这是本专题的第三节,在这一节我们将以David Silver等人的Natrue论文Mastering the game of Go without human knowledge为基础讲讲AlphaGo Zero的基本框架,力求简洁清晰,具体的算法细节参见原论文。之后我们为AlphaGo家族做一下总结,展望未来AI革命会将我们带向何方,大火的美剧西部世界和强化学习有多少联系。本人水平有限,如有错误还望指正。如需转载,须征得本人同意。
相较AlphaGo的改进
-
只通过自我对局强化学习进行训练学习
-
无需人类大师的数据指引,只需要围棋规则知识
-
简化版蒙特卡洛树搜索,无需RollOut策略
-
将蒙特卡洛树搜索纳入到学习过程中,而不是只用于规划中的动作选择
-
策略网络和价值网络结合为一,最终网络输出为双头,动作概率和值函数
-
使用最先进的残差神经网络
-
轻微改进输入与特征,以适应更多围棋规则
值得注意的是,AlphaGo本身有多个版本,在没有特指的情况下,AlphaGo即指Nature论文里的版本
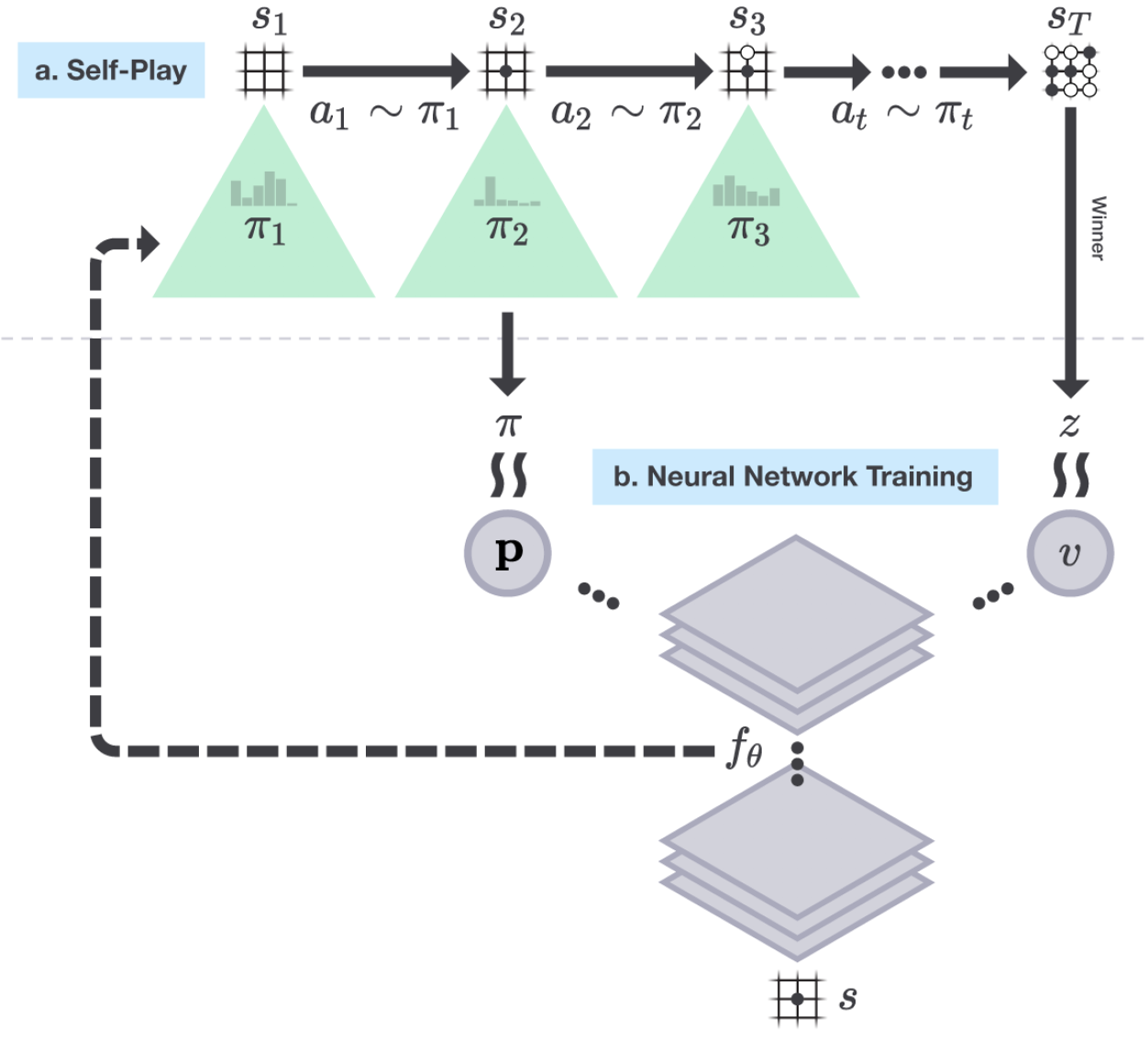
框架
这里的自我对局强化学习采用了通用策略迭代框架。定义蒙特卡洛策略为 (p_{mont}),神经网络输出策略为 (p_{nn})。
-
策略评估:在自我对局中加上搜索树,对每个棋面运用蒙特卡洛搜索,选择落子位置,最终得到奖励作为棋面的评估 (z_T),同时得到策略 (p_{mont}),作为标签导入残差神经网络进行训练。
-
策略提升:将每个棋面输入残差神经网络,输出策略 (p_{nn}) 和估计值 (v) 并导入蒙特卡洛搜索树,策略通过搜索树得到了提升,生成了新的策略 (p_{mont})。
流程
神经网络以随机权重 ( heta_0) 进行初始化,并设为当前最佳的网络 (f_{ heta_*})
(qquad)在每个循环 (i),用当前最佳的网络 (f_{ heta_*}) 进行自我对局
(qquadqquad)在每个时间点 (t),MCTS使用前一次循环的神经网络 (f_{ heta_{i-1}}),依据动作概率进行采样 (pi_t = alpha_{ heta_{i-1}}(s_t))
(qquad)当双方都选择跳过 或 搜索时评估值低于投降线 或 棋盘无地落子,棋局结束,得到相应奖励 (r_T)
(qquad)每个时间点的数据都存储为 ((s_t, pi_t, z_t)),其中 (z_t = pm r_T)
(qquad)从上一局自我对局的棋局中的数据 ((s, pi, z)) 里进行采样,训练神经网络参数 ( heta_i)
(qquad)网络每训练1000步,就用训练出的策略和当前最好的策略 (f_{ heta_*}) 进行400局对战,若胜率大于55%,则选其为当前最佳网络 (f_{ heta_*})
蒙特卡洛搜索树
在此算法中,每个树枝 ((s, a)) 都存储了一系列值:$${P(s, a), N(s, a), W(s, a), Q(s, a)}$$
其中 (P(s, a)) 是先验概率,(W(s, a)) 是总的动作值,(Q(s, a)) 是平均动作值,(N(s, a)) 是访问次数。
蒙特卡洛搜索树总共分成三步执行:
- 选择。从根节点开始基于UCB1算法进行动作选择,直到到达叶结点。
一开始算法会倾向于高先验概率低访问次数的动作,但之后算法会倾向于选择动作值较大的动作。
-
扩展与评估。神经网络在当前叶结点 (s_L) 输出 (P(s, a)) 动作概率向量以及 (v) 值函数。
-
更新。
搜索完成后,算法会按照访问次数生成动作概率
更多细节
