结对信息
与黄金菇结对博客传送门:https://www.cnblogs.com/yizhigu/p/9750860.html
本作业github地址: https://github.com/MukyoCheung/pair-project具体分工
小白主要是数据的收集包括爬去要求的论文列表以及后面补充的论文列表(尽量),我主要是负责第二部分编码完成任务
psp表格如下:
PSP3 Personal Software Process Stages 预估耗时(分钟)20 实际耗时(分钟) Planning 计划 60 120 · Estimate · 估计这个任务需要多少时间 20 10 Development 开发 300 480 · Analysis · 需求分析 (包括学习新技术) · Design Spec · 生成设计文档 160 120 · Design Review · 设计复审 30 20 · Coding Standard · 代码规范 (为目前的开发制定合适的规范) · Design · 具体设计 · Coding · 具体编码 1500 900 · Code Review · 代码复审 20 10 · Test · 测试(自我测试,修改代码,提交修改) 120 300 Reporting 报告 150 180 · Test Repor · 测试报告 20 10 · Size Measurement · 计算工作量 15 15 · Postmortem & Process Improvement Plan · 事后总结, 并提出过程改进计划 20 15 合计 2395
解题思路描述与设计实现说明
爬虫使用:使用Python编写,利用urllib.request以及BeautifulSoup库顺利达成。
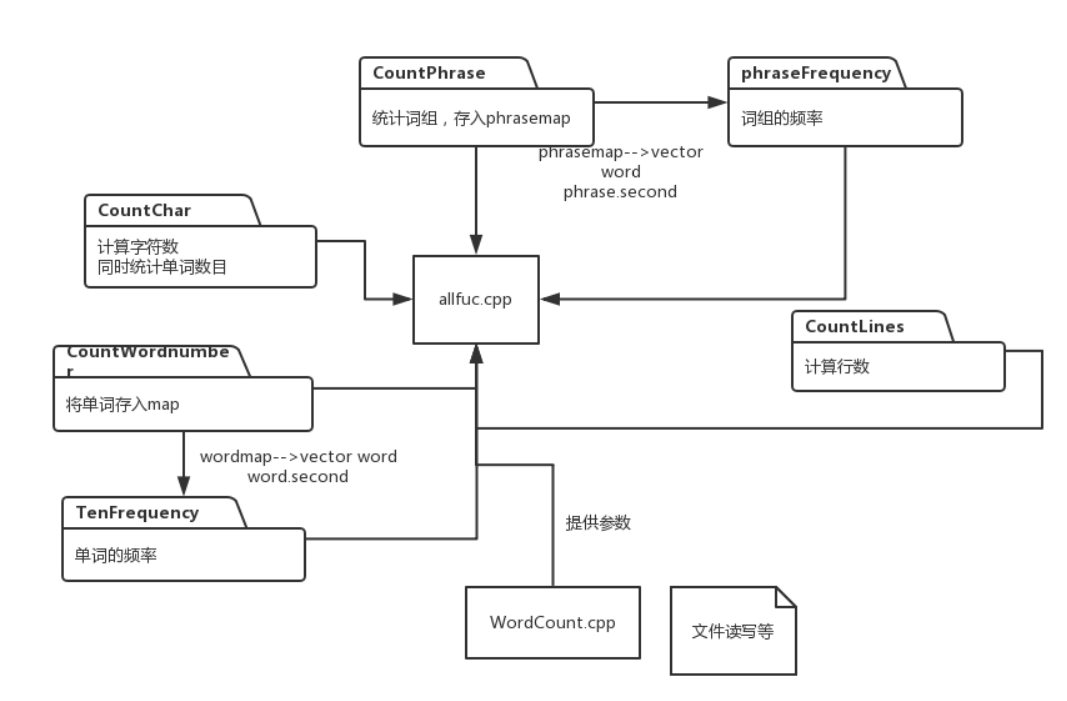
代码组织与内部实现设计
在上次词频统计代码的基础上加上了词组统计
CountChar.h 用来统计字符数
CountLines.h 统计有效行数
CountWordnumber.h 统计单词数
TenFrequency.h 输出前十的单词的频率
CountPhrase.h 统计词组数
phraseFrequency.h 将前n的词组树按照顺序存在vector中类图
说明算法的关键与关键实现部分流程图
1 字符数:按照上次的一样还是统计了所有的字符,根据题意,直接在最后减去不要求的字符数即可
2 统计有效行数:按照上次的一样,将/n /r /t排除在外,并且题目中说每篇文章标题行的换行不算
3 统计有效单词数:由于这次单词的频率可能存在加权的情况,于是我在上次代码的基础上,将title中的单词和abstract中的单词分别存在两个不一样的map中,于是只要将这两张Mao里面所有与string对应的数相加
4 统计单词的词频:根据之前已经将abstract和titile中的单词合并在不一样的map中,首先就是将两张map中的pair(可能会按一定权重)合并到一个vector中去,再按照上次的排序前n个算法
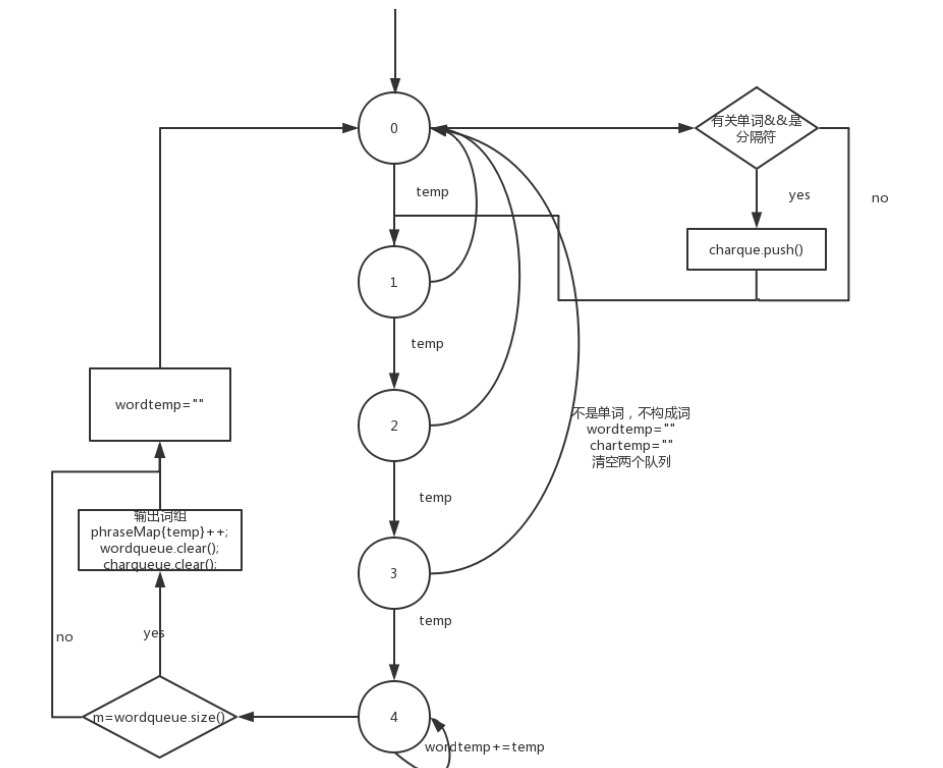
5 统计词组:在上次统计单词的基础上实现了对于词组的统计:流程图如下:
6 将词组的频率按照一定的频率输出,思路和上面的单词频率一致
关于词组统计的流程图
更新:对于最后提交代码的单词的统计,将两个map中的term合并到vector中由于某种不可知原因合并出现错误,最后迫于无奈只能改变了思路,将计算单词数和将单词及其当前对应频率分开,最后成功。关键代码展示
有关如何进行词组统计的具体实现
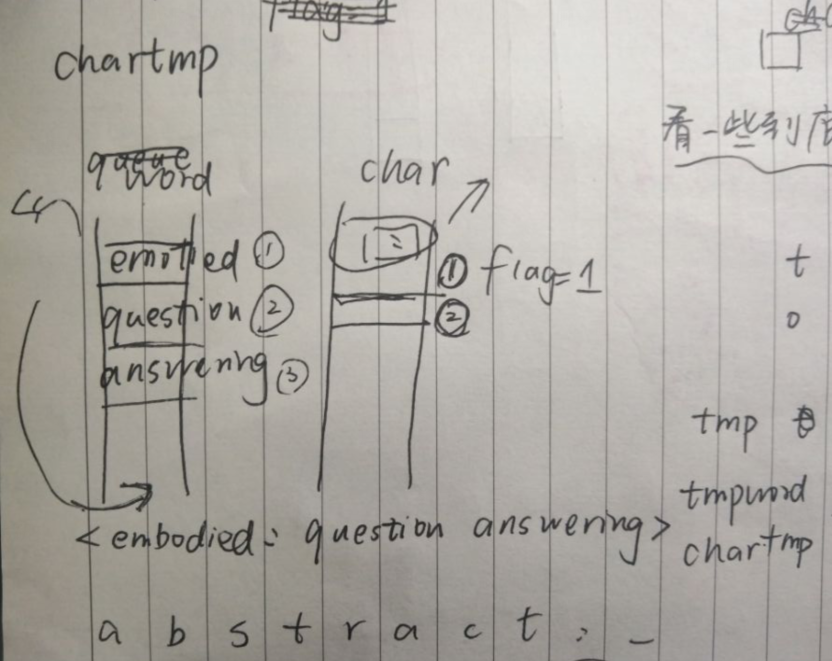
关于下列代码如何将单词连接分隔符变成词组可见下面抽象图
emmmm(辣眼睛)
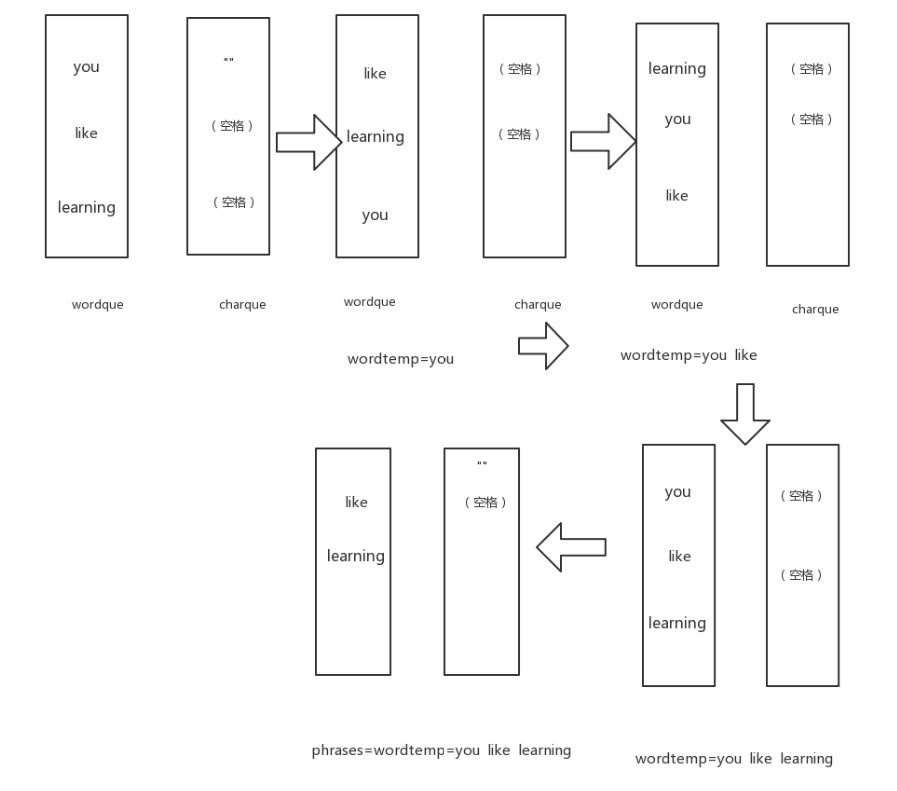
还是下面的图吧(虽然也不咋地)
while (getline(ifs, str)) //从原网页可以观察到,title是一行,abstract是一行,
{
lines++;
if (lines % 5 == 2) //title行
{
//cout << "lines % 5 == 2这一行是:" << str << endl;
int state = 0;
int flag = 0;
string wordtemp, chartmp;
for (int i = 0; i < str.length(); i++)
{
char charTemp = str[i];
//if (charTemp == ' ') cout << "lines % 5 == 2空格的当前位置为:" << i << endl;
