第十五章:Python和万维网
1:屏幕抓取——屏幕抓取是程序下载网页并且提取信息的过程
from urllib import request import re p = re.compile('<h3><a .*?><a .*? href="(.*?)">(.*?)</a>') text = request.urlopen('http://python.org/community/jobs').read() for url, name in p.findall(str(text)): print('%s (%s)' % (name, url))
上诉代码缺点:
正则表达式并不是完全可读。对更复杂的HTML代码来说,表达式会变得乱七八糟并且不可维护。而且正则表达式被HTML源代码约束,而不是取决于更抽象的结构。这就意味着网页结构中很小的改变就会导致程序的中断
解决方案:A:使用Tidy(python库)的程序和XHTML解析;B:使用Beautiful Soup库,它是专门为屏幕抓取设计;
(1) Tidy和XHTML解析:标准库中解析HTML的一般方法是基于事件的,所以需要编写像解析器一样顺序处理数据的事件处理程序。标准库模块sgmllib和htmllib可以用这种方式解析非常混乱的HTML,但如果希望提前基于文档结构(比如在第二个二级标题下的第一个项目)的数据,那么在缺少标签的情况下可能要碰碰运气了。还有一种方法:Tidy
Tidy(http:tidy.sf.net)是用来修复不规范且随意的HTML的工具。当然Tidy不能修改HTML文件的所有问题,但是它会确保文件的格式是正确的(也就是所有元素都正确嵌套),这样解析的时候就轻松很多(如果是UNIX或者Linux系统,就不需要安装Tidy库,系统很可能已经包含)。
解析从Tidy中获得的表现良好的XHTML的方法是使用标准库模块(和类)HTMLParser
使用HTMLParser:意思就是继承它,并且对handle_starttage或handle_data等事件处理方法进行覆盖。下表总结了一些相关方法,以及解析器在何时对它们进行(自动)调用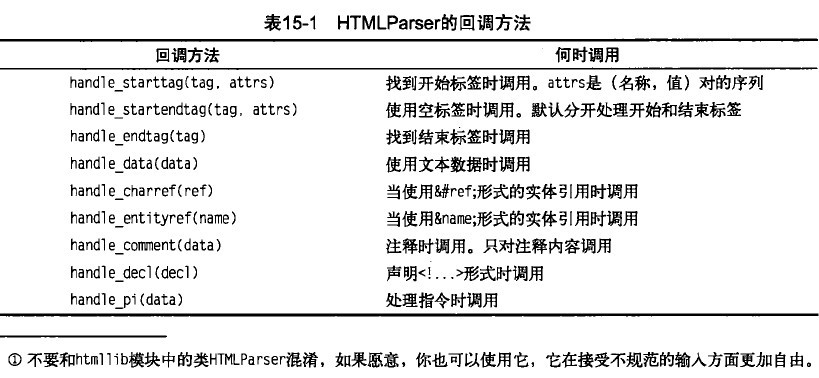
如果要进行屏幕抓取,一般不需要实现所有的解析器回调(事件处理程序),也可能不用创造整个文档的抽象表示法(比如文档树)来查找自己需要的内容。
下面的代码解决的问题同1中的代码系统,不过这次使用了HTMLParser
 View Code
View Code

from urllib import request from html.parser import HTMLParser class Scraper(HTMLParser): in_h3 = False in_link = False def handle_starttag(self,tag,attrs): attrs = dict(attrs) if tag == 'h3': self.in_h3 = True if tag == 'a' and 'href' in attrs: self.in_link = True self.chunks = [] self.url = attrs['href'] def handle_data(self,data): if self.in_link: self.chunks.append(data) def handle_endtag(self,tag): if tag == 'h3': self.in_h3 = False if tag == 'a': if self.in_h3 and self.in_link: print('%s (%s)' % (''.join(self.chunks),self.url)) self.in_link = False >>> text = request.urlopen('http://python.org/community/jobs').read() >>> parser = Scraper() >>> parser.feed(text) >>> parser.close()
这里没有使用Tidy,因为网页中的HTML已经足够规范。而且使用了一些布尔状态变量(特性)以追踪是否已经位于h3元素和链接内。在事件处理程序中检查并且更新这些变量。handle_starttag的attrs参数是由(键,值)元组组成的列表,所以使用dict函数将它们转化为字典,易于管理。handle_data方法(以及chunks特性)使用了在处理HTML和XML这类结构化标记的基于事件的解析工作时常见的技术。假定只调用handle_data就能获得所有需要的文本,而是假定会通过多次调用函数获得多个文本块。这样做的原因有几个:忽略了缓冲、字符实体和标记等——只需确保获得所有文本。然后在准备输出结果时(使用handle_endtag方法),只是将所有的文本块联结在了一起。
可以让文本调用feed方法以运行这个解析器,然后再调用close方法
(2) Beautiful Soup——小模块,用来解析和检查经常在网上看到的那类乱七八糟而且不规范的HTML
下载安装:下载BeautifulSoup.py文件,然后将它放置在Python路径中(如Python安装文件夹里面的site-packages目录)
sudo easy_install beautifulsoup4
View Code