神经网络输入的数据为19x19x17的三维数据,棋盘的每个位置由一个17维的二元向量表示,其中前8个特征表示在当前和之前7个棋面中,当前玩家的棋子是否在棋盘的某个位置上,后8个特征表示对手的相应局面,最后一个特征表示当前哪个颜色走子。
AlphaGo Zero自我对局了超过490万局,耗时3天。棋局的每一步都是通过MCTS经过1600次循环所选出,耗时0.4秒。最终以100比0击败了当初和李世石对战的AlphaGo。之后AlphaGo Zero采用更大的神经网络,又重新自我对局了超过2900万局,耗时40天,最终以89比11击败了当初以60比0击败众多人类高手的AlphaGo Master。
AlphaGo家族现实意义
-
热潮与革命。 “彻底”攻破围棋,这是人工智能的又一里程碑。更重要的是,AlphaGo家族通过在现实中多次和人类棋手展开世界瞩目的大战让大众的目光又一次聚焦到了AI上,在互联网时代疯狂炒作的加成下,一波史无前例的AI热潮迅速扫遍世界。我们这一代人有幸见证着AI革命。
-
信心与动力。 AlphaGo Zero集简洁与高效于一身,可谓做到了当前技术上的极致,这让从前棋类的暴力启发式搜索方法显得如此粗糙乏味低效。从一块白板开始学习,只被告知了围棋规则只靠自己摸索就能达到甚至超越人类大师的水平,其围棋走法独辟蹊径一己之力颠覆棋坛几千年的认知。这让大众对于AI有了更多的期望,让学者们有了更大的信心和动力去攻破其它人类智力占据压倒性优势的领域。
-
数据壁垒。 打破数据壁垒,无需任何人工标注数据,从零开始完全依靠自我生成数据并进行标注,放入神经网络进行训练输出策略和值函数。但从另一方面讲,又没有打破数据壁垒,因为训练本身还是建立在千万级数据的基础上,超过了围棋发展几千年棋局的总数,只是在当前计算能力的支持下显得不那么可怕。强化学习对于样本的利用率还是太低了。
-
自我对局。 AlphaGo非常依赖自我对局以求生成数据,一是因为现有原始数据量太小无法有效地训练网络,为了样本的独立性浪费了大量棋局;二是因为左右互搏需要大量试错,一开始都是在随机走子。然而在现实世界中很难有自我对局的机会,比如金融市场就不存在对手,数据量明显不足。
-
特殊场景。 围棋是一种特殊的情景,它是完美信息博弈,所有信息都在棋局上,而且棋局当前的局面是马尔科夫的(不严格的讲),然而现实世界中大多情景是不完美博弈,环境中有大量信息不可知,比如星际争霸里的战争迷雾,状态也很难是马尔科夫的。围棋是可模拟的,我们完全可以下无数局棋,但现实中很多情景不可模拟,比如金融市场,或者搭建模拟器成本很高。围棋的状态动作空间都很小,而且是离散的,奖励是很显然的,然而在星际争霸中状态动作空间就相当的大,奖励过于稀疏。
-
真正的智能。 AlphaGo超强的表现引发了不少人对于强人工智能的担忧,这种担忧目前来看是毫无必要的,因为其局限性上面已经讲了好几点,目前来说都没有被攻破,最乐观的看也需要起码数年的时间。而且在一些学者看来,AlphaGo依旧不能算是真正的所谓智能,因为它的核心依旧是搜索树,只是没那么暴力了,不论是深度神经网络还是强化学习,都只是为了解决树的深度和广度问题。
未来展望
如今,开发出AlphaGo家族的DeepMind团队已经将目光转向了下一个更具挑战性的领域,即时策略游戏,星际争霸。简单地讲,这种游戏的难点在于五方面,一是极其庞大的状态和动作空间,二是战争迷雾所导致的不完美博弈,三是难以设置的奖励信号,四是即时性导致了难以使用搜索法,五是多智能体还有待更多研究。如今距离AlphaGo Zero的发布已经过了一年了,DeepMind坦言在星际争霸上遇到了很多困难,倒是OpenAI发布了它们的Dota AI战报,显示其在5v5模式中击败了业余人类玩家。虽然这是在一堆限制条件之下才得以实现的,但仍然令人感到兴奋,步子总要一步一步走,未来几年之内攻破即时战略游戏显然是很有希望的。