/*----------------------------对于单词的操作----------------*/
if (charTemp >= 65 && charTemp <= 90)
charTemp = charTemp + 32; //大写转化为小写
switch (state)
{
case 0:
if (charTemp >= 97 && charTemp <= 122) {//字母
wordtemp = wordtemp + charTemp;
state = 1;
if (i != 0&&i!=6&&i!=7) {
charque.push(chartmp);
chartmp.clear();//清空
}
}
if ((charTemp < '0') || (charTemp > '9'&&charTemp < 97) || (charTemp > 122))//是分隔符
{
if (i != 5 && i != 6 && flag == 1) //不是标题的:并且之前要出现过单词才开始计数
chartmp = chartmp + charTemp;
}
///当遇到是数字或者字母的时候就将chartemp压栈
//碰到字母的时候才将其压栈,碰到数字的时候全部清空,在state=0的状态下,当碰到数字的时候要将两个队列清空
if ((charTemp >= '0'&&charTemp <= '9')) {
while (!wordque.empty()) wordque.pop();
while (!charque.empty()) charque.pop();
flag = 0;
chartmp.clear();
wordtemp.clear();
}
break;
case 1:
if (charTemp >= 97 && charTemp <= 122) {
wordtemp = wordtemp + charTemp;
state = 2;
}
else
{//中间发生错误就全部清空
state = 0;
flag = 0;
chartmp.clear();
wordtemp.clear();
while (!wordque.empty()) wordque.pop();
while (!charque.empty()) charque.pop();
}
break;
case 2:
if (charTemp >= 97 && charTemp <= 122) {
wordtemp = wordtemp + charTemp;
state = 3;
}
else
{
state = 0;
flag = 0;
chartmp.clear();
wordtemp.clear();
while (!wordque.empty()) wordque.pop();
while (!charque.empty()) charque.pop();
}
break;
case 3:
if (charTemp >= 97 && charTemp <= 122) {
wordtemp = wordtemp + charTemp;
state = 4;
}
else
{
state = 0;
flag = 0;
chartmp.clear();
wordtemp.clear();
while (!wordque.empty()) wordque.pop();
while (!charque.empty()) charque.pop();
}
break;
case 4:
if (charTemp >= 97 && charTemp <= 122 || (charTemp >= '0'&&charTemp <= '9')) {
wordtemp = wordtemp + charTemp;
}
else//单词结束了
{
if ((charTemp < '0') || (charTemp > '9'&&charTemp < 97) || (charTemp > 122))//是分隔符那就保存起来,并且不能是开头的单词
{
if (i != 5) {
chartmp = chartmp + charTemp;
}
}
if (wordtemp != "title"&&i != 5)//不是开头的title
{
//将单词放进queue中
wordque.push(wordtemp);
flag = 1;//有过单词
}
if (wordque.size() == m)//改队列满了,那就是词组单词了
{
string phrase;
if (charque.front() == "")
charque.pop();
//将对应的单词和词组存到词组的map中去,并且将queue首部踢掉
//queue不提供元素的随机访问,,所以只能将元素出队列再入队列?
