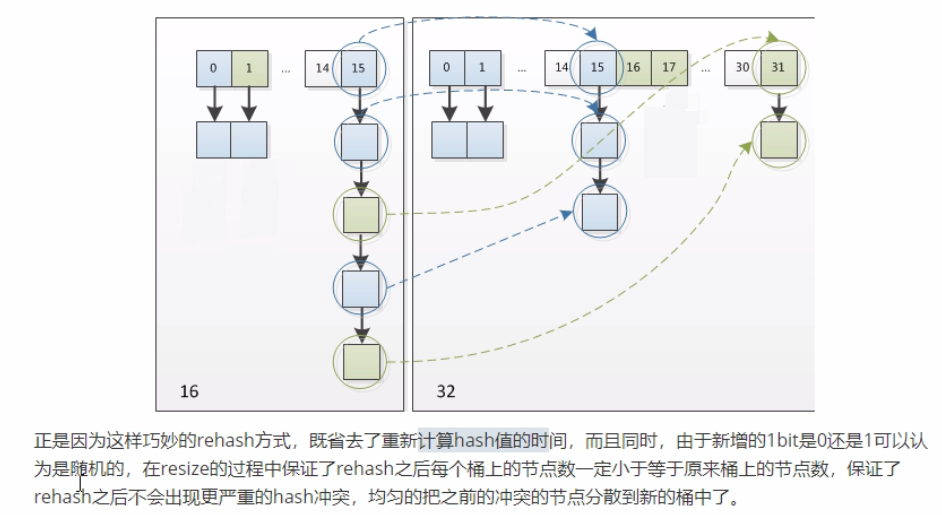
在jdk1.8之后,当链表长度大于阈值(红黑树的边界值默认为8)并且当前数组长度大于64时,此时所有数据改为采用红黑树存储。
补充:将链表转为红黑树前会进行判断,即使阈值大于8,但是数组长度小于64,此时并不会将链表转为红黑树,而是进行数组扩容。这样做的目的是因为数组长度比较小,尽量避开红黑树结构。因为这种情况下使用红黑树结构反而效率低,因为红黑树需要通过左旋、右旋、变色等操作来保持平衡。同时数组长度小于64时,查询时间更快些。

特点:
- 存取无序
- 键值位置都可以为null,但是键位置只能是一个null且键唯一。
- jdk1.8之前数据结构是数组+链表。jdk1.8之后是:数组+链表+红黑树。
- 当链表长度大于8,并且数组长度大于64时,将链表转为红黑树,目的是提高查询效率
Hashmap的存储过程如下图:



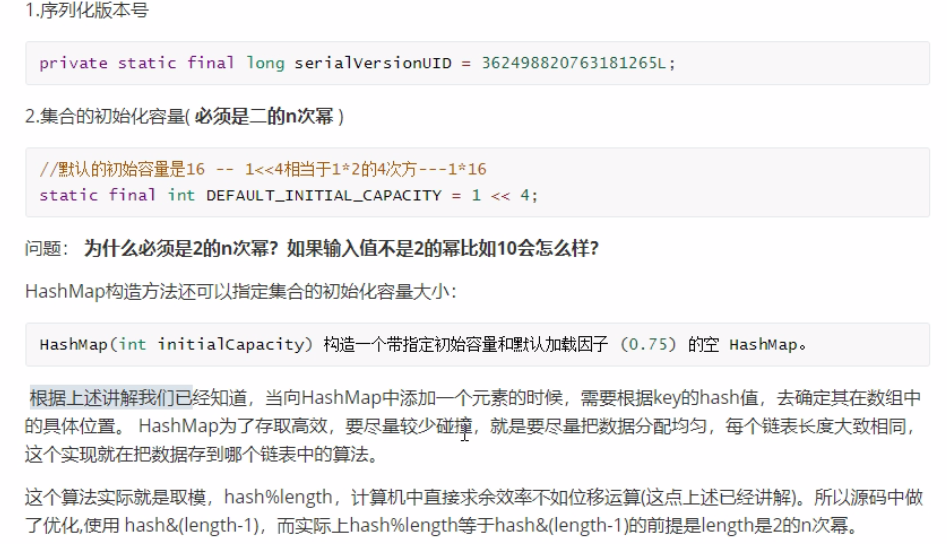



如果创建集合时,我们用有参构造,指定初始容量不是2的n次幂情况分析
查看底层算法如下:

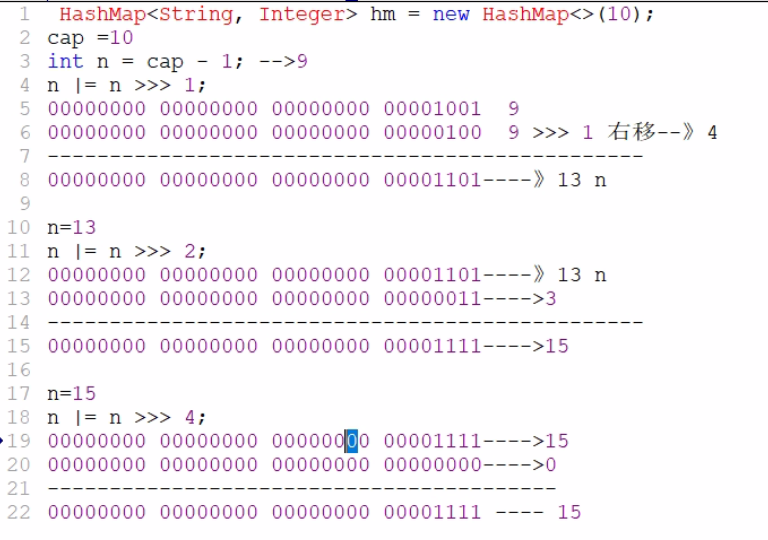
如果指定初始容量不是2的n次幂,底层会进行一顿右移和或运算。











TreeMap:
通过红黑树实现,默认情况下通过Key值的自然顺序进行排序,也可以通过比较器排序。非线程安全类
https://www.cnblogs.com/LiaHon/p/11221634.html
HashTable:


HashMap可以允许存在一个为null的key和任意个为null的value,但是HashTable中的key和value都不允许为null.而当HashTable遇到null时,他会直接抛出NullPointerException异常信息。
Hashtable的方法是同步(线程安全,效率低)的,而HashMap的方法不是。所以有人一般都建议如果是涉及到多线程同步时采用HashTable,没有涉及就采用HashMap。
HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
https://blog.csdn.net/varyall/article/details/80992123
CurrentHashMap
https://www.cnblogs.com/supertang/p/4149786.html
扩容图示: