| 结对同学博客地址 | https://www.cnblogs.com/wyl0074/ |
|---|---|
| 本作业博客地址 | https://www.cnblogs.com/muse-code/ |
| github地址 | https://github.com/fzu181800330/181800330-181800415 |
具体分工
| 181800415牟迪 | 核心算法设计和实现,代码优化 |
|---|---|
| 181800330王逸凌 | 前端页面设计和实现,博客编写,github目录组织 |
| 共同完成 | 单元测试 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| Estimate | 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 180 | 360 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 180 |
| Design Spec | 生成设计文档 | 60 | 80 |
| Design Review | 设计复审 | 40 | 160 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 45 |
| Design | 具体设计 | 150 | 200 |
| Coding | 具体编码 | 180 | 250 |
| Code Review | 代码复审 | 20 | 65 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 300 |
| Reporting | 报告 | 20 | 60 |
| Test Report | 测试报告 | 30 | 50 |
| Size Measurement | 计算工作量 | 20 | 50 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 40 | 80 |
| Sum | 合计 | 1020 | 2000 |
解题思路描述
前期准备
分析本次题目总结出了如下难点:
- 如何处理输入的文本数据
- 如何将输入数据转化为正确的师门树
- 如何让多棵树并存于同一网页
- 如何让树的节点合理的进行缩放
代码实现
树形结构的搭建
对于前端小白的我们,只能面向博客园和CSDN来解决问题,我们搜索了许多的实现树形结构的方法,包括一些实现数据可视化的框架如echarts、D3等等,并花费了一些时间进行框架的学习,本想着利用这些框架来实现树形结构,但是想要在短短一周达到灵活运用,对于现阶段的我们着实有着不小的难度,因此,我们果断放弃(菜是原罪),转而用JQuery来实现,以此来构建树形结构。
- 在这里附上JQuery的一份菜鸟教程(JQuery菜鸟教程)
处理输入的文本数据及展示功能
