先看下kafka的集群架构:
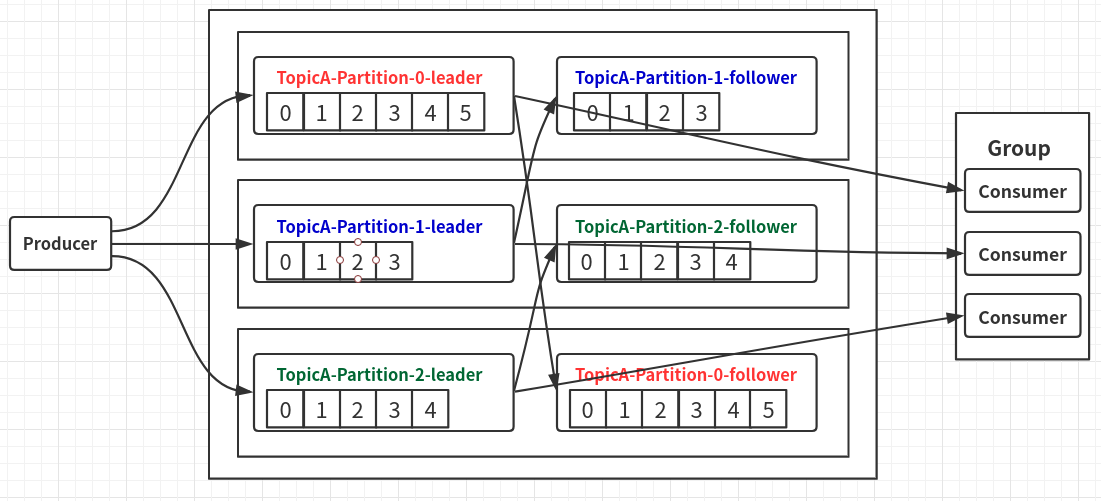
Kafka生产一个Topic,创建了3个分区,每个分区都会先有一个Leader,然后在其他机器中,创建自己分区的follower(副本);
ack应答机制
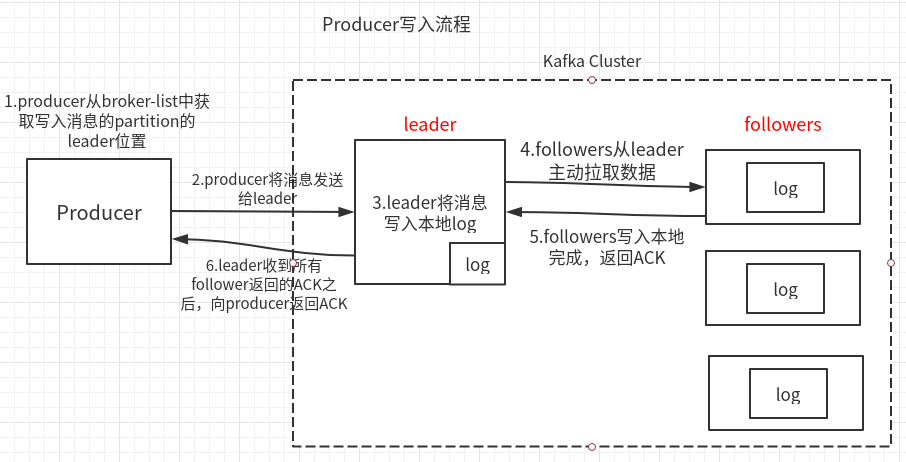
有三个值:
-
0:producer不需要确认消息,直接发送消息给leader,有没有收到消息,producer不管;
上图中去掉5、6步;速度块,安全性最低(当broker故障,会丢失数据)。
-
1:producer发送消息,确保leader写入成功,followers不管;上图中,去掉5步;
(在follower同步成功之前leader故障,就会丢失数据)
-
-1(all):leader和followers全部确认发送到;上图即all机制;
(如果follower同步完成后,leader还没发送ack给Producer的时候,出现了故障,这时候会重新选出一个leader,Producer因为没有收到ack,就会重新发送给新的leader,造成数据重复)
故障维护
下面的场景尺度为一个parition内:
几个概念:
-
LogEndOffset:简称LEO, 代表Partition的最高日志位移,其值对消费者不可见。
-
HighWatermark:简称HW,同一个Partition的所有副本的最小LEO;HW是针对整个Partition而言的。
-
ISRs:in-sync replications,是一个和leader保持同步的follower的集;
当ISR中的follower完成数据的同步之后,leader就会给leader发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR;该时间阈值由replica.lag.time.max.ms参数设定。Leader 发生故障之后,就会从ISR中选举新的leader(只有ISRs中的组员,才有资格当leader)。
注意:
-
消费者只能看到HW之前的数据;
-
数据一致性,只保证数据一致,不保证数据不会重复,或丢失;
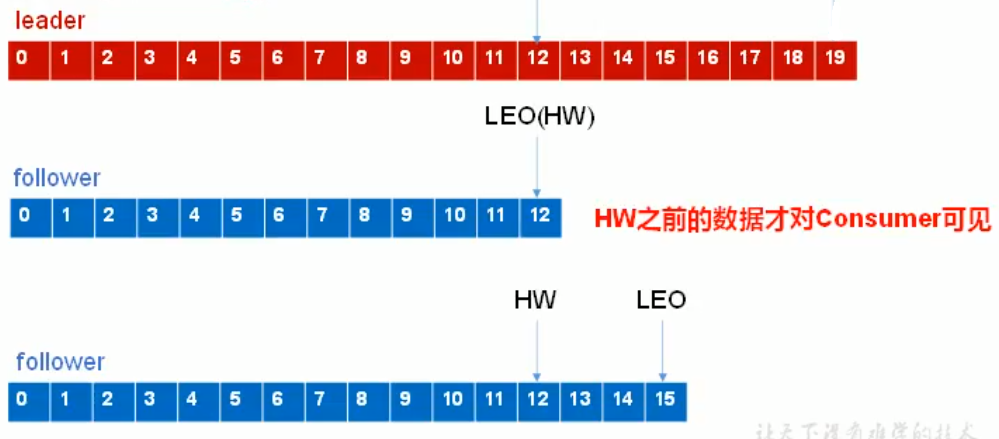
存在这样两种故障,offset会需要维护:
-
follower故障后恢复:
follower故障,会被踢出ISR,恢复后,会读取本地磁盘,恢复故障前的HW之前的数据,然后开始向leader进行同步,一直同步到整个partition的HW,此时消息可认为是追上了leader,就可以重新加入ISR了;
-
leader故障后重新选出leader:
解决:比如leader故障,现在从ISRs中选第二个follower为leader;
那么除了新leader之外的所有follower都将数据截取到HW:这样除了leader外,所有的offset都为HW;
然后follower向leader同步数据;