转自:https://www.cnblogs.com/lmq3321/p/10320671.html
一、 ProGuard简介
因为Java代码是非常容易反编码的,况且Android开发的应用程序是用Java代码写的,为了很好的保护Java源代码,我们需要对编译好后的class文件进行混淆。
ProGuard是一个混淆代码的开源项目,它的主要作用是混淆代码,殊不知ProGuard还包括以下4个功能。
- 压缩(Shrink):检测并移除代码中无用的类、字段、方法和特性(Attribute)。
- 优化(Optimize):对字节码进行优化,移除无用的指令。
- 混淆(Obfuscate):使用a,b,c,d这样简短而无意义的名称,对类、字段和方法进行重命名。
- 预检(Preveirfy):在Java平台上对处理后的代码进行预检,确保加载的class文件是可执行的。
总而言之,根据官网的翻译:Proguard是一个Java类文件压缩器、优化器、混淆器、预校验器。压缩环节会检测以及移除没有用到的类、字段、方法以及属性。优化环节会分析以及优化方法的字节码。混淆环节会用无意义的短变量去重命名类、变量、方法。这些步骤让代码更精简,更高效,也更难被逆向(破解)。
ProGuard工作原理
ProGuar由shrink、optimize、obfuscate和preveirfy四个步骤组成,每个步骤都是可选的,我们可以通过配置脚本来决定执行其中的哪几个步骤。
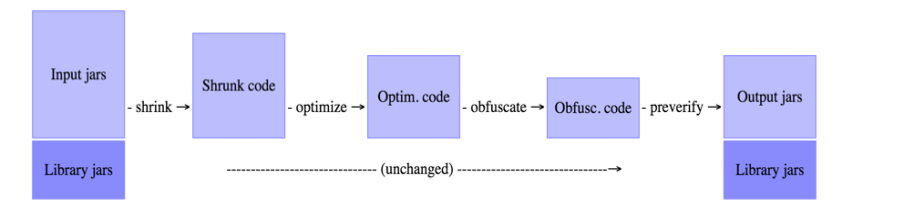
混淆就是移除没有用到的代码,然后对代码里面的类、变量、方法重命名为人可读性很差的简短名字。
那么有一个问题,ProGuard怎么知道这个代码没有被用到呢?
这里引入一个Entry Point(入口点)概念,Entry Point是在ProGuard过程中不会被处理的类或方法。在压缩的步骤中,ProGuard会从上述的Entry Point开始递归遍历,搜索哪些类和类的成员在使用,对于没有被使用的类和类的成员,就会在压缩段丢弃,在接下来的优化过程中,那些非Entry Point的类、方法都会被设置为private、static或final,不使用的参数会被移除,此外,有些方法会被标记为内联的,在混淆的步骤中,ProGuard会对非Entry Point的类和方法进行重命名。
二、proGuard基本使用之UI界面操作
1.去proGuard 官网下载地址下载并解压proguard,执行 bin目录下的proguardgui.bat 如下图。
2.启动后如下图所示,我们重按展示顺序一步一步向下走ProGuard。
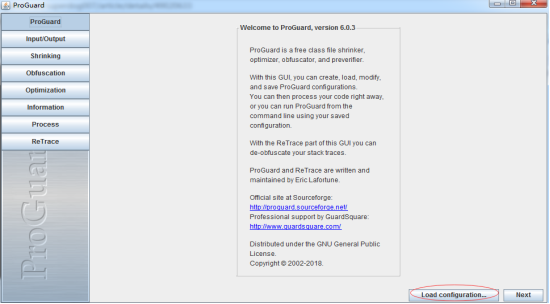
注:红色圈内为加载配置文件按钮.官方推介”myconfig.pro”文件格式,其他博客写的配置文件都为xxx.cfg格式.在没有配置文件下可不做此操作。
3.Input/Output展示如下图。
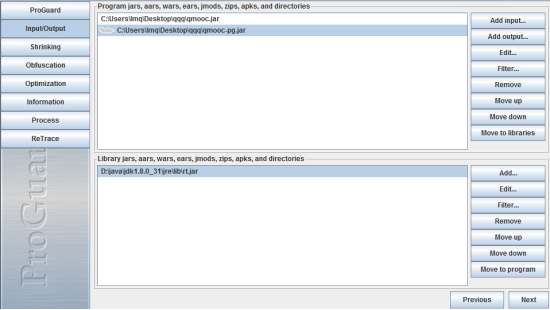
注:工具很强大,可以导入各种的包如(jar,war,ears,zips)等格式的进行操作。由于对其他格式的文件操作不熟不知会产生什么莫名错误。所以就以jar文件做为例子.