如何将文本框中的信息合理利用,转化成有用的格式,这又是我们碰到的一个难题,在队友超神的发挥下,我们成功的找到了解决方法,可以通过将文本输入内容转化为JSON格式,通过关键词的分割,按级转化为JSON格式并重新保存,关键词分割严格按照老师给定的"导师:","级博士生:","级硕士生:","级本科生:"和"、"来划分,如果关键词判断为"导师:",则建立根节点,如果是学历、姓名、技能包、联系方式等就建立叶节点,以此来动态生成新的JSON变量,为后续输出。
多树共存
在能成功显示一棵树的相关信息之后,接下来的任务就是多树共存的问题了,在处理完一棵树之后,我们需要进行下一棵树的数据处理,在页面产生新的div来展示,但是对于这一块内容对于蒟蒻的我们又是一个知识盲区,这时候,万能的队友又双叒叕出现了,在查阅大量资料之后,找到了一种方法,用JQuery.js来产生新的块,块中产生新的树,
核心流程图与数据流图
流程图:
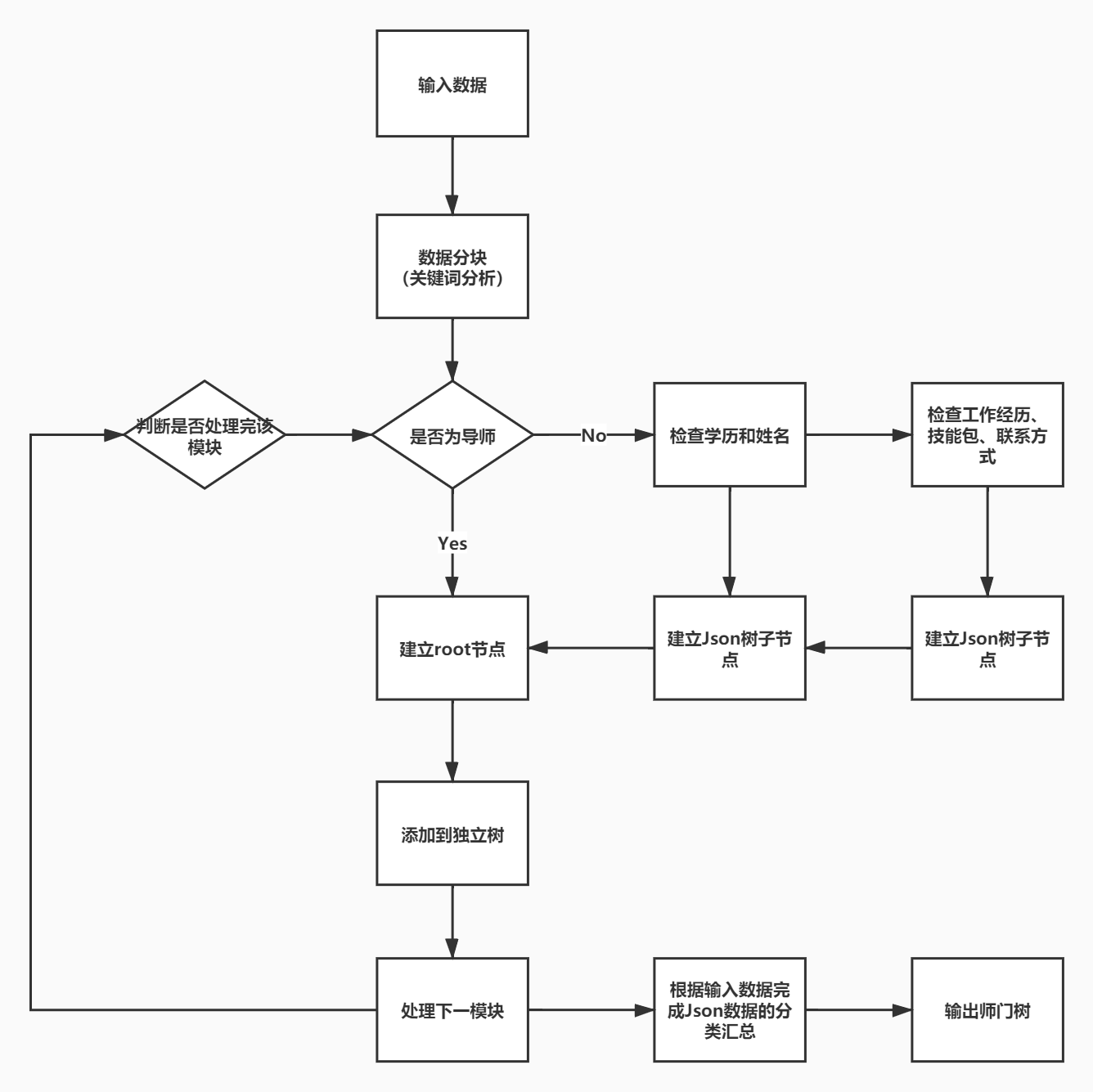
数据流图:
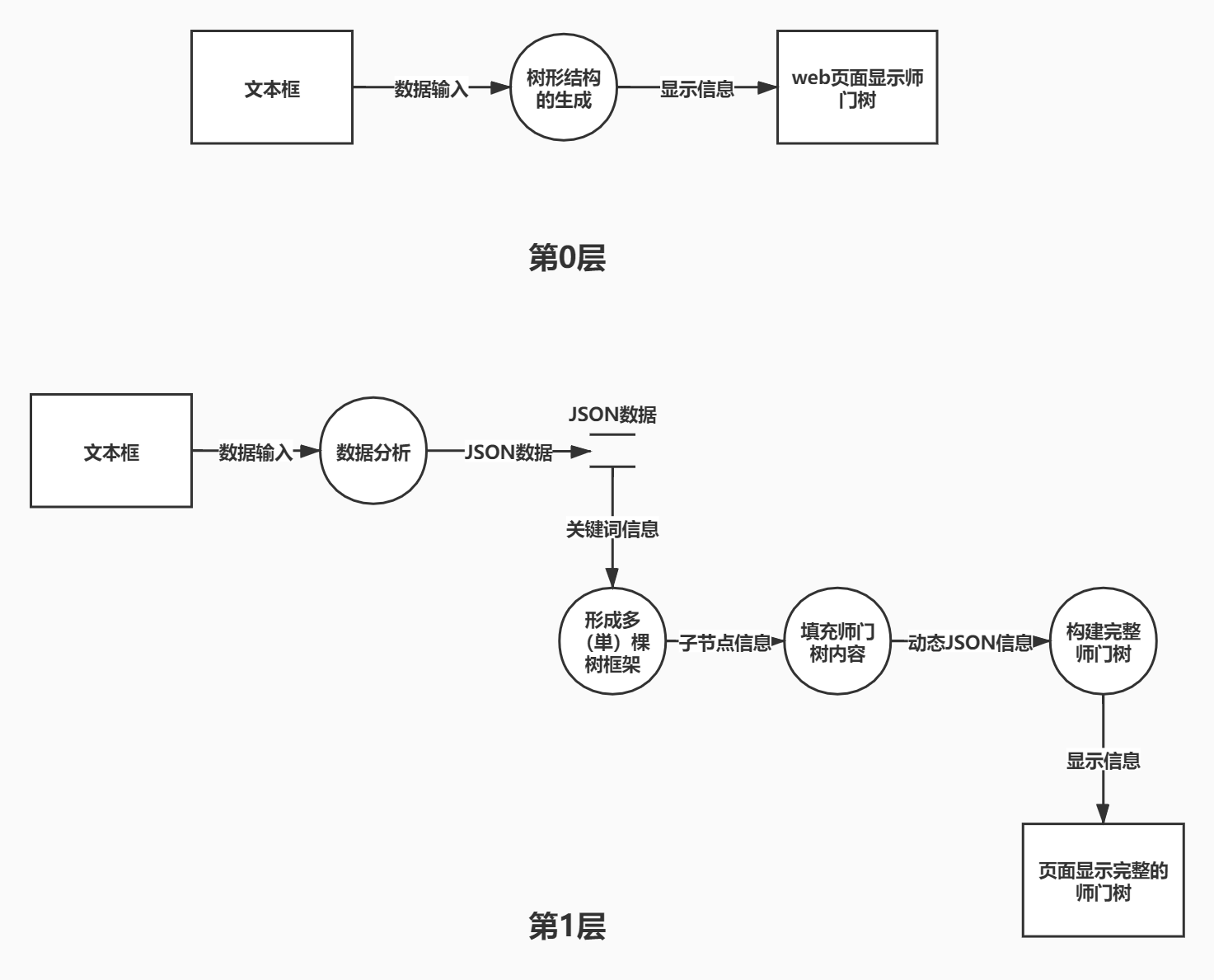
核心代码
根节点生成
for(var k = 0; k < block.length; k++){
//导师节点
json[k] = {};
json[k].name = block[k].match(/(?<=导师:).*/) + '';//关键词“导师:”查询
// console.log(json[k].name);
json[k].code = json[k].name;
json[k].icon = "icon-th";
json[k].child = [];
var count = 0;//确定子节点
- 当输入数据之后首先要做的就是提取导师这个关键词,并建立根节点,建立根节点之后才可以进行后续的遍历查找以此来找到不同学历不同年级的人的相关信息。
子节点的查找
//分不同级博士生
for(var i = 0; i < docArray.length; i++){
var year = {};
year.name = docArray[i].match(/d{4}/) + '';//按照年份进行分类
// console.log(year.name);
year.code = doc.code + year.name;
year.icon = "icon-minus-sign";
year.parentCode = doc.code;
year.child = [];
//学生名节点
var stuName = docArray[i].match(/(?<=级博士生:).*/) + '';
console.log(stuName);
var stuNameArray = stuName.split("、");
//console.log(stuNameArray);测试
//同级不同学生
for(var j = 0; j < stuNameArray.length; j++){
var stu = {};
stu.name = stuNameArray[j];
stu.code = year.code + stu.name;
stu.icon = "";
stu.parentCode = year.code;
stu.child = [];
var cnt=0;
var reg1=new RegExp(("(?<="+stu.name+":).*"));//学生的技能树分类
var skill=data.match(reg1)+'';
if(skill!='null'){
var attribute1={};
attribute1.name="工作经历或科研方向";
attribute1.code=stu.code+attribute1.name;
attribute1.icon="";
attribute1.parentCode=stu.code;
attribute1.child=[];
var skillArray=skill.split("、");//创建技能树数组
for(var p=0;p<skillArray.length;p++){
var newskill={};
newskill.name=skillArray[p];
newskill.code=attribute1.code+newskill.name;
newskill.icon="";
newskill.parentCode=attribute1.code;
newskill.child=[];
attribute1.child[p]=newskill;
}
stu.child[cnt++]=attribute1;
}
var reg2=new RegExp(("(?<="+stu.name+"的联系方式:).*"));//附加功能 添加某某的联系方式
var message=data.match(reg2)+'';
if(message!='null'){
var attribute2={};
attribute2.name="联系方式";
attribute2.code=stu.code+attribute2.name;
attribute2.icon="";
attribute2.parentCode=stu.code;
attribute2.child=[];
var messageArray=message.split("、");
for(var m=0;m<messageArray.length;m++){
var mes={};
mes.name=messageArray[m];
mes.code=attribute2.code+mes.name;
mes.icon="";
mes.parentCode=attribute2.code;
mes.child=[];
attribute2.child[m]=mes;
}
console.log(stu.child)
stu.child[cnt]=attribute2;
}
//stu.child[1]=attribute2;
// console.log(skill);//测试
console.log(skillArray);
year.child[j] = stu;
console.log(stu.name);
}
doc.child[i] = year;
}
json[k].child[count++] = doc;
}
- 当根节点确定之后接下来就是子节点的添加了,首先按照学位进行分割,划分出不同学位的学生,其次便是按年级进行分割,划分出不同年级的同学,接下来,就是技能包和工作经历的分割,同样是进行关键词处理,得出结果,最后便是我们的附加功能——添加联系方式,同样是按照相同的方法,进行关键词分割,最后输出师门树。
多棵树并存
//将data数据按导师划分成不同块
if(teacherIndex.length < 1){
block[0] = data;
}else{
for(var i = 0; i < teacherIndex.length; i++){
block[i] = '';
var last = i + 1 == teacherIndex.length? data.length : teacherIndex[i + 1];
for(var j = teacherIndex[i]; j < last; j++){
block[i] += data[j];
}
}
}
- 多棵树并存由上述代码来实现,对于有多个导师输入的时候,首先要按照导师去分块,分块之后就可以进行上述代码段的操作生成多棵树。
附加特点与展示
设计的创意独到之处,这个设计的意义:
师门树信息多元化
-
除了工作经历、技能树等基本信息,额外添加了联系方式的功能,当输入文本框中包含联系方式之后可以正确合理的在师门树中展现,丰富了师门树的内容,让这棵树的呈现更为饱满。
-
对于同门师兄弟来说,一棵完整的师门树应该具备多元化的信息,光有技能包和工作经历是远远不够的,如果想要更进一步去了解同门的师兄师姐,联系方式是必不可少的,有了联系方式,就可以让有需要进一步了解相关情况的同学更快捷的进行联系,从而优化效率,让师门树发挥更多的效用。
交互界面人性化
-
在输入文本框中添加提示信息与注释背景,无论是让助教老师,还是同学都能一目了然,掌握正确的输入格式,快速完成测试,节约时间提高效率,同时,能够更加人性化的将完整的师门树展现在眼前。
-
由于关键词的检索机制,以及输入内容纷繁复杂,输入格式不得不有所规范,因此,人性化的格式提醒是必不可少的,有了人性化的界面交互就可以更加让输入更加轻松方便。
页面美观化
-
对于师门树提供结点收缩展开功能,当成员信息较多时,结点收缩展开可以使得信息查看更便利,不会占据太多空间,使整个师门树显得更加精致。
-
小清新的背景别具一格,同时实现了界面跳转功能,输入框和生成树分别单独成为一个前端界面,使整个生成流程更加流畅自然。
实现思路:
-
对于交互界面这一部分,我们在container这个div部分添加了提示信息,能够让用户在输入界面就能够清晰的知道输入的格式。
-
对于信息多元化这一部分,我们通过添加“联系方式:”的关键词,对与输入文本进行判断,进行筛选,添加到姓名后面。
关键代码:
var reg2=new RegExp(("(?<="+stu.name+"的联系方式:).*"));//关键词判断:联系方式
var message=data.match(reg2)+'';
if(message!='null'){
var attribute2={};
attribute2.name="联系方式";
attribute2.code=stu.code+attribute2.name;//找出有用信息,添加到对应姓名后面
attribute2.icon="";
attribute2.parentCode=stu.code;
attribute2.child=[];
var messageArray=message.split("、");//关键词判断:、
for(var m=0;m<messageArray.length;m++){
var mes={};
mes.name=messageArray[m];
mes.code=attribute2.code+mes.name;//找出有用信息,添加到对应姓名后面
mes.icon="";
mes.parentCode=attribute2.code;
mes.child=[];
attribute2.child[m]=mes;
}
stu.child[cnt]=attribute2;
}
实现成果展示
输入界面展示:

多棵树并存:

添加额外的联系方式:

目录说明和使用说明
目录说明(一)

目录说明(二)
目录说明(三)
-
index.html和JStext.html两个是前端网页代码,我们设计了两个界面,分别是主页和生成图结果页面,运行只需要打开JStext.html 然后输入测试数据 点击”生成树“按钮,即可生成树状图。
-
CSS目录下的是第三方库bootstrap.min.css以及自己写的界面风格设计代码
-
img目录下的是网页界面背景图
-
js目录下的是第三方库jquery以及自己写的生成树函数代码
使用说明
-
点击Github上的Clone or Download按钮后可选择下载压缩包或复制链接后使用git clone命令下载
-
解压到本地之后,通过Chrome浏览器打开JStext.html,在输入框中输入符合格式的信息,点击按钮便会跳转到家族树界面
-
jStext.html是主页面,用户直接双击文件夹中的jStext.html或右键选择浏览器打开,然后输入测试数据,点击“生成树”按钮,即可生成树状图。
(更多内容详见README文件)
单元测试
选用工具:
- Qunit和chrome控制台
学习过程:
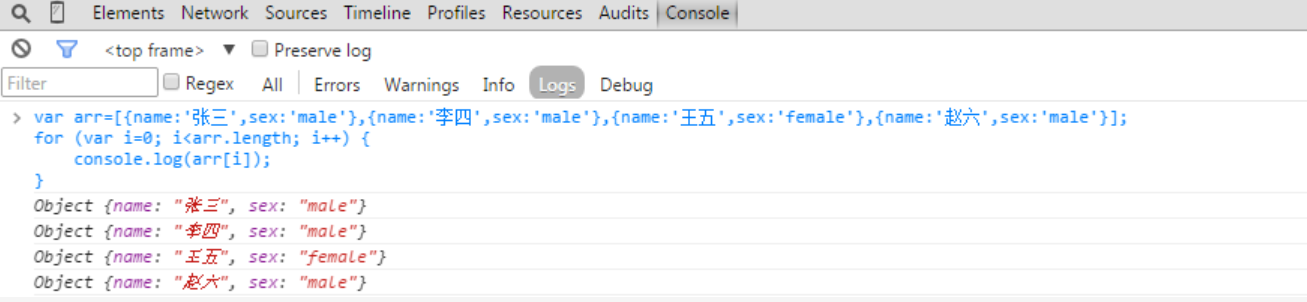
- 这次我们通过两种方式来进行单元测试,也希望能够提升一下我们对于单元测试这一模块的学习。对于chrome控制台,我们学习有关Console通过console.log()进行测试。