但换个角度想,攻破即时战略游戏足以让人类感到紧张,因为这类游戏不同于围棋之类的棋类游戏,是由大量现实世界的参照的。以红色警戒为例,其兵种,建筑和策略,都是参考了现实世界中盟军和苏联,一旦AI能够攻破红警之类的游戏,这就意味着AI具备了初级的战略决策和指挥能力。如果被军方所利用(这是必然的事情,人类热衷于将最新的技术拿来杀戮同胞)将会造成极其可怕的后果。
此番景象倒是让我们很容易能联想到在美剧世界里的一场人类与AI的大战,即西部世界。在讲之前,我必须要给出剧透警告,因为接下来的内容将涉及大量的第二季剧透,如果你不想被剧透,请就此打住,主体内容已经全部讲完了,接下来只是我自己的一点延伸思考(脑洞)。
************************************ 剧透警告 ************************************
Westworld: Real World AI Playground (quad) 西部世界:现实世界中的AI训练场
先简单介绍一下西部世界的背景,摘自维基百科:
故事设定在未来世界,在一个庞大的高科技成人主题乐园中,有着模拟真人的机器“接待员”能让游客享尽情享受性欲、暴力等欲望的放纵,主要叙述被称为“西部世界”的未来主题公园。它提供给游客杀戮与性欲的满足。
但是在这世界下,各种暗流涌动。部分机器人出现自我觉醒,发现了自己只是作为故事角色的存在,并且想摆脱乐园对其的控制;乐园的管理层害怕乐园的创造者控制着乐园的一切而试图夺其控制权,而乐园创造者则不会善罢甘休并且探寻其伙伴创造者曾经留下的谜团;而买下乐园的一名高管试图重新发现当年的旅程留下的谜团。
在讨论西部世界之前,我觉得非常有必要申明一点,美剧西部世界是有大量bug存在的,没有必要过于抠细节,遇到前后矛盾或者不合理的地方可能不代表你想错了或者没领会到编剧的意图,可能确实是故事上的缺陷。接下来的内容仅代表我的理解,只是脑洞,仅此而已。
西部世界是Delos公司创造的封闭式乐园,所有的Host机器人都打扮成西部世界里的各式人物,各有各的故事线,明面上这个乐园是供人类游客来放纵自我的,但暗地里却大量收集人类游客的数据,企图解码人类,并且希望能通过意识移植实现人类的永生。Host机器人通过与人类游客的交互得到人类的行为数据,便于后期解码。这个西部世界实际上就是一个大型的封闭式强化学习训练基地,这是个多智能体的环境,每个Host机器人都是智能体,其主要的交互是和人类游客以及其他的Host,奖励是其是否沿着故事线行动以及与其交互的人类是否得到欢愉。Host在训练过程中会发现代入感和欢愉是成正相关的,人类游客希望Host足够以假乱真,这就指引着Host的行为越来越贴近真实的人类。
所以西部世界到底在干什么,一言以蔽之,Code Host to Decode Humanity
回忆一下AlphaGo zero的训练过程,我们会发现AlphaGo zero的训练全程都是自己和自己的对局,那么对于Host这样是否是可行的呢?即Host自己与自己进行交流与互动。显然是不行的,因为真实性不够。这就是西部世界里一直在说的Fidelity。强化学习在现实中的应用受限有很大的层面是因为模拟的经验很难贴合真实世界,这意味着一旦我们的策略是从模拟经验中训练得来的,那么在真实世界中依据此策略采取的动作很可能会带来我们非常不愿意看到的后果。既然提到了Fidelity,就不得不提到另一种学习模式,即对抗式学习,这是一种提升Fidelity的强力方法,有些时候我们可能无法实现与真实世界的交互,那时就可以用对抗式学习来训练。对于某个状态,生成模型会生成动作,而判别模型会判定在此状态下的动作是否足够真实。典型的对抗式学习例子当属Dolores训练Bernard,Dolores是由Arnold设计制造的,在Arnold死后,Ford用Arnold的形象制造了Bernard,并且用Dolores去测试其真实性。此时的Dolores便是判别模型,因为她足够熟悉Arnold,可以判断Bernard所说的话是否是Arnold在同样的场景下会说的。