#from urllib import ulropen #from BeautifulSoup import BeautifulSoup #上面是Python2.x的写法 from urllib import request from bs4 import BeautifulSoup text = request.urlopen('http://python.org/community/jobs').read() soup = BeautifulSoup(text) jobs = set() for header in soup('h1'): links = header('a','reference') if not links:continue link = links[0] jobs.add('%s (%s)' % (link.string, link['href'])) print('\n'.join(sorted(jobs, key=lambda s: s.lower())))
View Code
#from urllib import ulropen #from BeautifulSoup import BeautifulSoup #上面是Python2.x的写法 from urllib import request from bs4 import BeautifulSoup text = request.urlopen('http://python.org/community/jobs').read() soup = BeautifulSoup(text) #print(soup) jobs = set() #调用soup('h1')获得所有h1元素.然后进行迭代,依次将header变量绑定到每个元素上面 #并且调用header('a','reference')获取reference类(这里是CSS中的类)的a的子元素列表 for header in soup('h1'): #print(header) links = header('a','reference') #print(links) if not links:continue link = links[0] jobs.add('%s (%s)' % (link.string, link['href'])) print('\n'.join(sorted(jobs, key=lambda s: s.lower())))
如果针对RSS feed进行分析,可以使用另外一个和BeautifulSoup相关的工具,叫做Scrape'N'Feed
2:使用CGI创建动态网页——上面讨论的是客户端技术,现在来看看服务器端。本节将介绍基本的万维网程序设计计算:CGI(Common Gateway Interface,通用网关接口)。CGI是网络服务器可以将查询(一般来说是通过Web表单)传递到专门的程序(比如说Python程序)中并且在网页上显示结果的标准机制。它是创建万维网应用程序而不用编写特殊用途的应用服务器的简单方法。
Python CGI程序设计的关键工具是cgi模块。cgitb是另外一个在CGI脚本开发过程中的有用模块。使CGI脚本可通过网络访问(运行)之前,需要将它们放到网络服务器可以访问的地方,并且加入 pound bang 行,设置合适的文件许可
1)第一步:准备网络服务器
假设可以访问网络服务器——换句话说就是可以在网络上放置文件。一般来说,可以把网页、图片等放在特殊的目录中(UNIX内一般称为public_html)。CGI程序也应该放在通过网络可以访问的目录中。并且必须将它们标识为CGI脚本,这样网络服务器就不会将普通源代码作为网页处理。有两种方法可实现这个功能:
A:将脚本放在叫做cgi-bin的子目录中
B:把脚本文件扩展名改为.cgi
2)第二步:加入Pound Bang行
当把脚本放在正确位置(可能将其改为特定的文件扩展名)后,需要在脚本的开始处增加pound bang行。用它作为不用显式地执行Python解释器而运行脚本的方法。一般来说,这么做只是为了方便,但是对于CGI脚本来说就至关重要——没有这行的话,网络服务器就不知道如何执行脚本(脚本可以用其他的程序来写,如Perl或Ruby)。只要把下面这行加到脚本开始处(一定要是第一行)就可以了:
#!/usr/bin/env python
如果不能正常工作,需要查看python可执行文件的确切位置,并像下面这样在这行内使用全路径:
#!/usr/bin/python
在windows系统中,可以使用Python二进制版本的全路径,如:
#!C:\Python33\python.exe
3)第三步:设置文件许可
要确保每个人都可以读取和执行脚本文件(否则服务器就没法运行它了),但是还要确保只有你可以写入(这样就没有人可以修改脚本了)
提示:有时候,如果在Windows中编辑脚本文件,而将它存储在UNIX磁盘服务器上时(如通过Samba或者FTP访问文件),文件许可有可能在对文件进行更改后被搞乱了,所以在脚本无法执行时,请确保文件许可是正确的
修改文件许可(或者文件模式)的UNIX命令是chmod,如:chmod 755 somescript.cgi
一般来说不允许CGI脚本修改计算机上的任何文件。如果想要它修改文件,必须显式地给它设置相应的许可。这时有两个选择,如果有root(系统管理员)特权的话,那么可以为你的脚本创建一个用户账户,改变想要修改的文件的所有权。如果没有root权限,则可以设置文件许可,这样系统上的所有用户(包括网络服务器用来运行CGI脚本的用户)都被允许写文件:
chmod 666 editable_file.txt
注意:使用666文件模式可能会导致潜在的安全风险
4) CGI安全风险
如果允许CGI脚本写服务器上的文件,那么除非非常小心的编写代码,否则可能会造成数据的损毁。同样,如果将用户提供的数据看做Python代码(比如用exec或者eval),或者shell命令(比如使用os.system或者使用subprocess模块)运行,也就承担了运行任意代码的风险,这是个很大的(极大)的安全问题
5) 简单的CGI脚本
View Code
#!/usr/bin/env python print('Content-type: text/plain') print() #打印空行,以结束首部 print('Hello,world!')