- 在代码中使用console.log()的命令检查数据分割的正确性,对debug的过程进行测试,比如输入文本字符串的处理:搜索字符串中的关键词,按照导师、博士生、硕士生、本科生进行划分,将对应的字符串进行分割处理,存入数组,数组里面保存的是相同学历的学生名字 ,因为在测试的前期我们无法得知到底指令对不对,有了这个工具后我们确实加速了很多的进度。
- 用Qunit进行生成树的测试,输入测试的文本数据,将代码输出的生成树结果与测试正确的生成树结果进行比较,如果对比正确,则测试成功,测试样例选择十种输入文本数据和生成树结果。
简易教程
QUnit使用教程:
-
首先安装
npm:登录官网http://nodejs.org/下载nodejs -
使用
npm下载QUnit:npm install--save-dev qunit -
或者登录官网http://qunitjs.com/,下载两个文件:
-
QUnit代码范例:创建
tests.html,进行测试的浏览器页面展示。tests.js为自己写的测试代码。
部分测试代码
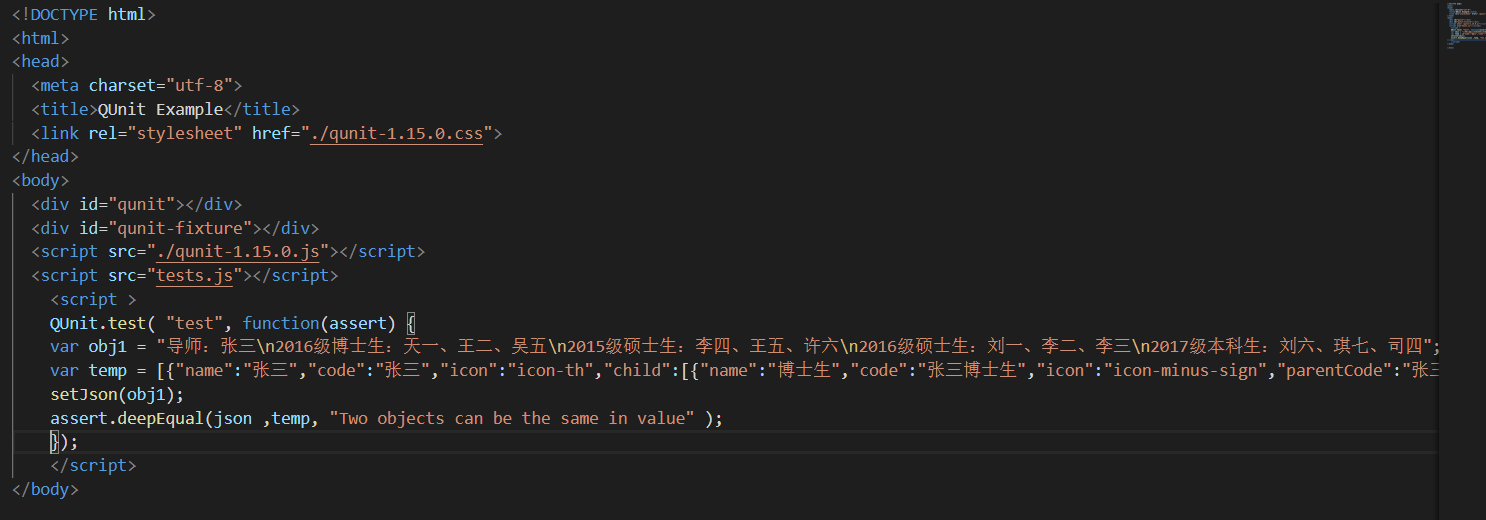
测试结果

测试思路以及如何应对刁难
-
测试数据主要被分为了正常情况和异常情况,正常情况主要构造了单棵树和多棵数的测试数据,对于异常情况,因为这次的数据完全由用户输入,所以需要考虑的异常情况较多,因此针对各种格式错误构造了比较多的异常数据进行测试。例如输入不存在的数据,符号用了英文的符号,关键词不正确等异常。
-
应对测试的刁难:得益于全局的异常处理,没考虑到的异常情况会进行提示报错,测试人员可以根据该异常信息判断问题。
Git截图
遇到的问题和解决方法
-
首先,便是沟通上出现了一些问题,虽然前期在总体思路上有一定的讨论,但是由于核心代码的开发部分主要是由队友负责,因此,在功能实现这一方面,在中期产生了一些分歧,导致浪费了很多时间,所幸,我们俩及时进行二次讨论,对于有冲突的部分进行的二次评估,再次分析了我们需要实现的功能,最后成功的完成了本次作业。
-
css没写好没用好,页面布局没有达到想要的效果,不好看(虽然改完也不好看但是比一开始好),后来查文档,百度样式,搜索视频,参考其他页面的样式解决了这个问题。
-
对于单元测试其实还是处在一个懵懵懂懂的阶段,对于单元测试的代码实现在一开始完全没有下手的地方(
菜是原罪),因此,我们又双叒叕的开启了面向CSDN和博客园编程,在阅读了大量关于单元测的资料之后,我们决定选用Qnit来进行测试,同时,队友找了一个类似的模板,我们在他的基础上进行修改,最后完善了我们的测试代码。此外,在debug过程中,也加深了我们对于chrome的console.log()的理解。
评价队友(经典商业互吹)
王逸凌:膜,orz,膜!,执行能力强,码力深厚。
- 值得学习的地方:高效的执行编码能力,强大的learning by doing!能力。
- 需要改进的地方:编码的变量名和参数名设置有待提高。
牟迪:膜,orz,膜!,博客编辑优美,Github熟练度高。
- 值得学习的地方:编辑博客技术高超,表达能力强。
- 需要改进的地方:有些时候会出现直男审美,希望能不断提高审美能力。