2018-2019-1 20165226 《信息安全系统设计基础》第3周学习总结
目录
教材学习内容总结
**** ### 1、机器级代码 > ①两种抽象 > - ISA(指令集体系结构或指令集架构)——定义机器级程序格式和行为 > - 虚拟地址——机器级程序使用的内存地址 > > ② 隐藏的处理器状态 > - 程序计数器(pc,`在x86-64中用%rip表示`)——给出将要执行的下一条指令在内存中的地址。 > - 整数寄存器文件包含16个命名的位置 > - 条件码寄存器保存着最近执行的算术或逻辑指令的状态信息 > - 一组向量寄存器可以存放一个或多个整数或浮点数值 > > ③ `gcc -S xxx.c -o xxx.s `获得汇编代码,也可以用`objdump -d xxx `反汇编; 注意函数前两条和后两条汇编代码,所有函数都有,建立函数调用栈帧。 > - 编译C语言代码时,使用`-S`只产生一个汇编文件`xxxxx.s`,使用`-c`时会编译并汇编该代码,产生目标代码文件xxxxx.o` > > - 查看机器代码文件内容——反汇编器,`objdump -d xxxxx.o` 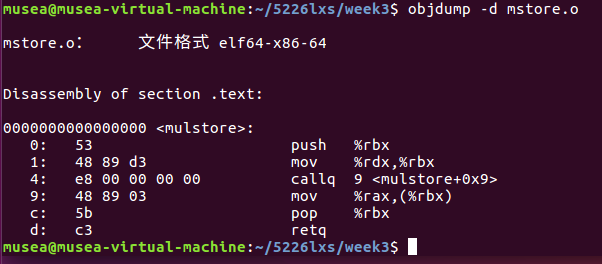 > > - 展示程序的字节表示——`x/14xb xxxxx`2、代码示例:
int accum = 0;
int sum(int x, int y)
{
int t = x + y;
accum += t;
return t;
}
- 输入
gcc -c code.c - 反汇编结果:
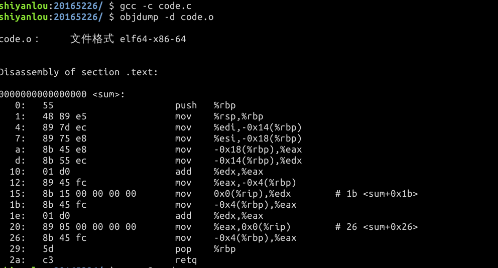
3、数据格式
| C声明 | 汇编代码后缀 | 大小(字节) |
|---|---|---|
| char | b- 字节 | 1 |
| short | w- 字 | 2 |
| int | l- 双字 | 4 |
| long | l- 双字 | 4 |
| long long int | - | 8 |
| char * | l- 双字 | 4 |
| float | s- 单精度 | 4 |
| double | l- 双精度 | 8 |
| long double | t- 扩展精度 | 10/12 |
movb:传送字节
movw:传送字
movl:传送双字(后缀‘l’也用来表示4字节整数和8字节双精度浮点数)
movq:传送四字
4、有效地址的计算方式 Imm(Eb,Ei,s) = Imm + R[Eb] + R[Ei]*s
5、跳转指令:
- 直接跳转——
.L1 - 间接跳转——
* 操作指示符 - jmp *%rax——用寄存器%rax中的值作为跳转目标
- jmp *(%rax)——以%rax值作为读地址,从内存中读出跳转目标
教材学习中的问题和解决过程
**** - 问题1: 教材P113中的`gcc -0g -o p p1.c p2.c`中的`-0g`表示什么优化等级,优化等级有哪些? - 问题1解决方案: > -O0: 不做任何优化,这是默认的编译选项。 > -O和-O1: 对程序做部分编译优化,对于大函数,优化编译占用稍微多的时间和相当大的内存。使用本项优化,编译器会尝试减小生成代码的尺寸,以及缩短执行时间,但并不执行需要占用大量编译时间的优化。 > -O2: 是比O1更高级的选项,进行更多的优化。Gcc将执行几乎所有的不包含时间和空间折中的优化。当设置O2选项时,编译器并不进行循环打开`()loop unrolling`以及函数内联。与O1比较而言,O2优化增加了编译时间的基础上,提高了生成代码的执行效率。 > -O3: 比O2更进一步的进行优化。 > -Os: 主要是对程序的尺寸进行优化。打开了大部分O2优化中不会增加程序大小的优化选项,并对程序代码的大小做更深层的优化。