以上都是常态化的西部世界,日复一日,Host通过和人类游客的交互提升自身的Fidelity,游客的帽子会收集游客状态动作数据,在Forge中存储并解码。但是当有的Host开始觉醒,并展开了一场大屠杀之后,一切都变了。此时的Host似乎不再在乎人类游客,可能是游客的欢愉已经不再是奖励信号了,他们不少人依旧是服从着自己的故事线在行动,但是探索Exploration力度加大了,使得Host们出现了很多异常行为,甚至跑进了其它的乐园世界里去。最终,Host们分成了三路,一路肉身消亡意识前往虚拟新世界,一路死在了乐园里等待第三季回收,一路随着Dolores到了人类世界。此时的Host已经具备了足够的Fidelity,足以支持他们在外部的真实世界里做交互。Dolores在临走前还在Forge里看了看人类的编码,这就相当于一个有超强描述能力的特征输入到了Dolores这个本身就很强的智能体之中。众所周知,数据和特征决定了机器学习模型的上限,模型和算法能够逼近这一上限。这意味着Dolores已经无限逼近所谓的上限了,上限是什么?我想上限就是真正完全意义上理解人类这个智能体。不止是单纯的代码,更是行为层面的,最终能够实现对人类行为的预测,控制,甚至是对人类这个物种的毁灭,这就是Dolores的目的。在第三季里我们将会能看到Dolores在人类世界里,在真实开放的人类社会中继续训练自己,在第四季到第八季兴风作浪,人类的毁灭性结局恐难避免,毕竟她已经比所有人类都更了解人类了。
附上我所大致认同的后几季剧情:

参考文献:
[1] Mastering the game of Go without human knowledge. David Silver et al. 2017. https://www.nature.com/articles/nature24270
[2] Reinforcement learning: An introduction 2nd Edition. Richard Sutton. 2018. http://www.incompleteideas.net/book/bookdraft2017nov5.pdf
[3] UCL course on Reinforcement Learning. David Silver. 2015. http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
[4] Deep Reinforcement Learning Doesn't Work Yet. Alex Irpan. 2018. https://www.alexirpan.com/2018/02/14/rl-hard.html
[5] OpenAI Five. 2018. https://blog.openai.com/openai-five/
[6] 深入浅出看懂AlphaGo元. YaoXing Liu. 2017. https://charlesliuyx.github.io/2017/10/18/深入浅出看懂AlphaGo元/#评估器
[7] Westworld reviews on Douban and Zhihu