今天完成了所有的任务,结束了练习三。
今天主要完成了对数据的爬取,需要注意的是,这次爬取第一次遇到了限制代码端,所以我通过伪装,才爬取到了数据,通过测试,也修改了前面程序的bug,接下来直接上代码:
import requests import pymysql #导入requests包 from lxml import etree def paqu(): url = 'https://baike.baidu.com/item/国民经济行业分类/1640176?fr=aladdin' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',} strhtml = requests.get(url, headers=headers) #Get方式获取网页数据 strhtml.encoding ='utf-8' selector = etree.HTML(strhtml.text) menlei="" for i in range(3,1462): str1="/html/body/div[3]/div[2]/div/div[2]/table/tr["+str(i)+"]/td[1]/div/b" content=selector.xpath(str1) if(len(content)>0): if(content[0].text!=" " and content[0].text!="" and content[0].text!=None): menlei=content[0].text str1= "/html/body/div[3]/div[2]/div/div[2]/table/tr[" + str(i) + "]/td[2]/div/b" content = selector.xpath(str1) if(len(content)>0): if(content[0].text!=" " and content[0].text!="" and content[0].text!=None): xiaolei=content[0].text str1 = "/html/body/div[3]/div[2]/div/div[2]/table/tr[" + str(i) + "]/td[5]/div/b" content = selector.xpath(str1) if (len(content) > 0): if (content[0].text!= " " and content[0].text != "" and content[0].text != None): name=content[0].text print(str(i)+" "+menlei+xiaolei+" "+name) tianjia(menlei+xiaolei,name) print("添加成功") def tianjia(id,name): global db cur = db.cursor() sql_add ="INSERT INTO hangye (id,name) VALUES ('"+id+"', '"+name+"')" try: cur.execute(sql_add) # 执行sql # 提交 db.commit() except Exception as e: # 错误回滚 print("错误信息:%s" % str(e)) db.rollback() # finally: # db.close() if __name__ == '__main__': db = pymysql.connect(host='localhost', port=3306, user='root', passwd='', db='', charset='utf8') cur = db.cursor() try: cur.execute("truncate table hangye") # 执行sql # 提交 db.commit() except Exception as e: # 错误回滚 print("错误信息:%s" % str(e)) db.rollback() paqu(); db.close();
前面程序的bug我已经在上一次的博客中修改了,这里就不贴了。
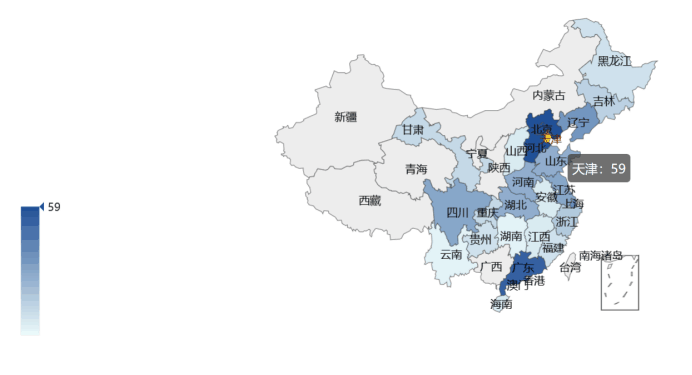
然后用echarts完成了可视化,接下来直接贴结果图: