算法面试-TopK
问题描述:
从arr[1, n]这n个数中,找出最大的k个数,这就是经典的TopK问题。
栗子:
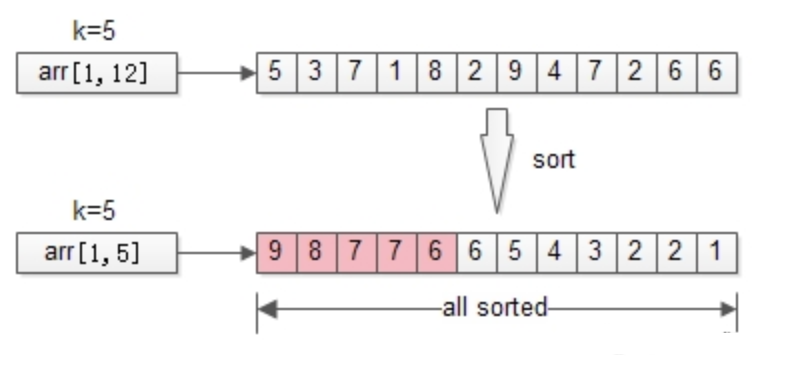
从arr[1, 12]={5,3,7,1,8,2,9,4,7,2,6,6} 这n=12个数中,找出最大的k=5个。
方式一、排序
排序是最容易想到的方法,将n个数排序之后,取出最大的k个,即为所得。
伪代码:
sort(arr, 1, n);
return arr[1, k];
时间复杂度:O(n*lg(n))
分析:明明只需要TopK,却将全局都排序了,这也是这个方法复杂度非常高的原因。那能不能不全局排序,而只局部排序呢?这就引出了第二个优化方法。
方式二、局部排序
不再全局排序,只对最大的k个排序。
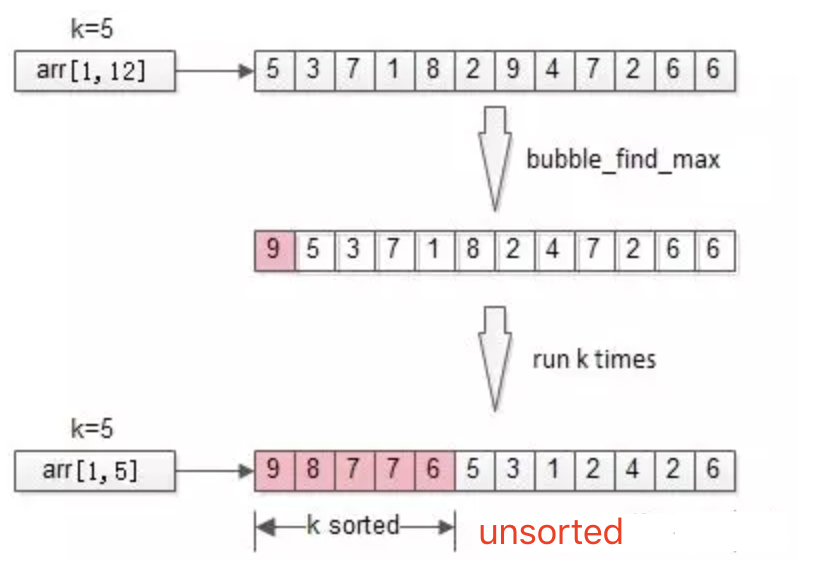
冒泡是一个很常见的排序方法,每冒一个泡,找出最大值,冒k个泡,就得到TopK。
伪代码:
for(i=1 to k){
bubble_find_max(arr,i);
}
return arr[1, k];
时间复杂度:O(n*k)
分析:冒泡,将全局排序优化为了局部排序,非TopK的元素是不需要排序的,节省了计算资源。不少朋友会想到,需求是TopK,是不是这最大的k个元素也不需要排序呢?这就引出了第三个优化方法。
方式三、堆
思路:只找到TopK,不排序TopK。
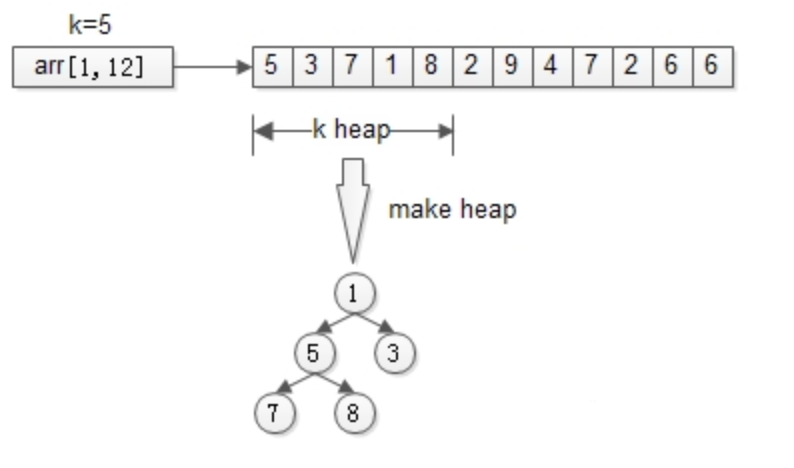
先用前k个元素生成一个小顶堆,这个小顶堆用于存储,当前最大的k个元素。
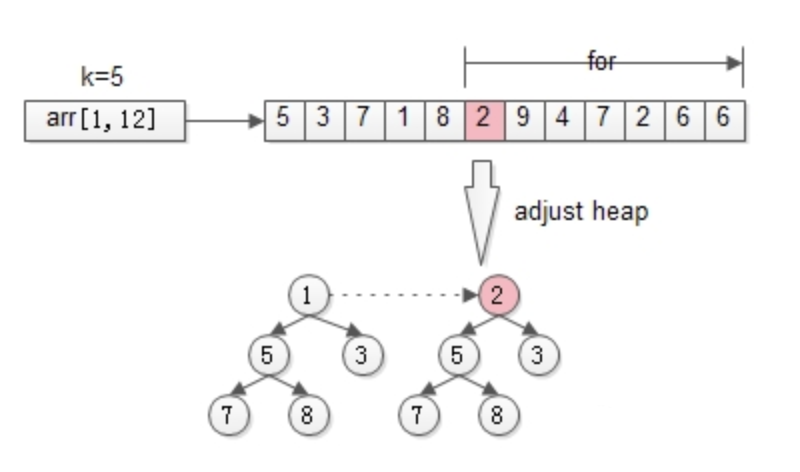
接着,从第k+1个元素开始扫描,和堆顶(堆中最小的元素)比较,如果被扫描的元素大于堆顶,则替换堆顶的元素,并调整堆,以保证堆内的k个元素,总是当前最大的k个元素。
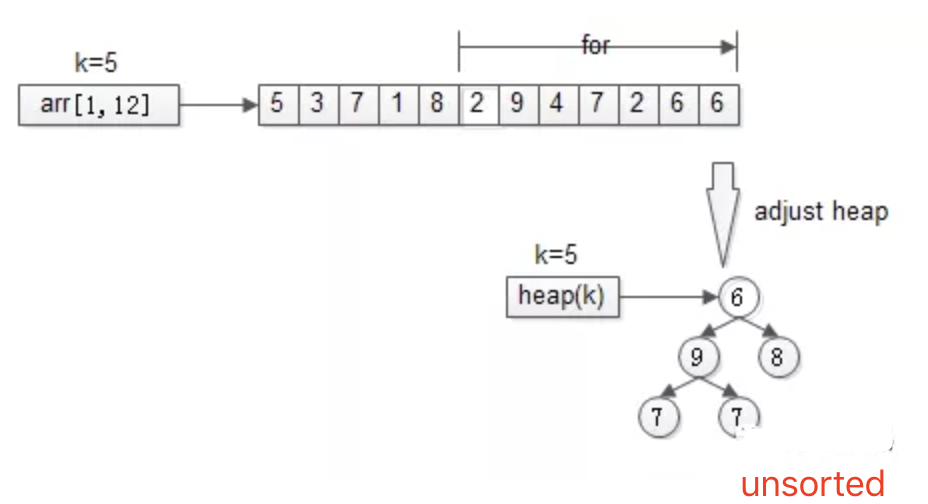
直到,扫描完所有n-k个元素,最终堆中的k个元素,就是我们求的TopK。
伪代码:
heap[k] = make_heap(arr[1, k]);
for(i=k+1 to n){
adjust_heap(heep[k],arr[i]);
}
return heap[k];
时间复杂度:O(n*lg(k))
画外音:n个元素扫一遍,假设运气很差,每次都入堆调整,调整时间复杂度为堆的高度,即lg(k),故整体时间复杂度是n*lg(k)。
分析:堆,将冒泡的TopK排序优化为了TopK不排序,节省了计算资源。堆,是求TopK的经典算法,那还有没有更快的方案呢?