一、什么是神经网络
深度学习(Deep Learning)就是训练神经网络(Neural Network)。有时候,这个神经网络的复杂度会非常高。神经网络又是什么呢?我们用一个示例来阐述神经网络模型的概念。
1. 通过房价预测模型认识神经网络
已知条件
- 一共六套房。
- 已知每套房的面积(即输入 x)。
- 已知每套房的价格(即输出 y)。
目标
根据已知输入输出数据,建立函数模型 y=f(x),来预测房价。
操作步骤
1. 将已知的六套房的价格和面积关系绘制在平面坐标系上:

2. 用一条直线拟合图中的离散点,建立房价与面积的线性模型。但结合实际情况,房价不可能为负数,所以修改为折线:
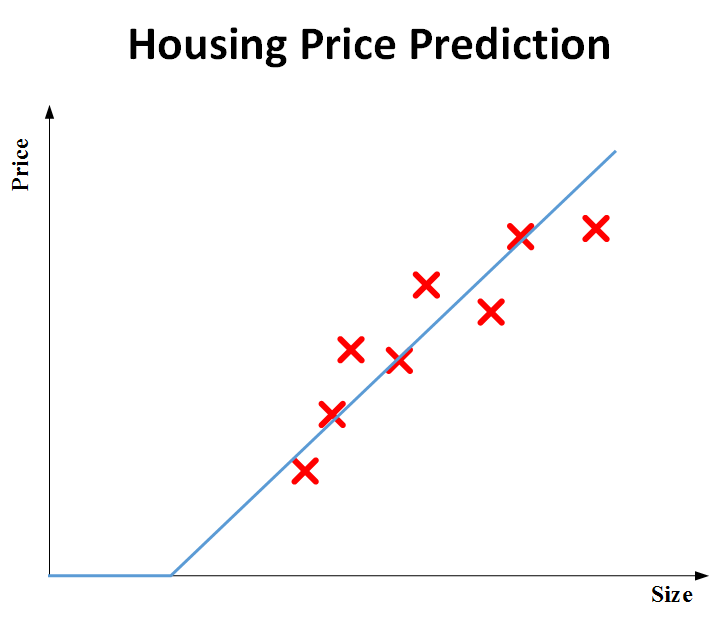
神经网络引入
我们拟合得到的这条折线,就可以看作一个神经网络(尽管它很简陋,几乎是最简单的神经网络)。既然看作是神经网络,当然要用神经网络模型来表示啦:

对于这个神经网络而言,输入 x 是房屋面积,输出 y 是房屋价格,中间包含一个神经元(neuron),这个神经元的功能就是实现函数 f(x) 的功能。
ReLU 函数
上述预测函数 f(x),即蓝色折线,实际上广泛应用在神经网络中。我们称之为 ReLU 函数(Rectified Linear Unit,线性整流函数)。其标准图像如下:
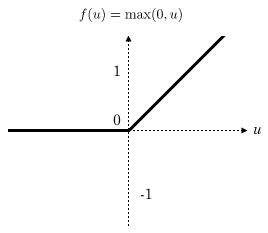
2. 房价预测模型 2.0——构建更复杂的神经网络
在上面的示例中,我们展示了单神经元组成的神经网络。但在实际应用中,正如房价不仅受面积这一个因素的影响,神经网络也往往由大量神经元组成。
现在我们在上一节的房价预测模型上进行拓展。除了面积之外,卧室数量、邮编(表示交通便利性)、地区财富水平(影响教育水平)等因素也会影响房价。想得到更理想的预测结果,就要考虑这些因素的影响:
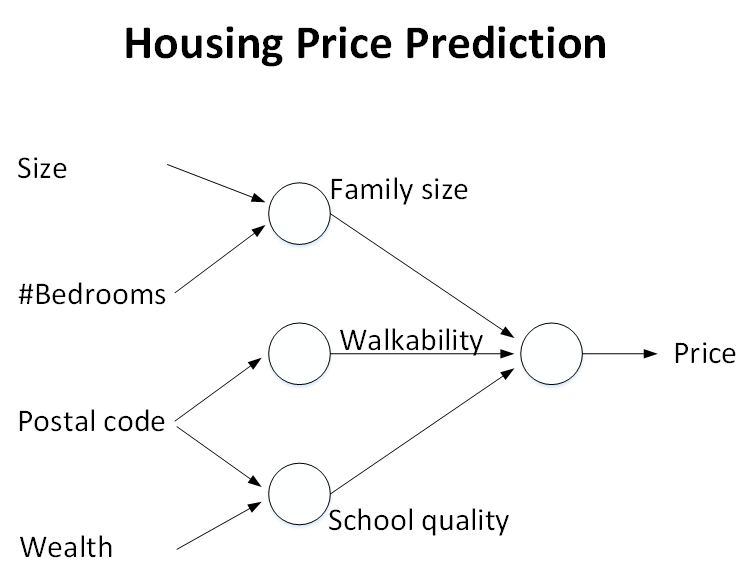
上图是经过拓展的神经网络,其中有四个输入。但它还不是这个示例真正的神经网络模型。在真正的神经网络模型中,每个神经元都和所有的输入 x 有关联:
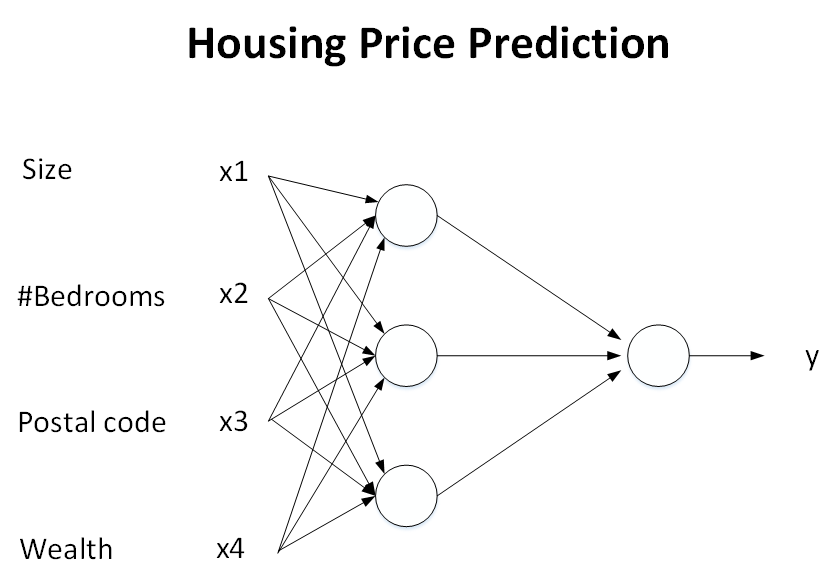
输入层
输入 x 所在的层。
中间层(隐藏层)
上图中三个神经元所在的层。
输出层
输出 y 所在的层。
以上就是基本的神经网络模型。只要使用足够多的输入 x 和输入 y 进行训练,就能训练出较好的神经网络模型,从而得到相对准确的结果。
