0x00 前言
最近和朋友聊天,谈到了Mesh的内存优化问题,他发现开启Model Importer面板上的Mesh Compression选项之后,内存并没有什么变化。事实上,期望开启Mesh Compression后Mesh所占用的内存降低,是对Mesh Compression的作用的误解。
我相信很多同学看到Mesh Compression这个名字之后,也会有类似的误解。因此这篇博客就来聊一聊在Unity中如何对Mesh进行优化,以达到节约内存的目的,并且为何开启了Mesh Compression选项反而对内存没有什么帮助。
0x01 Unity中的Mesh压缩
在Unity中,主要有三种方式用来优化mesh数据的空间开销。
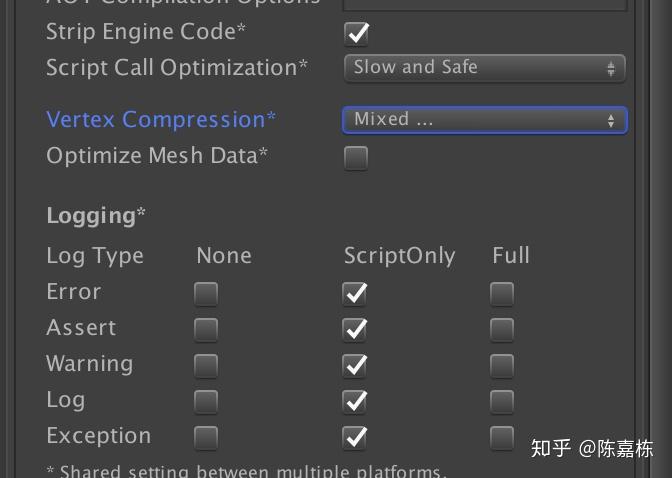
即Player Setting中的:
Vertex Compression
Optimize Mesh Data
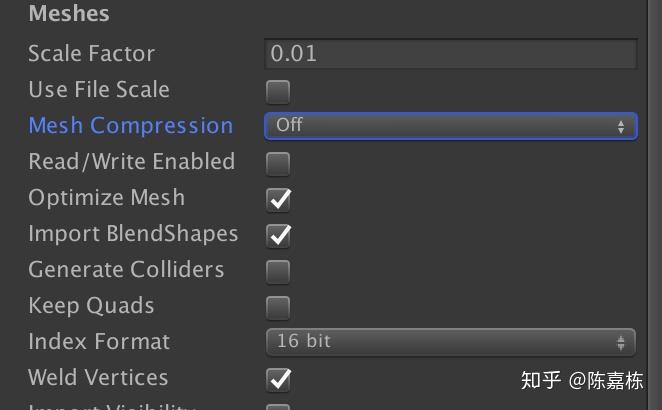
以及Model importer中的:
Mesh Compression
其中,Vertex Compression的实现是将顶点channel的数据格式format设置为16bit,因此可以节约运行时的内存使用(float->half)。
Optimize Mesh Data则主要用来剔除不需要的channel,即剔除额外的数据。因为与压缩无关,本文先暂时不讨论这个选项。
但是,Mesh Compression是使用压缩算法,将mesh数据进行压缩,结果是会减少占用硬盘的空间,但是在runtime的时候会被解压为原始精度的数据。
和Runtime时内存关系较大的是Vertex Compression的实现。
而是否可以进行Vertex Compression,则和模型的导入设置以及是否可以进行dynamic batching(在build 阶段,主要判断mesh的顶点数是否符合条件)有关。
简单可以归纳为以下几点:
1. 是否适合进行dynamic batching
2. 在Model Importer中是否开启了Read/Write Enabled
3. 在Model Importer中是否开启了Mesh Compression(是的,很吃惊是吧)