6)使用cgitb调试
7)使用cgi模块
目前为止,程序只能产生输出,而不能接受任何形式的输入。输入是通过HTML表单提供给CGI脚本的键值对,或称字段。可使用cgi模块的FieldStorage类从CGI脚本中获取这些字段。当创建FieldStorage实例时(应该只创建一个),它会从请求中获取输入变量(或者字段),然后通过类字典接口将它们提供给程序。FieldStorage的值可以通过普通的键查找方式访问,但是因为一些技术原因(有关文件上传的),FieldStorage的元素并不是真正所要的值。比如,如果知道请求中包括名为name的值,就不应该像下面这么做:
form = cgi.FieldStorage()
name = form['name']
而应该这样做:
form = cgi.FieldStorage()
name = form['name'].value
获取值的简单方式就是用getvalue方法,它类似于字典的get方法,但它会返回项目的value特性的值:
name = form.getvalue('name','Unknown') #这里提供了一个默认值(Unknown),如果不提供,默认为None
View Code
#!usr/bin/env python import cgi form = cgi.FieldStorage() name = form.getvalue('name','world') print('Content-type: text/plain') print() print('Hello, %s!' % name)
8)简单的表单
View Code
#!/usr/bin/env python import cgi form = cgi.FieldStorage() name = form.getvalue('name','world') print ("""Content-type:text/html <html> <head> <title>Greeting Page</title> </head> <body> <h1>Hello,%s!</h1> <form action='simple3.cgi'> Change name <input type='text' name='name' /> <input type='submit' /> </form> </body> </html> """ % name )
3:更进一步:mod_python
mod_python是Apache网络服务器的扩展(模块),可以从mod_python的网站获取。它可以让Python解释器直接成为Apache的一部分。最重要的是它提供了在Python中编写Apache处理程序的功能,和使用C语言不同,它是标准的。使用mod_python处理程序框架可以访问丰富的API,深入Apache内核等等。
除了基本功能外,它还带有用于Web开发的处理程序:
A:CGI处理程序,允许使用mod_python解释器允许CGI脚本,执行速度会有相当大的提高
B:PSP处理程序,允许用HTML以及Python代码混合编程创建可执行网页,或者Python服务器页面(Python Server Page)
C:发布处理程序(Publisher Handler),允许使用URL调用Python函数
1)安装mod_python
A:在UNIX上安装(在Mac OS X系统上可以使用MacPorts安装mod_python):
首先下载mod_python源代码,然后解压缩,进入目录。接着允许mod_python的configure脚本:
$ ./configure --with-apxs=/usr/local/apache/bin/apxs
如果apxs不在这个位置,那么修改apxs程序的路径,配置完成后编译所有的文件:make
编译好了就可以安装了: make install
B:在windows下安装
C:配置Apache——在httpd.conf或者apache.conf文件中,增加:
#UNIX
LoadModule python_module libexec/mod_python.so
#Windows
LoadModule python_module modules/mod_python.so
3)PSP——只要把下面的代码放在.htaccess文件中即可设置Apache支持PSP页面
AddHandler mod_python .psp
PythonHandler mod_python.psp
4)发布——
4:网络应用程序框架
CGI机制和mod_python工具包是进行网络应用程序开发的非常基础的工具。如果希望开发更复杂的系统,则要使用网络应用程序框架:
5:Web服务:正确分析
Web服务使用HTTP(Web协议)作为底层协议,上面则是更多基于内容的协议,比如使用XML对请求和响应编码
对于今天的WebService开发,我们至少有两种选择:SOAP/WSDL/UDDI系列的; REST风格架构系列的
1)RSS:富站点摘要(Rich Site Summary)、RDF站点摘要或简易信息聚合
2)使用XML-RPC进行远程过程调用(PRC与REST)
3)SOAP:一种使用XML和HTTP作为底层技术的信息交换协议。像XML-RPC一样,也支持远程过程调用
小结
屏幕抓取:BeautifulSoup
CGI:通用网关接口是通过运行服务器并且同程序进行通信的方式创建动态网页的方法。CGI脚本通常从HTML表单调用
mod_python:mod_python处理程序框架让python中编写Apache处理程序变为可能。它有3个有用的标准处理程序:CGI处理程序、PSP处理程序、发布处理程序
Web应用程序框架
Web服务
第十六章:测试
1:先测试,后编码——对程序的各个部分建立测试也是非常重要的(这也称为单元测试)。测试驱动编程:Test-driven programming
1)精确的需求说明:程序设计的理念是以编写测试程序开始,然后编写可通过测试的程序。测试程序就是你的需求说明,它帮助你在开发程序时不偏离需求
举例:编写一个模块,其中包括一个使用给定的宽和高计算长方形面积的函数。在开始编码前,首先要编写一个单元测试,其中包括带有几个答案已经清楚的例子:
View Code
from area import rect_area height = 3 width =4 correct_answer = 12 answer = rect_area(height, width) if answer == correct_answer: print 'Test passed' else: print 'Test failed'
2)为改变而计划:自动化测试除了在编写程序上给予巨大帮助外,还可以避免在实施修改时增加错误
代码覆盖度——coverage是测试知识中重要的部分。在运行测试的时候,有可能并没有运行代码的全部,即使在理想情况下也是这样(理想的情况应该是运行程序的所有可能状态,使用所有可能的输入,但是这不太可能)。优秀的测试程序组的目标之一是拥有良好的覆盖度,实现这个目标的方法之一是使用覆盖度工具,它可以衡量在测试过程中实际运行的代码的百分比。目前还没有可用的标准化覆盖度工具,搜索“Python测试覆盖度”会找到一个些可用的工具。其中一个是trace.py程序
3)测试的4步
A:指出需要的新特性。可以先记录下来,然后为其编写一个测试
B:编写特性的概要代码,这样程序就可以运行而没有任何语法等方面的错误,但是测试会失败。看到测试失败是很重要的,这样就能确定测试可以失败。如果测试代码中出现了错误,那么就有可能不管出现任何情况,测试都会成功,这样等于没测试任何东西。再强调一遍:在试图让测试成功前,先要看到它失败
C:为特性的概要编写虚设代码(dummy code),能满足测试要求就行。不用准确地实现功能,只要保证测试可以通过即可。这样一来就可以保证在开发的时候总是通过测试了(除了第一次运行测试的时候),甚至在最初实现功能时亦是如此
D:现在重写(或者重构,Refactor)代码,这样它就会做自己应该做的事,从而保证测试一直重构
在完成编码时,应该保证你的代码处于健康状态——不要遗留任何测试失败
2:测试工具——标准库中的模块可以帮助我们自动完成测试过程:
unitest:通用测试框架
doctest:简单一些的模块,是检查文档用的,但是对于编写单元测试也很在行
1)doctest:交互式解释器的会话可以是将文档字符串(docstring)写入文档的一种有用的形式。假如,假设我编写了一个求数字的平方的函数,并且在它的文档字符串中添加了一个例子:
View Code
def square(x): ''' Squares a number and returns the result. >>> square(2) 4 >>> square(3) 9 ''' return x*x
文档字符串中也包括了一些文本。这和测试又有什么关系?假设square函数定义在my_math模块(也就是叫做my_math.py的文件)中。之后就可以在底部增加下面的代码:
View Code
def square(x): ''' Squares a number and returns the result. >>> square(2) 4 >>> square(3) 9 ''' return x*x if __name__ == '__main__': import doctest.my_math doctest.testmod(my_math
