本人初学python代码不够规范 望见谅
本段代码可以完成对文本信息的分词(标注词性)、去停用词、以及存储到本地TXT文件中
1 # coding:utf-8 2 import re 3 import json 4 import jieba.posseg as pseg 5 import string 6 import datetime 7 import zhon.hanzi 8 import get_comment.SQL 9 10 # 要清洗掉的中文标点 11 ignoring_words = list(zhon.hanzi.punctuation)+list(string.punctuation) 12 # 数据库表中没有存储评论的表名称 13 ignoring_table = ['phone_info', 'phone_url', 'error_table'] 14 15 16 # 将分词后的数据储存到本地 17 def text_save(content, filename, mode='a'): 18 file = open(filename, mode) 19 file.write(str(content)) # 存储为str格式 20 # 此处为存储为json格式 21 # js = json.dumps(content) 22 # file.write(js) 23 file.close() 24 25 26 # 获取数据库中的评论 27 def get_comments(phones_id, i): 28 mysql = get_comment.SQL.save_mysql() # 调用数据库操作 29 comment = mysql.read_comment_phone(phones_id, i) 30 for ob in comment: 31 return str((ob[0])) 32 33 34 # 调用jieba分词包进行分词 35 def jieba_cut(phones_id, i): 36 comment = get_comments(phones_id, i) 37 comments_dict = dict(pseg.cut(comment)) 38 return comments_dict 39 40 41 # 获取数据库中的所有储存评论信息的表名 42 def get_phone_table(): 43 mysql = get_comment.SQL.save_mysql() 44 phone_id_list = list(mysql.select_all_table('jd')) 45 for table in phone_id_list: 46 if table[0] in ignoring_table: 47 phone_id_list.remove(table) 48 phone_id_list.pop() 49 return phone_id_list 50 51 52 # 调用其他函数完成数据的存储,格式为txt 53 def save_file(phone_id1): 54 with open('E:\PythonFile\tingyongci.txt') as ti: 55 ti_list = list(ti.read()) # 获取停用词表(综合哈工大停用词词表) 56 for i in range(1, 1000): 57 with open('E:\PythonFile\tingyongci.txt') as ti: 58 ti_list = list(ti.read()) # 获取停用词表(综合哈工大停用词词表) 59 for i in range(1, 1000): 60 try: 61 new_dic = {} 62 new_dic1 = jieba_cut(phone_id1, i) 63 for key, value in new_dic1.items(): 64 if key not in ti_list: 65 new_dic[key] = value 66 else: 67 pass 68 except: 69 continue 70 print(new_dic) 71 text_save(new_dic, 'E:\PythonFile\jd\phone\%s.txt' % phone_id1) 72 