学习于林子雨《大数据技术原理与应用》教材配套大数据软件安装和编程实践指南
一. 安装spark
第一步,spark下载(http://spark.apache.org/downloads.html)
第二步,spark压缩包解压
sudo tar -zxf ~/下载/spark-1.6.2-bin-without-hadoop.tgz -C /usr/local/
第三步,解压后文件夹改名为spark
- cd /usr/local
- sudo mv ./spark-1.6.2-bin-without-hadoop/ ./spark
第四步,赋予权限
sudo chown -R hadoop:hadoop ./spark
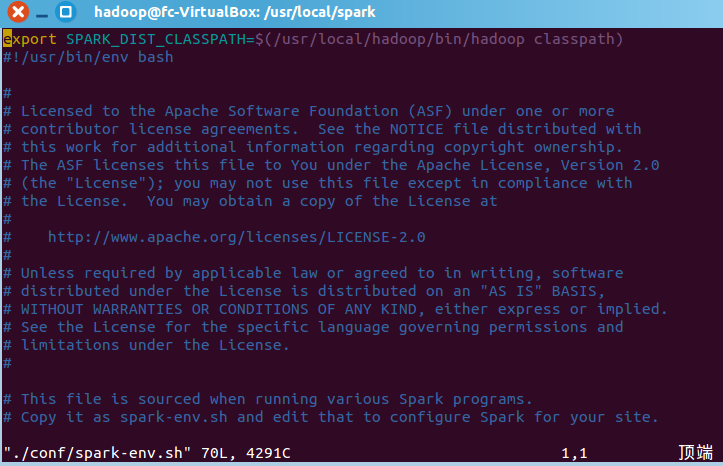
第五步,安装后,还需要修改Spark的配置文件spark-env.sh
- cd /usr/local/spark
- cp ./conf/spark-env.sh.template ./conf/spark-env.sh
- vim ./conf/spark-env.sh
- 按i进入编辑模式,第一行插入export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath),如图:
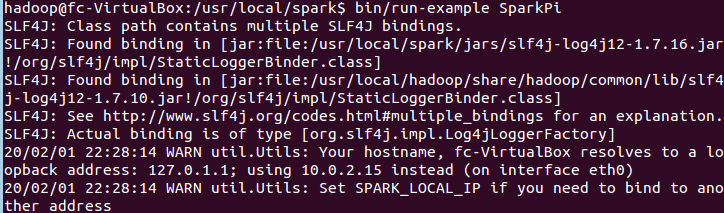
第六步,测试
- cd /usr/local/spark
- bin/run-example SparkPi
- 结果应为,如图:
 ,还有很多信息,这里只截了这么多,但可使用命令bin/run-example SparkPi 2>&1 | grep "Pi is",进行过滤,得到结果如图:
,还有很多信息,这里只截了这么多,但可使用命令bin/run-example SparkPi 2>&1 | grep "Pi is",进行过滤,得到结果如图:
就算安装成功了。
二.使用 Spark Shell 编写代码
第一步,启动spark shell
bin/spark-shell
成功后如图: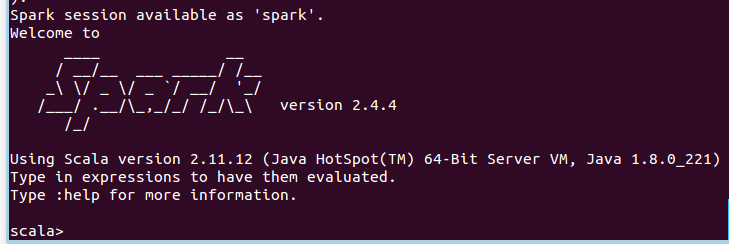
第二步,加载text文件
val textFile = sc.textFile("file:///usr/local/spark/README.md")
如图:
第三步,简单RDD操作
- textFile.first()//获取RDD文件textFile的第一行内容

- textFile.count()//获取RDD文件textFile所有项的计数

- val lineWithSpark = textFile.filter(line => line.contains("Spark"))//抽取含有“Spark”的行,返回一个新的RDD

- lineWithSpark.count()//统计新的RDD的行数

- textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)//找出文本中每行的最多单词数(组合操作)

第四步,退出Spark Shell
:quit