Hive
基于Hadoop的数据仓库工具;
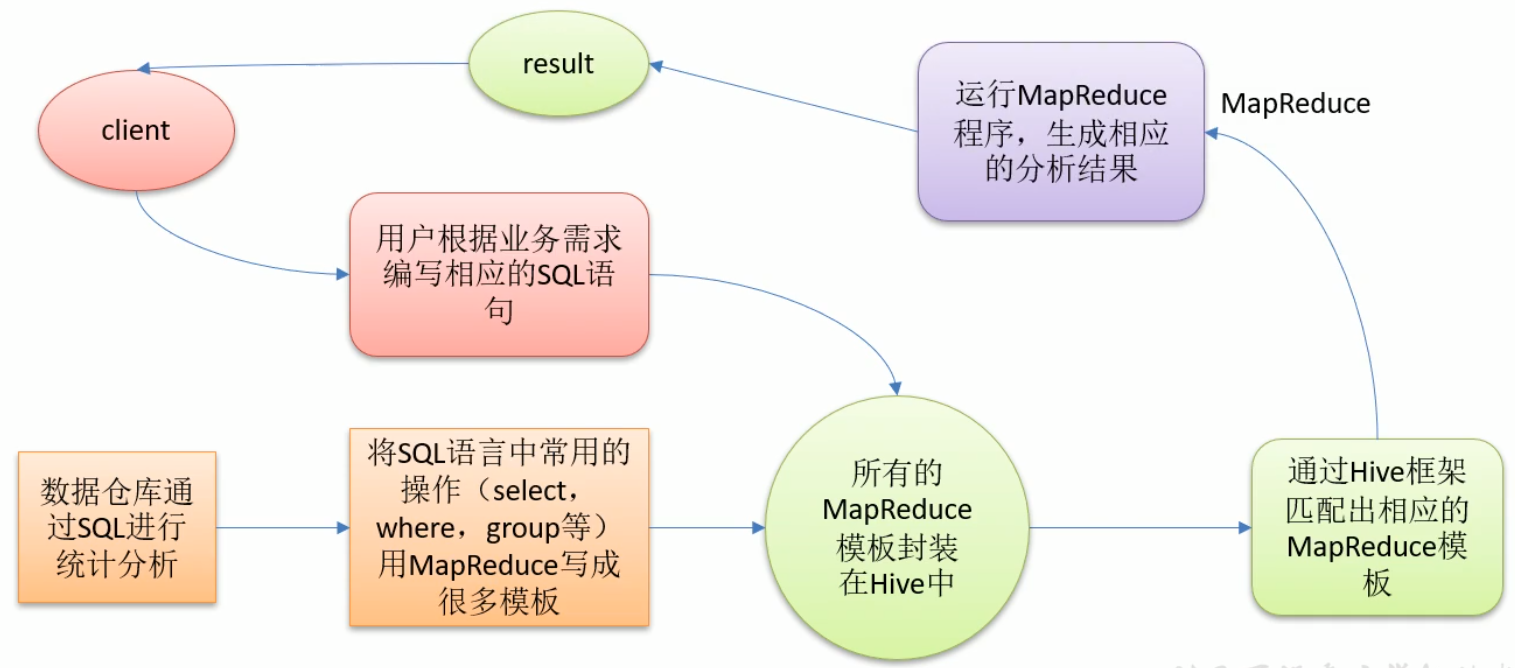
将结构化的数据文件,映射为一张表,并提供类SQL查询功能;
本质:将HQL转化为MapReduce程序;

-
Hive处理的数据存储在HDFS;
-
Hive分析数据底层的默认实现是MapReduce;
-
执行程序是在Yarn上;
特点
-
Hive执行延迟高,适用于对实时性要求不高的场景;优势在于处理大数据,不适合处理小数据
-
(MR)不适合迭代式运算,不适合数据挖掘;
-
(MR)效率低;
-
调优困难,粒度太粗;
-
作为数据仓库的Hive,是读多写少,基本不修改;
-
没有索引,查询数据,要暴力扫描所有的数据(分区表可以减少搜索范围),延迟较高(主要由于MapReduce的框架本身延迟较高);
Hive配置
准备
-
hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://master:3306/metastore?createDatabaseIfNotExist=true</value> <description>metastore地址</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver name</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>whr</value> <description>username</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> <description>password</description> </property> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> <!--交互界面显示数据库名--> </property> </configuration>
-
hive.env.sh
# 添加两个配置 HADOOP_HOME=/home/whr/workbench/hadoop export HIVE_CONF_DIR=/home/whr/workbench/hive/conf -
初始化,也可以先创建数据库,这里有点简化了mysql的操作,mysql中的数据库以及用户权限要配置好,不然会初始化失败:
schematool -dbType mysql -initSchema
元数据
将derby元数据,放进mysql;
在mysql的hivedb中存在很多张表,记录着元数据代表着各种信息:
COLUMNS_V2 # 记录着列的信息
TBLS # 记录着已创建的表名以及创建时间,OWNER...
VERSION # hive版本信息
...