二、用神经网络进行监督学习
什么是监督学习
实际应用中,机器学习解决的大部分问题都属于监督式学习(Supervised Learning),神经网络模型也大都属于监督式学习。
- 监督式学习:知道输入 x 和输出 y 之间的对应关系。
- 非监督式学习:不知道输入 x 和输出 y 之间的对应关系。
监督式学习应用示例
- 房屋价格预测。根据训练样本的输入x和输出y,训练神经网络模型,预测房价。
- 线上广告。输入 x 是广告类型和用户信息,输出 y 是用户是否会点击广告。训练后的神经网络模型,能够根据广告类型和用户信息对用户的点击行为进行预测,从而向用户提供可能感兴趣的广告。
- 电脑视觉(computer vision)。输入x是图片像素值,输出是图片所属的不同类别。
- 语音识别(speech recognition)。深度学习可以将一段语音信号辨识为相应的文字信息。
- 智能翻译,譬如输入 x 为英文,输出 y 为中文。
- 自动驾驶。输入 x 是路况图片或汽车雷达信息,训练后的神经网络会提示相应的路况信息,并作出决策。

神经网络的适用范围
针对不同的问题和应用场合,应该选用不同类型的神经网络模型:
- 一般的监督式学习(房价预测和线上广告问题),使用标准神经网络模型即可。
- 图像识别处理问题,使用卷积神经网络(CNN,Convolution Neural Network)。
- 处理类似语音的序列信号,使用循环神经网络(RNN,Recurrent Neural Network)。
- 类似自动驾驶这样的复杂问题,使用更复杂的混合神经网络模型。
CNN 和 RNN 都是比较常用的神经网络模型。CNN 一般处理图像问题,RNN 一般处理语音信号。
下图为 Standard NN,CNN 和 RNN 的神经网络结构图:

结构化数据(Structed Data)和非结构化数据(Unstructed Data)
结构化数据通常指的是有实际意义的数据。例如房价预测中的面积、卧室数、价格等,以及在线广告中的用户年龄、广告类别等。这些数据都具有实际的物理意义,比较容易理解。
非结构化数据通常指的是比较抽象的数据,例如音频、图像和文字。
以前计算机对非结构化数据处理能力较差。但得益于深度学习和神经网络的发展,计算机处理非结构化数据的效果越来越好,在某些方面甚至已经优于人类。总而言之,神经网络与深度学习的发展,使得计算机对结构化数据和非结构化数据的处理能力越来越好,并逐渐创造出巨大的实用价值。
在后续的学习和实际应用中,我们也会遇到大量结构化数据和非结构化数据。