doctest.testmod函数从一个模块读取所有文档字符串,找出所有看起来像是在交互式解释器中输入的例子的文本,之后检查例子是否符合实例要求(如果想实践“先测试,后编码”的编程方式,unittest框架是更好的选择)
为了获得更多输入,可以为脚本设定-v(意为verbose,即详述)选项开关:$ python my_math.py -v
2)unittest:doctest简单易用,unittest(基于Java的流行测试框架JUnit)则更灵活和强大。
提示:标准库中其他可选的单元测试工具包括py.test和nose
还是看一个简单的例子。假设要写一个模块my_math,其中包括计算乘积的函数product。从哪开始呢?对于测试来说,当然(位于文件test_my_math.py中)是使用unittest模块中的TestCase类:
View Code
#使用unittest框架的简单测试 import unittest, my_math class ProductTestCase(unittest.TestCase): def testIntegers(self): for x in range(-10,10): for y in range(-10,10): p = my_math.product(x,y) self.failUnless(p == x*y, 'Tnteger multiplication failed') def testFloats(self): for x in range(-10,10): for y in range(-10,10): x = x/10.0 y = y/10.0 p = my_math.product(x,y) self.failUnless(p == x*y, 'Float multiplication failed') #unittest.main函数负责运行测试,它会实例化所有TestCase的子类,运行所有名字以test开头的方法 if __name__ == '__main__' : unitteset.main()
如果定义了叫做startUp和tearDown的方法,它们就会在运行每个测试方法之前和之后执行,这样就可以用这些方法为所有测试提供一般的初始化和清理代码,这被称为测试夹具(test fixture)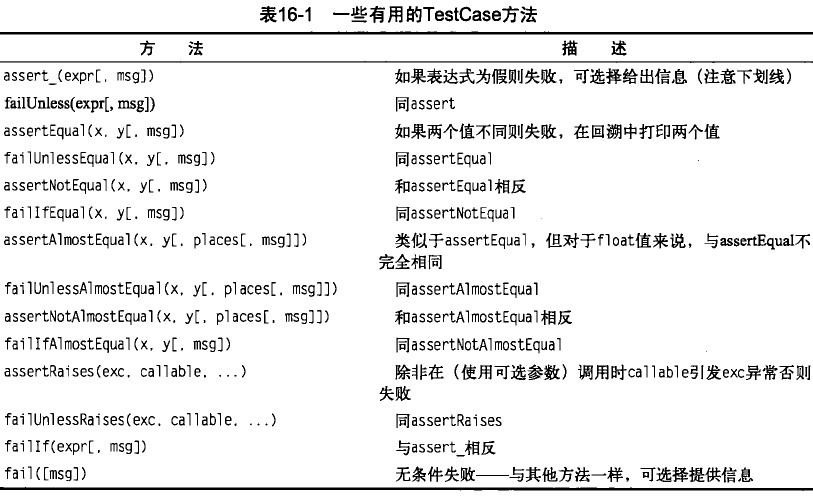
3:单元测试以外的东西:
源代码检查和分析:源代码检查是一种寻找代码中普通错误或者问题的方法(有点像编译器处理静态语言,但远不如此)。分析则是查明程序到底跑多快的方法。之所以按照这个顺序讨论这章的主题,是因为黄金法则“使其工作、使其更好、使其更快”的缘故。单元测试可以让程序可以工作,源代码检查可以让程序更好,最后,分析会让程序更快。
1)使用PyChecker和PyLint检查源代码
2)分析:试图让代码提速前,有个非常重要的规则需要注意(以及KISS原则,Keep It Small and Simple,即让它小且简单,或者YAGNI原则,You Ain't Gonna Need It,即并不需要它)——不成熟的优化是万恶之源
拿Unix的发明人之一Ken Thompson的话说就是“拿不准的时候,就穷举”。换句话说,如果不是特别需要的话,就不要在精巧的算法或者漂亮的优化技巧上有过多的担心。如果程序已经够快了,那么干净、简单并且易懂的代码的价值比稍微快一点的程序要高得多。
如果必须进行优化的话,那么绝对应该再做其他事情之前对其进行分析(profile)。这是因为很难估计到瓶颈在哪里,除非你的程序非常简单。标准库中已经包含了一个叫做profile的分析模块(还有个更快的嵌入式C语言版本,叫hotshot)。使用分析程序非常简单,是要使用字符串参数调用它的run方法就行了
>>> import profile >>> from my_math import product >>> profile.run('product(1,2)')
这样做会打印出信息,其中包括各个函数和方法调用的次数,以及每个函数所花费的时间。如果提供了文件名,比如'my_math.profile'作为第二个参数来运行,那么结果就会保存到文件中。可在之后使用pastats模块检查分析结果:
>>> import pstats >>> p = pstats.Stats('my_math.profile')
标准库中还包含一个名为timeit的模块,它是测试python小代码段运行时间的简单方法