其中第一点,就是该mesh是否适合进行dynamic batching。这里不仅和player setting中是否勾选了dynamic batching有关,还和mesh的顶点数是否超过300有关。当然,dynamic batching是否可行主要和顶点属性的数量有关,但是为了简单,build阶段就按照常见的一个顶点带3个顶点属性,也就是300个顶点来做限制了。
所以如果开启了dynamic batching,则300个顶点以下的mesh不会被执行顶点压缩。
其次,Read/Write Enabled这个选项也会使Vertex Compression失效。所以一般情况下,为了节约内存最好不好勾选这个选项,除了无法进行顶点压缩之外,它还会额外在内存中保留一份mesh数据。
再次,也是大家常常忽略的一点,即如果开启了Mesh Compression,则会override掉Vertex Compression以及Optimize Mesh Data的设置 。Mesh Compression会将mesh在硬盘上的存储空间进行压缩,但是不会在runtime时节省内存。
0x02 测试
下面我们就通过几个小例子,来直观地查看一下各种设置下Mesh的内存占用情况。
Unity Version 2018.2.1
Windows Player
情况1:
默认情况,不开启压缩(MeshCompression和vertex compression),不开启Read/Write Enabled
Model Importer:
Building_e:
MeshCompression Off
Read/Write Enabled Off
Rock_c:
MeshCompression Off
Read/Write Enabled Off
Player Setting:
Dynamic Batching Off
vertex compression:None
Optimize Mesh Data:Off
测试结果:
Building_e 0.5mb
Rock_c 3.3kb
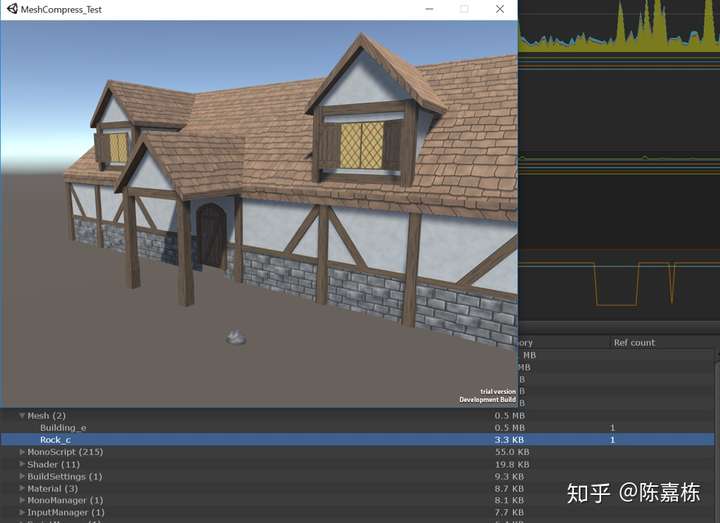
题外话:如果开启了Dynamic Batching,则Rock_c这个模型即便不开启Read/Write Enabled,其的内存占用也会更多,会达到5.9kb,这是因为对于顶点数较少(300以下)的模型,在开启动态合批的情况下我们会多保留一份它的mesh数据,即和Read/Write Enabled开启的效果是一样的。
情况2:
测试只开启vertex compression的情况。
Model Importer:
Building_e:
MeshCompression Off
Read/Write Enabled Off
Rock_c:
MeshCompression Off
Read/Write Enabled Off
Player Setting:
Dynamic Batching Off
vertex compression:Everything
Optimize Mesh Data:Off
测试结果:
Building_e 379.8kb
Rock_c 2.6kb
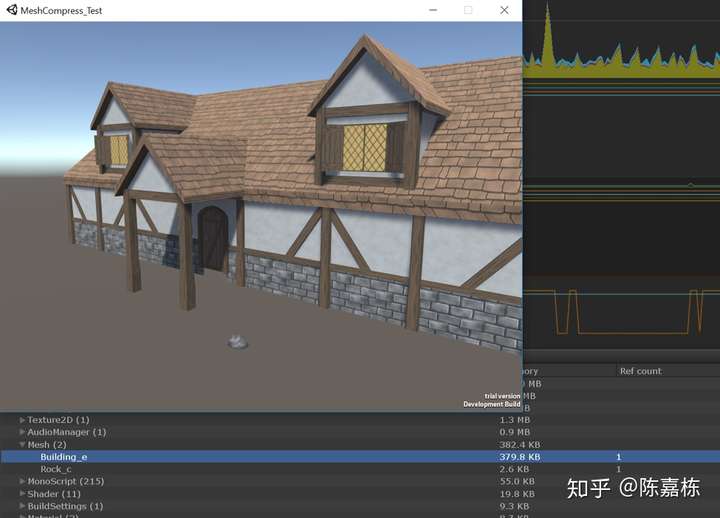
此时压缩生效。
情况3:
测试开启vertex compression 和 dynamic batching 的情况。
Model Importer:
Building_e:
MeshCompression Off
Read/Write Enabled Off
Rock_c:
MeshCompression Off
Read/Write Enabled Off
Player Setting:
Dynamic Batching On
vertex compression:Everything
Optimize Mesh Data:Off
测试结果:
Building_e 379.8kb
Rock_c 5.9kb
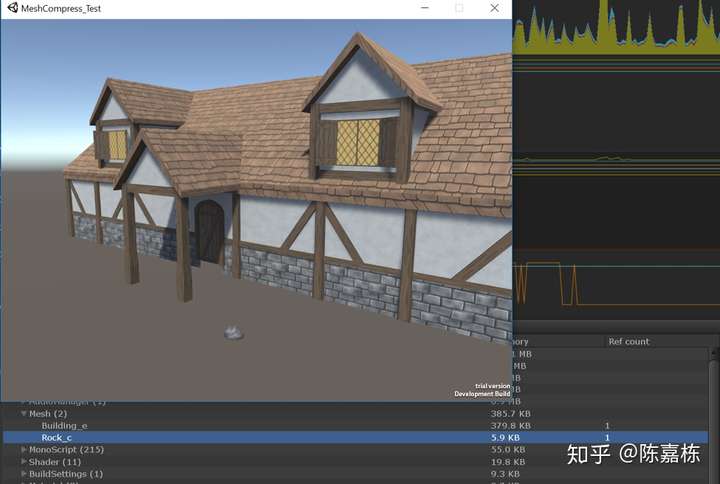
可以看到,Rock_c的内存占用升高了。这是因为Rock_c的顶点数只有40+,并且index buffer的format是16bit,在开启dynamic batching的情况下Build时被认为是符合动态合批条件的,因此在构建时不会执行vertex compression的操作。
因此在开启动态合批时,对一些小模型(vertex count<300)Vertex Compression是无效的。并且,这样的模型同样会保留在cpu可访问的内存中,以备动态合批的需要。
情况4:
测试开启vertex compression 和 dynamic batching 以及Read/Write Enabled的情况。
Model Importer:
Building_e:
MeshCompression Off
Read/Write Enabled On
Rock_c:
MeshCompression Off
Read/Write Enabled On
Player Setting:
Dynamic Batching On
vertex compression:Everything
Optimize Mesh Data:Off
测试结果:
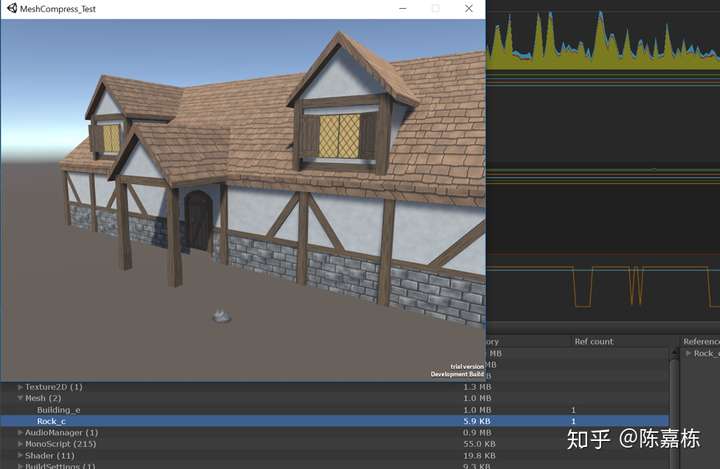
Building_e 1.0mb
Rock_c 5.9kb
可以看到,此时Building_e的内存不仅没有被压缩变小,反而由于开启了Read/Write Enable而翻倍了。而Rock_c由于之前说过的原因,显示的也是翻倍后的内存占用。
所以,为了保证vertex compression能够正常的执行,减小runtime时mesh的内存占用,不要开启 Read/Write Enable。
情况5:
测试开启vertex compression 和 dynamic batching 以及Mesh Compression的情况。
我想最让人迷惑的可能就是Mesh Compression这个选项。从字面理解,这个选项的开启是对模型进行压缩的意思。但是实际上开启这个选项只会减小mesh在硬盘的存储大小,在runtime时vertex使用format并没有被改变,仍然是Float。因此也就无法实现Runtime时内存的优化。
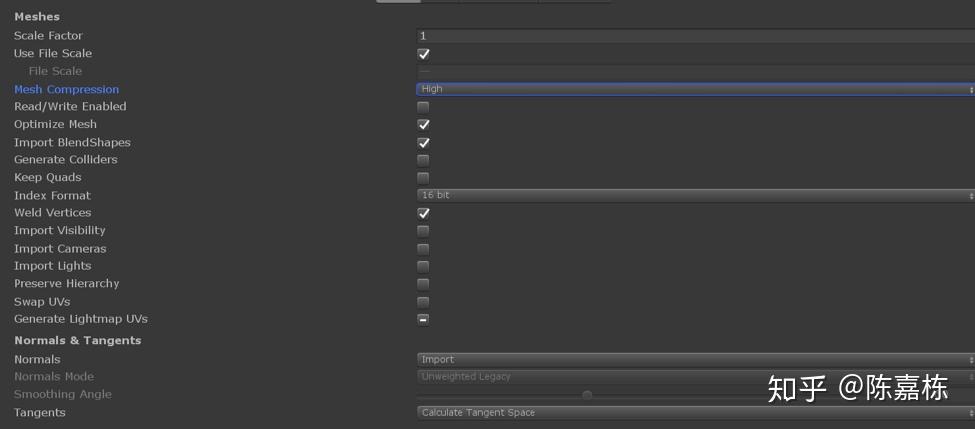
Model Importer:
Building_e:
MeshCompression On
Read/Write Enabled Off
Rock_c:
MeshCompression On
Read/Write Enabled Off
Player Setting:
Dynamic Batching On
vertex compression:Everything
Optimize Mesh Data:Off
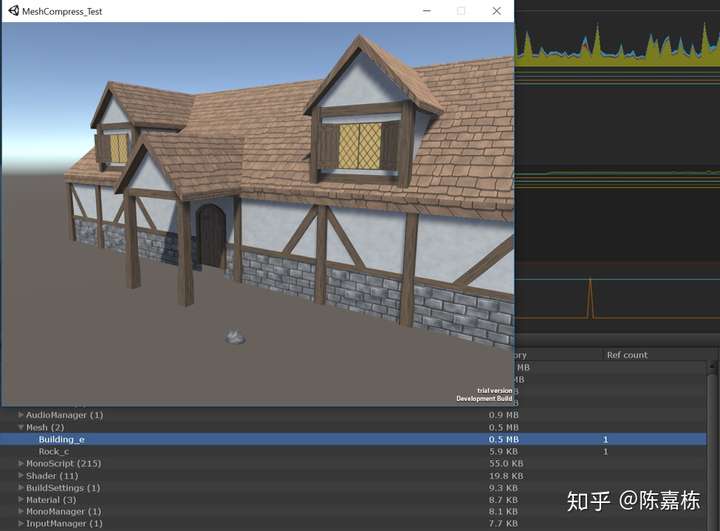
测试结果:
Building_e 0.5mb
Rock_c 5.9kb
让人吃惊的来了,Vertex Compression失效了。开启了Mesh Compression之后,内存回到了没有压缩时的数值。
0x03 结论
之所以勾选Mesh Compression后会有这个结果的原因,在上文已经描述了很多。
因此,一个小建议就是如果为了优化Mesh的内存开销,不要开启Mesh Compression,以避免Vertex Compression的失效。