三、深度学习为何兴起
数据规模扩大
深度学习和神经网络背后的技术思想已经出现数十年了,为什么直到现在才真正兴起呢?我们以下图进行说明。其中横坐标 x 表示数据量(Amount of data),纵坐标 y 表示机器学习模型的性能表现(Performance)。
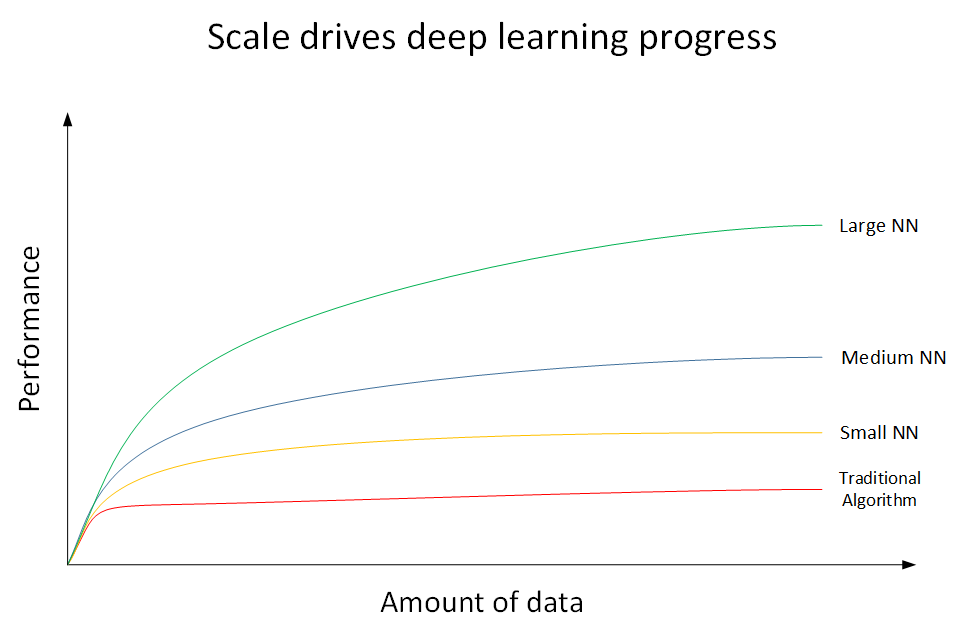
红色曲线表示传统机器学习算法的表现,譬如 SVM、logistic regression、decision tree 等。当数据量比较小的时候,传统学习模型的表现是比较好的。但是当数据量很大的时候,其表现很一般,性能基本趋于水平。
黄色曲线表示规模较小的神经网络模型(Small NN)。它在数据量较大时性能优于传统的机器学习算法。
蓝色曲线表示规模中等的神经网络模型(Medium NN),它在数据量更大的时候的表现比 Small NN 更好。
绿色曲线代表更大规模的神经网络(Large NN),即深度学习模型。在数据量很大的时候,它的表现仍然是最好的,而且基本上保持了较快上升的趋势。
近年来,由于数字计算机的普及,人类进入了大数据时代。如何对大数据建立稳健准确的学习模型变得尤为重要。传统机器学习算法在数据量较大的时性能一般,且很难再有提升。深度学习模型对大数据的处理和分析优势明显。所以,近年来在处理海量数据和建立复杂准确的学习模型方面,深度学习有着非常不错的表现。但同时也应看到,在数据量不大的时候,例如上图中的左侧区域,深度学习模型不一定优于传统机器学习算法,性能差异可能并不大。
算力增长
计算机的发展,使得运算能力大幅提升。
算法创新
算法的创新和改进也大大提升了深度学习的性能和速度。还是通过示例来说明:
早期神经网络神经元的激活函数是 Sigmoid 函数,后来改为 ReLU 函数。原因是 Sigmoid 函数在远离零点的位置,函数曲线非常平缓,其梯度趋于0,从而导致神经网络模型学习速度变得很慢。而 ReLU 函数在 x 大于零的区域,梯度始终为 1。尽管在 x 小于零的区域梯度为 0,但是在实际应用中采用 ReLU 函数确实要比 Sigmoid 函数快很多。
综上所述,深度学习的兴起,依赖于以下三个条件:
- 数据规模增大
- 算力提高
- 算法创新
四、深度学习的应用流程
构建一个深度学习时,首先要有想法,然后将其转化为代码,最后进行训练。根据训练结果,调整想法,继续进行这种循环,直到最终训练得到相对满意深度学习网络模型。计算速度越快,每一步骤耗时越少,上述循环越能高效进行。