Add input:导入需要操作的文件。
Add Outinput: 需要输入的文件。
Filter: 过滤导入文件内那些不需要操作的文件。
Add an enty:添加支持库library jars. 对添加的项目支持 jar文件或者其他文件不会进行处理。
3.shrinking如下图。
注:proGuard的压缩属性。删除无效的代码(未研究)
4.Obfuscation 代码混淆的主要配置如下图
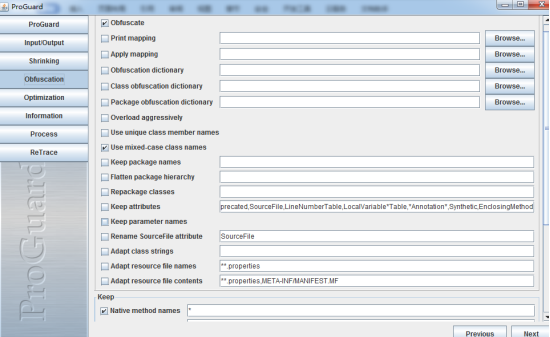
注:勾选中为需要做什么什么操作。
1. obfuscate 代码混淆
2. Print Mapping 输出映射文件即混淆后与混淆前的映射
3. Apply mapping 应用映射文件
4. Obfuscation dictionary 自定义混淆的类名,方法名,变量名字典,替换原先的a,b,c.这中格式的
5. Class Obfuscation dictionary
6. Package Obfuscation dictionary
7. Overload aggressively 混淆的时候大量使用重载,减小包体积,增加理解难度
8. User unique clssmember names 指定相同的混淆名对应相同的方法名
9. User mixed-case class names 指定在混淆的时候使用大小写混用的类名
10. Keep package names 声明不混淆指定的包名
11. Flatten package hierarchy 所有重新命名的包都重新打包
12. Repackage Classes 所有重新命名过的类都重新打包
13. Keep attributes 指定受保护的属性
14. Keep parameter names 指定被保护的方法的参数类型和参数名不被混淆
15. Rename sourceFile attribute 指定一个字符串常量设置到源文件的类的属性中
16. Adapt class strings 指定字符串常量如果与类名相同,也需要被混淆
17. Adapt resource file names 如果资源文件与某类名同,那么混淆后资源文件被命名为与之对应的类的混淆名
18. Adapt resource file names 指定资源文件的中的类名随混淆后的名字更新
ADD 操作 添加自定义的一些文件不被混淆 使用通配符的形式进行匹配
5.Optimization 代码优化 如下图
6.Information 如下图 一些输出或后台执行信息的配置 默认就好
8.Process 执行操作界面 包含查看配置文件,保存配置文件和执行按钮操作

三、 Maven项目配置ProGuard
- maven集成proguard .pom文件配置方式有三种放在。
- 利用注解的方式在需要的混淆的文件中给上相应的注解。
- 直接以<option><option> 的方式编辑相应参数配置
- 加载配置文件的形式 .pro文件或.cfg 文件
- 配置文件模板.可参考附带项目列子 .pom 文件
- 注:proguard并没有提供直接打成war的方式。一般情况都市生成jar包并把jar包做混淆,之后替换原有的class文件。
四、 ProGuard一些注意事项
a. 反射使用。比如 setName() 方法通过混淆被映射为了 a() 如果我们希望通过方法名 setName 来调用类中的该方法,在写代码的时候,我们也不会知道这个名字将会被映射为 a ,混淆之后,会找不到方法的。 混淆使得方法名发生改变,而我们还在使用原来的方法名进行反射。
b. bean 文件使用。对于 bean 文件,很多时候,它们作为和服务器之间的通信实体。如果在这种情况下进行了混淆,当数据发给服务器之后,服务器是看不懂的,因为属性名都变了,而服务端保存的是原来的 bean 文件(序列化问题,json问题)。
c. 回调函数。这是一个值得注意的地方。比如在 Activity 中的 onTouchEvent 回调,如果被你混淆了,而系统实际上不知道的,混淆是你的个人行为。它不会知道到该回调的,同样因为找不到。
d. 枚举。在使用枚举类型的时候,应当注意不要对它们进行混淆。因为枚举会使用反射进行操作。
e. native 方法不要混淆。
f. 内嵌类经常会被混淆,结果在调用的时候为空就崩溃了。(开发尽量避免内嵌类)
# 保留内嵌类不被混淆 列:-keep class com.example.xxx.MainActivity$* { *; }
详细请查考附件:proGuard-example