(通常我们不需要这种优化)Os会关闭如下选项: -falign-functions -falign-jumps -falign-loops -falign-labels -freorder-blocks -fprefetch-loop-arrays > > O0选项不进行任何优化,在这种情况下,编译器尽量的缩短编译消耗(时间,空间),此时,debug会产出和程序预期的结果。当程序运行被断点打断,此时程序内的各种声明是独立的,我们可以任意的给变量赋值,或者在函数体内把程序计数器指到其他语句,以及从源程序中 精确地获取你期待的结果. O1优化会消耗少多的编译时间,它主要对代码的分支,常量以及表达式等进行优化。 O2会尝试更多的寄存器级的优化以及指令级的优化,它会在编译期间占用更多的内存和编译时间。 O3在O2的基础上进行更多的优化,例如使用伪寄存器网络,普通函数的内联,以及针对循环的更多优化。 Os主要是对代码大小的优化,我们基本不用做更多的关心。 通常各种优化都会打乱程序的结构,让调试工作变得无从着手。并且会打乱执行顺序,依赖内存操作顺序的程序需要做相关处理才能确保程序的正确性。- 问题2: CMP和SUB用在什么地方
- 问题2解决方案:
CMP 比较指令做了减法运算以后,根据运算结果设置了各个标志位。
标志位设置过以后,0FFFFH这个减法运算的结果就没用了,它被丢弃,不保存。执行过了CMP指令以后,除了CF,ZF,OF, SF,等各个标志位变化外,其它的数据不变。
对照普通的减法指令 SUB AX, BX,它们的区别就在于:
SUB指令执行过以后,原来AX中的被减数丢了,被换成了减法的结果。
CMP指令执行过以后,被减数、减数都保持原样不变。
代码学习中的问题和解决过程
****- 问题1:
gcc 编译出错

- 问题1解决办法:
通过提示,发现将
-o误写成了-0,更改后成功运行。
代码托管与统计
**** [代码托管](https://gitee.com/Sean-Lxs/5226lxs.git) 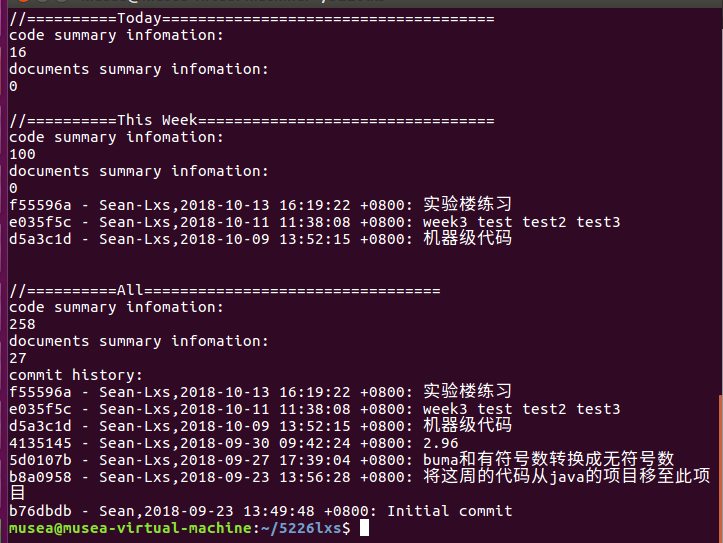练习
**** ### 实验楼课后习题: - 代码实现并生成汇编文件 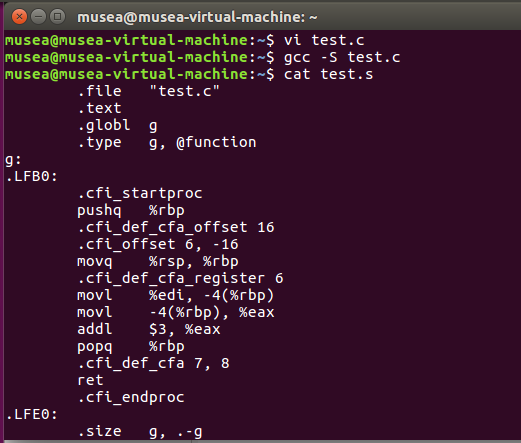- 使用gdb的bt/frame/up/down 指令动态查看调用栈帧的情况
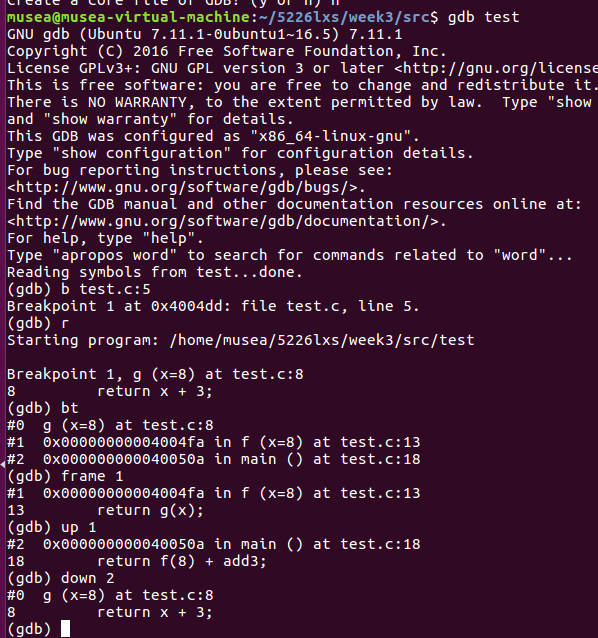
知识点分析
1、backtrace/bt n
- n是一个正整数,表示只打印栈顶上n层的栈信息。
- n表一个负整数,表示只打印栈底下n层的栈信息。
2、frame n - n是一个从0开始的整数,是栈中的层编号。比如:frame 0,表示栈顶,frame 1,表示栈的第二层。
这个指令的意思是移动到n指定的栈帧中去,并打印选中的栈的信息。如果没有n,则打印当前帧的信息。
3、up n - 表示向栈的上面移动n层,可以不打n,表示向上移动一层。
4、down n - 表示向栈的下面移动n层,可以不打n,表示向下移动一层。
学习进度条
****| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 87/87 | 2/2 | 20/20 | |
| 第二周 | 71/158 | 1/3 | 12/32 | |
| 第三周 | 100/258 | 2/5 | 13/45 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:10小时
-
实际学习时间:12小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)