string x, y;//用于保存临时的单词和分隔符
for (int k = 0; k < m - 1; k++) {
x = wordque.front(); //m
y = charque.front();//m-1次
phrase = phrase + x + y;
wordque.pop();
charque.pop();
wordque.push(x);
charque.push(y);
}
x = wordque.front(); //第m个单词
//y = charque.front();
phrase = phrase + x;
wordque.pop();
wordque.push(x);
//合并完之后将两个queue的首元素都去掉
wordque.pop();
charque.pop();
phraseMap[phrase]++;
//phrase = "";
}
state = 0;
wordtemp = "";
}
break;
}
//输出每轮的chartmp和wordtemp
/*cout << "当前局数是->" << i << endl;
cout << "wordtemp是->" << wordtemp <<" " << "chartemp是->" << chartmp <<"<-"<< endl;
if (!wordque.empty()) {
cout << "wordque中的首元素是" << wordque.front() << endl;
}
if (!charque.empty()) {
cout << "当前chartemp的size是" << charque.size() << endl;
cout << " charque中的元素是------->" << charque.front() << "<-------" << endl;
}*/
}
if (state == 4) {//最后结束如果还是有单词
wordque.push(wordtemp);
//并且如果还能组成词组的话
if (wordque.size() == m)//改队列满了,那就是词组单词了
{
//将对应的单词和词组存到词组的map中去,并且将queue首部踢掉
//queue不提供元素的随机访问,,所以只能将元素出队列再入队列?
string x, y;//用于保存临时的单词和分隔符
string phrase;
if (charque.front() == "")
charque.pop();
for (int k = 0; k < m - 1; k++) {
x = wordque.front(); //m
y = charque.front();//m-1次
phrase = phrase + x + y;
wordque.pop();
charque.pop();
//wordque.push(x);
//charque.push(y);
}
x = wordque.front(); //第m个单词
//y = charque.front();
phrase = phrase + x;
wordque.pop();
wordque.push(x);
phraseMap[phrase]++;
}
}
//每个abstract结束之后都将两者清空
while (!wordque.empty()) wordque.pop();
while (!charque.empty()) charque.pop();
}
附加题设计与展示
1 关于对作者国家和pdf的爬去可见txt:
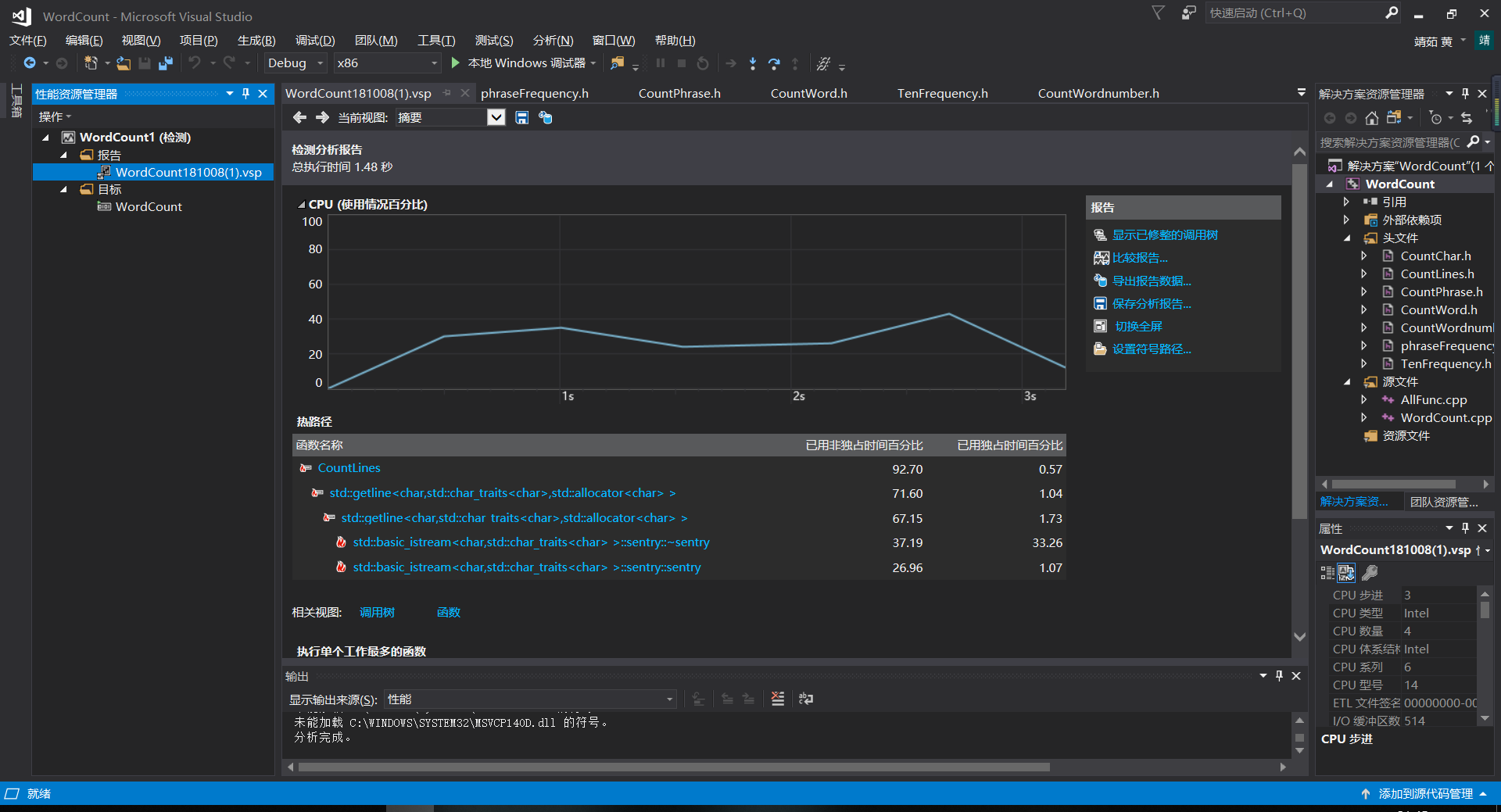
2未完性能分析与改进
性能分析图如下:
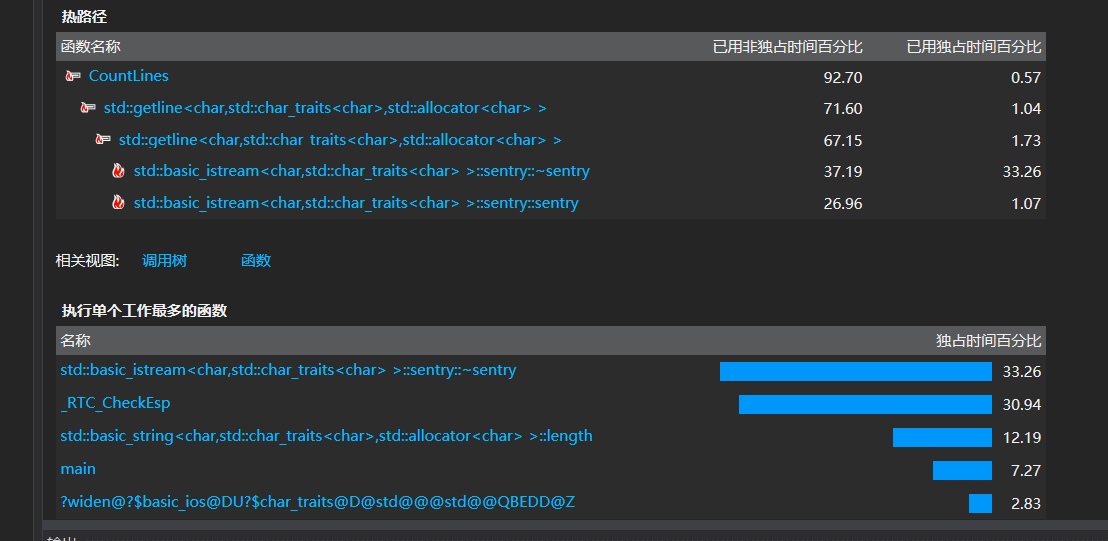
消耗最大的函数
改进:主要是对于字符的检测,由于之前有问助教测试时是拿整个爬去的论文结果去测试,那么这里对于有效行的计算其实也不并再一个字符一个字符的去判断,对于空白行这个条件也更加明晰,可以没那么严苛的判断条件得知论文的篇数之后甚至可以直接获得(算投机取巧?)