print('----------------------id=%s---------------------------' % phone_id) 73 74 75 if __name__ == "__main__": 76 start_time = datetime.datetime.now() 77 phone_table_lists = get_phone_table() 78 for phone_table_name in phone_table_lists: 79 phone_id = re.sub("D", "", phone_table_name[0]) # 获取表名中的phone_id 80 save_file(int(phone_id)) 81 print("--------------id=%s--------------" % phone_id) 82 end_time = datetime.datetime.now() 83 print('运行时间:') 84 print(end_time - start_time)
附部分运行后的存储结果:
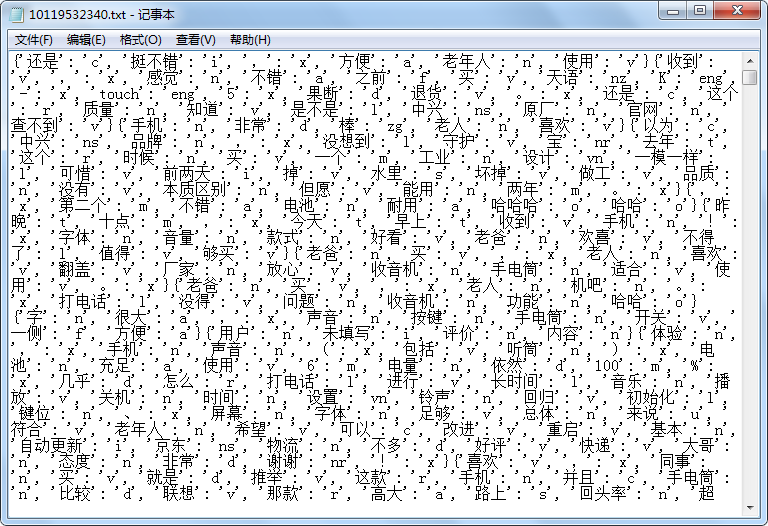
注:jieba分词的词性表如下:
另附词性标注表如下:
1. 名词 (1个一类,7个二类,5个三类)
名词分为以下子类:
n 名词
nr 人名
nr1 汉语姓氏
nr2 汉语名字
nrj 日语人名
nrf 音译人名
ns 地名
nsf 音译地名
nt 机构团体名
nz 其它专名
nl 名词性惯用语
ng 名词性语素
2. 时间词(1个一类,1个二类)
t 时间词
tg 时间词性语素
3. 处所词(1个一类)
s 处所词
4. 方位词(1个一类)
f 方位词
5. 动词(1个一类,9个二类)
v 动词
vd 副动词
vn 名动词
vshi 动词“是”
vyou 动词“有”
vf 趋向动词
vx 形式动词
vi 不及物动词(内动词)
vl 动词性惯用语
vg 动词性语素
6. 形容词(1个一类,4个二类)
a 形容词
ad 副形词
an 名形词
ag 形容词性语素
al 形容词性惯用语
7. 区别词(1个一类,2个二类)
b 区别词
bl 区别词性惯用语
8. 状态词(1个一类)
z 状态词
9. 代词(1个一类,4个二类,6个三类)
r 代词
rr 人称代词
rz 指示代词
rzt 时间指示代词
rzs 处所指示代词
rzv 谓词性指示代词
ry 疑问代词
ryt 时间疑问代词
rys 处所疑问代词
ryv 谓词性疑问代词
rg 代词性语素
10. 数词(1个一类,1个二类)
m 数词
mq 数量词
11. 量词(1个一类,2个二类)
q 量词
qv 动量词
qt 时量词
12. 副词(1个一类)
d 副词
13. 介词(1个一类,2个二类)
p 介词
pba 介词“把”
pbei 介词“被”
14. 连词(1个一类,1个二类)
c 连词
cc 并列连词
15. 助词(1个一类,15个二类)
u 助词
uzhe 着
ule 了 喽
uguo 过
ude1 的 底
ude2 地
ude3 得
usuo 所
udeng 等 等等 云云
uyy 一样 一般 似的 般
udh 的话
uls 来讲 来说 而言 说来
uzhi 之
ulian 连 (“连小学生都会”)
16. 叹词(1个一类)
e 叹词
17. 语气词(1个一类)
y 语气词(delete yg)
18. 拟声词(1个一类)
o 拟声词
19. 前缀(1个一类)
h 前缀
20. 后缀(1个一类)
k 后缀
21. 字符串(1个一类,2个二类)
x 字符串
xx 非语素字
xu 网址URL
22. 标点符号(1个一类,16个二类)
w 标点符号
wkz 左括号,全角:( 〔 [ { 《 【 〖 〈 半角:( [ { <
wky 右括号,全角:) 〕 ] } 》 】 〗 〉 半角: ) ] { >
wyz 左引号,全角:“ ‘ 『
wyy 右引号,全角:” ’ 』
wj 句号,全角:。
ww 问号,全角:? 半角:?
wt 叹号,全角:! 半角:!
wd 逗号,全角:, 半角:,
wf 分号,全角:; 半角: ;
wn 顿号,全角:、
wm 冒号,全角:: 半角: :
ws 省略号,全角:…… …
wp 破折号,全角:—— -- ——- 半角:--- ----
wb 百分号千分号,全角:% ‰ 半角:%
wh 单位符号,全角:¥ $ £ ° ℃ 半角:$