另外就是对于上一篇用正则来写判断单词好像对于c++来说掉用正则还是挺慢的,于是这次用自动机写。
还有就是对于词组的统计,尤其是后面的加权,可以不像之前统计单词那样分别先放在两个map中,再合并,因为不需要知道词组的数量,只要最后输出前n个即可,因此可以在将词组放入mapp时直接判断是否有权重单元测试
- TEST_METHOD(TestMethod1) 用于判断对于空文档会不会乱读 ---------->只要判断一下读出的文档是不是没有字符即可
- TEST_METHOD(TestMethod2) 字符以及单词数是否正确 设计了一个按照爬去列表一样的格式读取相应的字符数和单词数即可
- TEST_METHOD(TestMethod3) 判断行数 同样简单计算一下
- TEST_METHOD(TestMethod4) 判断词组个数是否正确 将所统计的存在phrasemap中的所有个数的和判断与数出来的是否一致
- TEST_METHOD(TestMethod5) 判断词频 这里只检测了出现频率最高的词组,并且分别对于权重为0为1时的最高频率的词组
- TEST_METHOD(TestMethod6) 判断单词 这里只检测了出现频率最高的单词,并且分别对于权重为0为1时的最高频率的单词

部分代码展示:
TEST_METHOD(TestMethod4)//判断词组个数是否正确
{
CountPhrase(mInputFileName1, 3, 0);//长度为3的词组没有权重
//分别检查phrasemap和phrase vector中的单词个数
int maplen = 0;
for ( map<string, int>::iterator vit = phraseMap.begin(); vit != phraseMap.end(); vit++) {
maplen = maplen + vit->second;
}
//Assert::AreEqual(maplen, phraselen);
Assert::AreEqual(5, maplen);
}
TEST_METHOD(TestMethod5)//判断词组中出现最高频率的是哪个
{
CountPhrase(mInputFileName1, 3, 0);//长度为3的词组没有权重
phraseFrequency(1);
//分别检查phrasemap和phrase vector中的单词个数
vector<pair<string, int>>::iterator vit;
string ans = phrases.begin()->first;
Assert::IsTrue(ans == "monday tuesday wednesday");
}
贴出Github的代码签入记录:
遇到的代码模块异常或结对困难及解决方法
在爬虫上:
1 运行过程中出行无法识别的字符(如/u2232等)导致中断,使用将爬取的内容重编码为utf-8方式解决。
2 重组织后的编码为列表,需要重组为BeautifulSoup对象才可快速定位。
在完成作业上:
1 在判断是在title行里和abstract行里,在还没爬下来网页之前我先看了网页源代码,发现title和abstract各是一行,并且在爬取是有格式的情况下我直接用所在行数判断属于哪里。
2 在判断组成词组的时候总是碰到了使用vector容器越界的问题,本是想世界跳过每一行的abstract和title及其字符读的,并且也没有越界,不知道为什么iterator一不留神就会报错,于是我只能每次都从第0个开始读,在里面的条件中判断,并且有的时候可能还会把自己绕进去。所以写完词组统计之后觉得自己判断条件可能更会用了2333可谓撸代码一时爽,debug火葬场。
3 还有一个就是关于string的清空问题,无论是string==""还是string=string.clear(),当push进队列的时候其顶部都将其视作一个字符,所以最后我会先判断一下,如果是""才先将其pop出来评价你的队友
值得学习的地方:对于cpp的能力比我强多了o(TヘTo),学习能力さいこう(超强),有什么问题及时沟通
需要改进的地方:懒
学习进度条
第N周 新增代码(行) 累计代码(行) 本周学习耗时(小时) 累计学习耗时(小时) 重要成长 1 120 120 25 25 1熟悉了c++有关vector,map用法 2学习了正则表达式 3学习了状态转换图和有穷自动机 2 10 130 10 35 看了有关软件的使用,原型模型以及构建之法 3 100 230 27 62 1. 初级爬虫徽章(1/1)2. 通宵徽章(1/100)3. Python入门徽章(1/1)